
Moving AI from interactive chatbots to autonomous “ambient” agents requires a fundamental shift in system architecture. This article examines the technical implementation of agents that operate asynchronously within an enterprise environment. We detail a practical AgentOps lifecycle for Red Hat OpenShift, covering the design of event-driven logic, the use of Custom Resource Definitions (CRDs) for native deployment, and the observability patterns required to govern autonomous systems.
Constantly prompting an AI for repetitive tasks is a burden. What if AI systems could work for you autonomously? An agentic system capable of autonomous task execution in the user’s absence would be highly beneficial. Consider a scenario where, upon returning to work, one discovers pre-drafted pull requests for overnight issues, a comprehensive incident report detailing the problem, its resolution, and proactive preventative measures, alongside a concise email for repository administrators summarizing the past week’s events.
Instead of waiting for a human prompt, these agents continuously watch the environment and act when something changes. They stay securely connected, scale up or down with demand, and know when to bring in a human or roll back to the last successful step checkpoint (i.e. a snapshot of agent’s state within a workflow) if something looks off. The components to make this happen already exist, we just need to put the pieces together.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
But how do we build something like this? What needs to be considered to make it happen? And are there already tools or projects in the market we can lean on?
As the emerging tech team at OCTO, we’ve been digging into these exact questions. Through investigations, prototypes, and lessons learned, we’re exploring what it takes to move from today’s AI experiments to tomorrow’s cloud native ambient agents. This post is the first in a series where we’ll share that journey.
In this first post, we’ll start by walking you through:
- A high-level vision of Agent Operations (AgentOps) lifecycle, including the key considerations from development through deployment and ongoing operations.
- How the overall conceptual architecture can be designed, and which existing open source projects are already moving in this direction
- The real-world impact these systems can have in enterprise settings
Let’s dive in.
The development phase: Architecting an ambient agent
Transitioning from a proof-of-concept to an enterprise-grade agent begins with defining a high-value use case that addresses a specific operational pain point. With the goal set, the next step is selecting an agentic framework, such as LlamaStack, AutoGen, CrewAI, or LangGraph. These frameworks abstract the complexity of wiring LLMs to infrastructure, allowing engineers to focus on business logic. At this stage, we also determine if a single agent suffices or if the problem requires a coordinated multi-agent team. If opting for a multi-agent approach, implementing a standardized Agent-to-Agent (A2A) protocol is essential. This defines a shared language that allows agents to negotiate tasks, share context, and hand off work reliably, driving interoperability regardless of the underlying models or frameworks utilized.
Once the architecture is defined, agents must be empowered by configuring their core attributes:
- Inference models act as the “brain” for reasoning.
- Memory systems provide context recall and adaptive learning across iterations.
- Tools grant them the agency to execute actions within their environment.
To support autonomous behavior, we can then look beyond standard request-response patterns. While agents utilize standard REST or gRPC interfaces for direct user requests or synchronous A2A coordination,subscribing to asynchronous events offers a robust alternative. This allows them to continuously monitor their environment and act on changes without explicit human invocation.
To enable this continuous reactivity, we rely on streaming platforms like Apache Kafka to create a durable, scalable event backbone. On Red Hat OpenShift, Red Hat AMQ Streams (Kafka Operator) provides the Kubernetes-native primitives to provision and monitor these streams. This setup helps agents stay securely connected to the pulse of the enterprise, automatically scaling up to handle event surges and scaling down during quiet periods. With these core components and communication patterns defined, the challenge shifts to making the system live reliably in a production environment—the deployment phase.
The deployment phase: Take an agent from code to a live, running entity
For agents to move beyond prototypes, we believe they should be treated like other cloud-native components: containerized, observable, and managed through existing infrastructure. This approach allows us to leverage the benefits of cloud-native architectures, such as scalability and resilience, without inventing new standards, facilitating the introduction of intelligent components into enterprise systems.
To operationalize this, our architectural vision focuses on representing agents directly as Custom Resource Definitions (CRDs).
While standard Kubernetes primitives, like Deployments for workloads, Services for networking, and ConfigMaps for improving configuration security, provide the necessary foundation, managing them individually for every agent can become complex. By defining agents as CRDs, the goal is to abstract this complexity. In this model, an Operator orchestrates these underlying primitives, encoding operational knowledge directly into the platform.
This structure is designed to automate tasks like updates, scaling, and recovery, allowing AI engineers and cloud administrators to focus on improving agent intelligence rather than performing manual maintenance. A UI dashboard can then interface with these CRDs to provide a single pane for setup and monitoring. This aims to give teams visibility into agent health, discovery, and lifecycle management, helping them understand which agents are running and how they connect.
By the end of this phase, the objective is to have an agent that functions not just as a prototype, but as an operational component within the cloud-native ecosystem, prepared for real-world workloads.
The operations phase: Delivering agents that Work reliably
Once agents are live, the focus shifts to operations. In an enterprise environment, synchronous and asynchronous agents must be continuously available and reliable, and adhere to enterprise secure policies. We categorize operations into three essential pillars:
1. Observability & feedback loops
In autonomous systems, observability must go beyond uptime, it must make reasoning transparent. Operators need to trace how an event triggers a thought, how that thought triggers an action, and the downstream impact.
- Agent Reasoning (e.g., OpenLLMetry): Capture structured logs of LLM calls, memory lookups, and tool invocations to understand the “why” behind decisions.
- System Health (e.g., OpenTelemetry): Monitor the event backbone, queue depth, delivery lag, and throughput to verify that the messaging layer doesn’t bottleneck agent performance.
- Security & Debugging (e.g., OpenTelemetry): Track authentication events and anomalous behaviors for security, while providing verbose traces during development to troubleshoot logic before production rollout.
This visibility enables you to trace decisions to their source, identify bottlenecks, and use the data to continuously refine prompts, models, and system security.
2. Agent gateways: Governing the flow of agent traffic
Agents continuously communicate with each other, tools, and external services. An Agent Gateway acts as the central control plane to govern and enhance the security posture of these complex interactions.
- Unified traffic control: Serves as a central point for agent-to-agent and agent-to-tool policies for more consistent rules across the mesh.
- Identity & Security: Enforces authentication (e.g. mTLS, tokens) to confirm that only authorized actors can send or receive data.
- Governance: Provides a single location to enforce rate limits, mask sensitive credentials, filter content, and log traffic for compliance.
The gateway extends the overall security footprint of the system by enforcing a boundary against unauthorized interactions. It applies uniform guardrails, like throttling and credential masking, and makes every autonomous action fully traceable and auditable.
3. Agent identity: Establishing trust in autonomous systems
Gateways enforce rules, but Identity verifies trust. Because agents spin up dynamically, they require verifiable, short-lived identities rather than static credentials.
- Scoped, Short-Lived Identities: Frameworks like SPIFFE/SPIRE automatically issue and rotate short-lived certificates bound to a specific task, helping to prevent credential sprawl.
- Zero Trust Authentication: Every interaction is verified via cryptographic mechanisms (like mTLS), making it so that no agent acts anonymously.
- Auditability: Tools like Red Hat build of Keycloak centralize identity management, allowing every autonomous action to be traced back to a specific, federated identity for full audit compliance.
Ultimately, strong identity turns agents into trusted actors. It enables autonomous authentication, enforces Zero Trust accountability by making every action traceable, and delivers more secure interoperability across complex, distributed environments.
Architecture Diagram
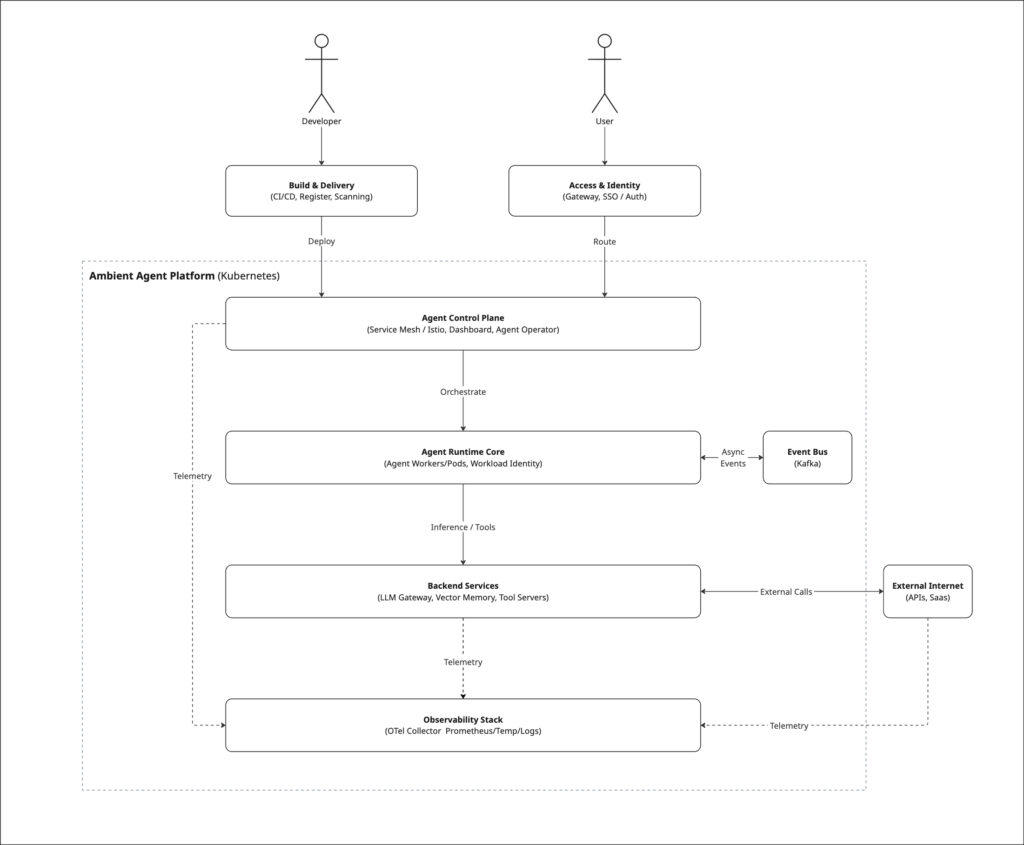
Conclusion
By outlining this development and operational lifecycle, we have established a baseline for building AI agents that are not just autonomous, but governable. Applying cloud-native principles, from event streams to observability, offers a structured way to navigate the complexity of these systems. In our next series of posts, we will dive deeper into the specifics of architecture, deployment, and operations. We will then bring these concepts together to demonstrate live deployments, testing this framework against real-world use cases.