As a cloud user, how do you avoid the pull of data gravity of one provider or another? How can you get the flexibility and tooling to migrate your infrastructure and applications as your needs change? How do you get to the future of storage federation as data agility?
In this blog we cover the primary motivations and considerations that drive the enablement of flexible, scalable, and agile data management. Our subsequent blogs cover practical use cases and concrete solutions for our 6 federated storage patterns.
All of this is grounded in Red Hat’s work to take a lead in multi-cluster enablement and hybrid cloud capabilities. Our work is focused on leading and moving forward projects that lay the groundwork for this vision in OpenShift, driven via the Kubernetes project KubeFed.
What does KubeFed solve?
Beyond supporting multiple clouds or multiple clusters at once, KubeFed provides the ability to have a consistent API across public and private clouds and enables these clusters to communicate and share resources such as storage. When approaching this problem at scale the API becomes the key.
Modern administrators may be tasked with managing multiple clusters in multiple clouds and regions with multiple configurations:

Diagram showing Cluster A and Cluster B in different clouds and/or regions, each with multiple configurations
Application resources must be managed manually across these hybrid cloud deployments. You can see as we scale out our deployments this quickly becomes untenable:

Example stand-alone configs for N applications on each cluster
As members and leaders in the multi-cluster SIG in Kubernetes, Red Hat has been in from the start to formulate and articulate the control plane for this complex domain. KubeFed created the control plane and registry to allow an administrator to see and deploy API objects across joined member clusters. Administrators are now able to leverage single sets of YAML files rather than X files for X number of clusters, simplifying the required management.
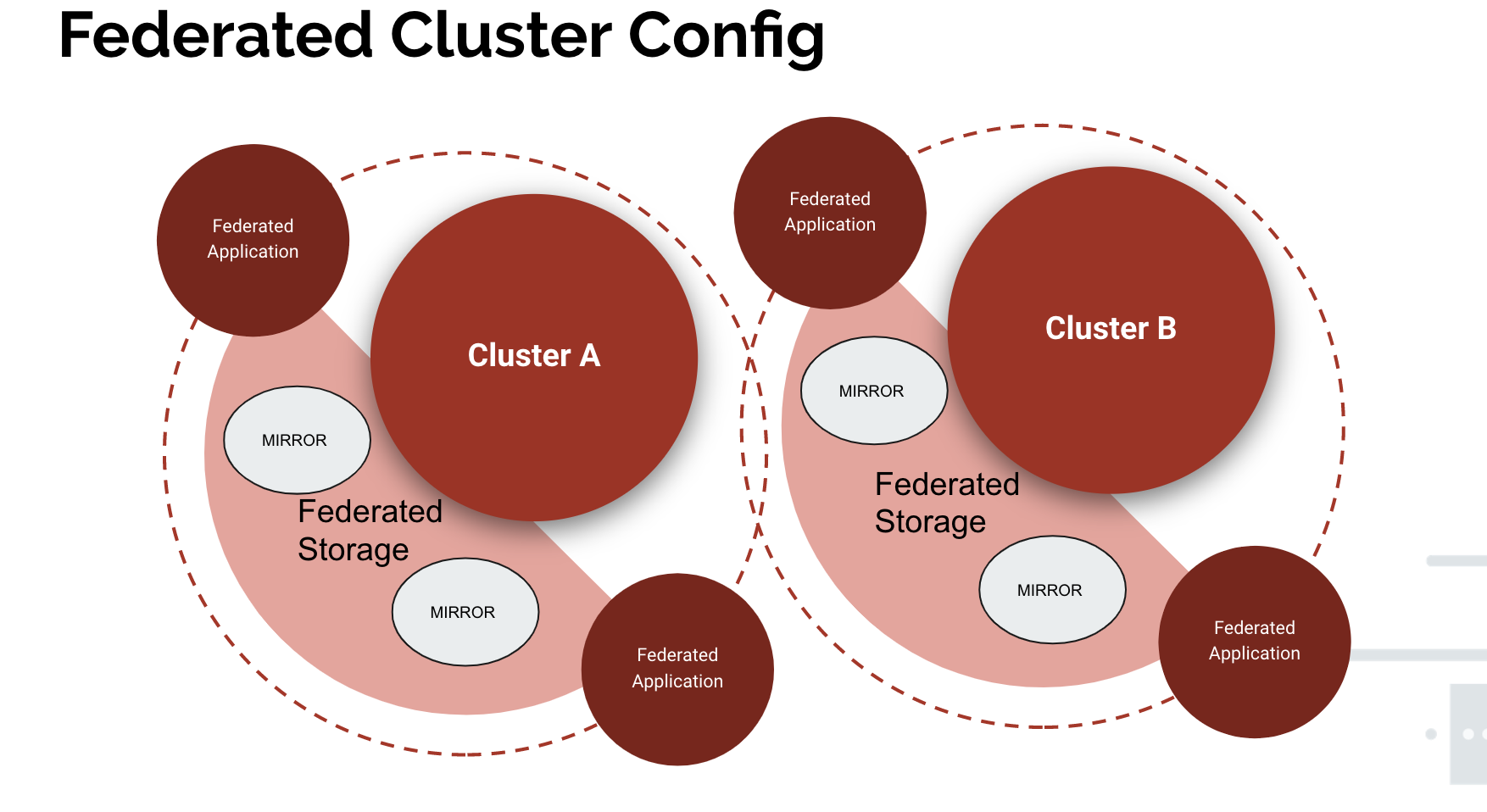
KubeFed now provides a means of sharing configuration, network, and storage between previous disparate clusters
Now with the clusters sharing resource definitions, we can manage our application to a single set of YAML for all clusters. With the joined cluster we have:
- Single Storage Class for both clusters
- Ability to retype storage with overrides
- Single Application definition for both clusters
- Single provisioner type for both clusters
- Single persistent volume type
Scaling the Pattern
The previous diagram with one config per-application per-cluster can now be consolidated into a single config. Note KubeFed provides a means of overriding specific supported fields that can help in customizing per cluster.

KubeFed not only consolidates the configuration for each workload but also extends the API to provide unique overrides for each cluster as seen with the replica found in the pod definition
What about Storage?
There is no denying it, storage in a containerized environment is hard. Working with a stateful component in an intentionally stateless environment has always been an interesting juxtaposition. Historically it has been the last component of integration and least coupled into the Kubernetes landscape.
With the general availability of Containerized Storage Interface (CSI), storage has continued to be abstracted outside the Kubernetes control plane. However, as we recognize that applications both produce and consume storage in the enterprise, defining policies and procedures for migrating applications and managing the data around them is more important than ever.
When framing the use cases for storage in a federated environment, there are four important considerations:
- Placement – As an OpenShift user, with several OpenShift clusters available to me, I need a way to articulate and affect which of the OpenShift clusters I would like to place my application(s) on.
- Portability – As an OpenShift user, I need a way to migrate my applications from one OpenShift cluster to another, regardless of where in the hybrid cloud they are deployed.
- State – As an OpenShift user, I need a way to migrate the data around my application from one OpenShift cluster to another with little to no disruption
- Administration – As an OpenShift administrator I need to be able to federate storage definitions to multiple clusters to reduce overhead for my users.
Given these considerations we plan to look at six patterns for storage federation in our subsequent blogs.
These patterns arose from analysis of enterprise data needs and usage, and how best to describe common data flows and use cases across clustered systems. All of these patterns utilize storage in a containerized environment and reflect common pain points of data gravity and possible solutions to address those pain points.
As a secondary benefit to defining these patterns, we were also able to identify potential gaps and help provide additional solutions and processes to help mitigate negative impacts and make the data more agile.
- Use existing cluster storage capabilities while federating an application.
- Migrate your data with your application.
- Stretch storage across N clusters to provide a single storage point.
- Federate the storage independent of the application.
- Perform an offline migration of the cluster.
- Provide active:active or active:passive disaster recovery.
See you next time when we dive into Pattern One and how we use storage classes to abstract the storage layer for federated applications.