A number of multi-cloud orchestrators have promised to simplify deploying hundreds or thousands of high-availability services. But this comes with massive infrastructure requirements. How could we possibly manage the storage needs of a thousand stateful processes? In this blog, we’ll examine how we can leverage these orchestrators to address our dynamic storage requirements.
Currently in Kubernetes, there are two approaches in how a control plane can scale resources across multiple clusters. These are commonly referred to as the Push and Pull models, referring to the way in which configurations are ingested by a managed cluster. Despite being antonyms in name, these models are not mutually exclusive and may be deployed together to target separate problem spaces in a managed multi-cluster environment.
In the previous blog, we touched on the capabilities of KubeFed as a multi-cluster control plane. Via federation configs – a wrapper around a Kubernetes primitive – workloads can be scaled across a set of managed clusters from a single point of control. An Operator running in a managed cluster responds to federated configs by creating the wrapped resource (e.g.
a Deployment, StorageClass, StatefulSet, etc.) in a set of remote clusters. Thus, KubeFed follows the Push paradigm of multi-cluster management.
As a management tool, KubeFed’s value lies in its ad hoc approach to workload scaling and allowance for a fine-tuned control over individual cluster resources. By design, it does not incorporate common aspects of the lifecycle management of the objects it scales. Updates and rollbacks are not supported, nor are the federated configs versioned. However, these gaps can be filled in by combining KubeFed with the Operator Lifecycle Manager(OLM), a component of the Operator Framework.
Combining KubeFed with the OLM means that instead of scaling a workload directly, we’re going to scale the OLM Subscription (a custom resource definition) for that workload. This model assumes an OLM operator is deployed on each cluster. Effectively, by scaling OLM Subscriptions, we signal to each OLM operator our desired state for the subscribed workload. The OLM fulfills that request by installing the workload or rolling its version to match what we define in the Subscription.

So that’s an example implementation of a Push approach to multi-cluster management. The control plane operates out of a master cluster and sends configurations to client clusters to scale out workloads. Next up, the Pull model.
Largely derived from the “Configuration as Code” model, this alternative multi-cluster approach uses a Git workflow to drive workloads at scale. Dubbed GitOps, this pattern uses a Git repository to house the configurations for all scaled workloads and becomes the source of truth for each cluster. An operator, deployed in each cluster, continually monitors the Git repo for changes to configs and compares them against the local versions. Whenever a difference occurs, the Operator works to bring the cluster inline with the new configs.
GitOps provides a few notable benefits as the number of clusters scale up. Most obviously, Git provides a well-established versioning system that allows for changes to be rolled forwards or backwards. Git history allows for quick look-backs through changes of a configuration over time. The pull request workflow is manageable and second nature to developers and admins.
Additionally, the distributed nature of the control plane, wherein each cluster monitors Git separately, means that there is no master cluster constituting a single point of failure. This adds to the stability of the overall pattern and provides a more automated approach to scaling workloads. Architectures with thousands of clusters (edge computing, hybrid or multi-cloud solutions) benefit significantly from a highly-automated scaled deployment pattern.
In contrast to the Push model, GitOps can automate the scaling process to a near limitless number of clusters. The cost of this is a lack of fine-tuned control over the workloads themselves. The cluster environments are expected to be more or less homogeneous with very little deviation in the underlying computing and storage capacity. KubeFed instead provides a detailed API to wrap the workload configurations. With it, users can specify which clusters a workload should deploy on and the storage that workload requires. KubeFed allows for these customizations to be targeted on a per-cluster basis. Via KubeFed’s API, configurations may vary from cluster to cluster, allowing for a more tailored approach to workload scaling. It’s in these differences that GitOps and Kubefed (plus OLM) may work as complementary components of a user’s multicluster toolbox.
Scale your storage configuration with your workloads
Let’s dig into the first storage pattern from the previous blog: using existing cluster storage capabilities while federating an application workload. Since we’re not moving any data around, this is the simplest storage use case.
The goal here is to ensure that as we scale our workloads, their storage requirements scale with them in a controlled and predictable manner. Kubernetes’ StorageClass provides us this means of control for single clusters so it makes sense that it’s our prime candidate for scale. How we use this resource to achieve our goal differs between the management models.
Push
In this scenario, let’s assume we have two clusters: a Host cluster and a Member cluster. As defined by Kubefed, the Host cluster houses the KubeFed control plane and the Federated API resources. Member clusters receive the Federated API types from the Host cluster via the push model. KubeFed allows for the Host to also act as a Member, however for simplicity we’ll assume they are distinct from one another.
Using the Default Storage Class
In many cases, it may be desirable for workloads to rely on every cluster’s default storage option. There are several benefits to this flexibility. As applications scale across clouds, they will be attached to the default storage for that cloud provider. Run on AWS, a pod would have EBS volumes attached; on GKE, it would be given GCP Persistent Disks. Additionally, the storage for each instance of the application would be geographically close to the machine on which the application is running. Let’s look at how we can enable this feature.
- We’ll define our PersistentVolumeClaim (PVC) without a StorageClassName. This will signal to Kubernetes to assume the default storage option.
- Next, we generate the federated version of the PVC using the kubefedctl CLI tool:

- We then create the federated PVC, along with the rest of the workload’s federated resources (namespace and deployment) in our Host cluster. KubeFed will propagate these configs out to member clusters defined under the placement stanza. On these clusters, the storage controller will provision a volume and attach it to a pod managed by the deployment:
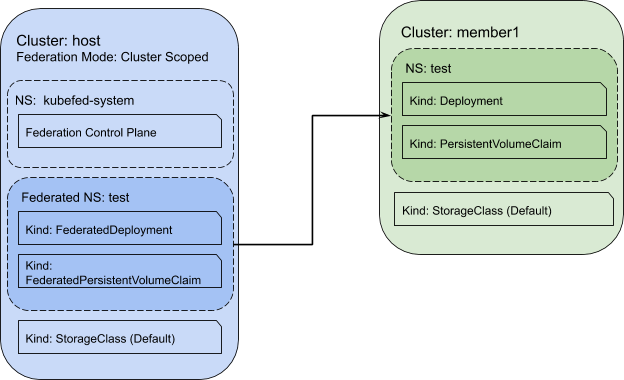
Customizing a Federated Storage Class
In cases where an application has specific storage requirements, it’s useful to scale the storage configuration simultaneously with the workload. This assumes that a non-default StorageClass is necessary and that one storage provisioner is running on each cluster. To accomplish this, we simply append a FederatedStorageClass to our configuration. The federation control plane will distribute the StorageClass to each Member cluster where the local provisioners (not shown) will ingest the parameters defined within:

Pull
Now let’s examine how GitOps can help solve the problem of meeting simple storage requirements at scale. As we explained above, this topology differs from the Push model’s control plane significantly. Each cluster is managed internally by an instance of a GitOps operator. These operators continuously watch a repository containing workload configurations and compares each config against those stored in its API server. Once it detects a difference, it reconciles its host cluster with the remote config.
Using the default Storage Class
GitOps benefits equally compared to Federation when making use of default Storage Classes. Particularly because of the lack of customization that the system provides. However, the method for scaling a workload’s storage requirement is somewhat simplified.
- A workload configuration containing a Namespace, Deployment, and PVC are merged into the main code line via a Pull Request. As before, the PVC defines the Storage Class as “” to signal for the default StorageClass.
- Each Pull Reconciler independently polls the repository and detects the change. The reconciler then works to synchronize its cluster with the new configs. It creates the Namespace, Deployment, and PVC.
- The cluster’s provisioner creates a storage volume respective of that cluster’s cloud provider and attaches it to the Deployment’s pod:
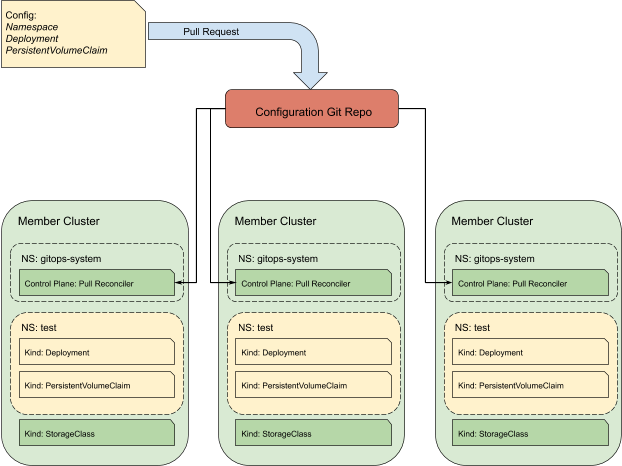
Customizing a Storage Class
To distribute a custom Storage Class, each cluster must be running an instance of the provisioner for which the Storage Class applies. This custom resource is simply bundled with the cluster config and merged into the Git repository as before:

The wrap up
We’ve covered what it looks like to scale some basic storage requirements with our workloads under both Push and Pull models. So far, our examples have covered only the simplest use case without consideration for existing data. In the next blog, we’ll touch on what it looks like to manage data under these models at scale and how the Rook project can help with the transferring and mirroring of data to grow with our workloads.