
Have you ever felt that every conversation you have with an LLM feels like starting over from scratch? LLMs have a problem: they have the memory of a goldfish (no disrespect to goldfish intended). This article explores the solution: Agent memory.
Agent memory systems provide persistent, queryable storage that allows agentic inference systems to recall past interactions, accumulated knowledge, and learned preferences. These go beyond related technologies like basic context engineering and retrieval-augmented generation.
Throughout 2025 and 2026, agent memory has become a critical focus area across AI research labs and vendors. A common theme emerging from recent studies and projects such as the Stanford Meta-Harness paper, CMU’s Externalization paper, Andrej Karpathy’s LLM Wiki project (which we cover later in this blog), and early foundational work on agent memory such as Google’s Simulacra paper can be summarized as follows
Agent capability ≠ just model weights
Agent capability = model + harness + memory + environment + evolution
Early studies have shown that an average sized model with a better harness, memory, and systems implementation can well outperform a larger sized model that lacks a good harness and memory system around it. Memory in particular is key for continuous self-learning over long running tasks and eventually getting to multi-agent swarm learning and “enterprise mind” systems. Hence it is not surprising that most leading vendors are introducing agent memory related products and features, for example, Anthropic’s Memory and Dreaming product within its Managed Agents API, Langgraph’s agent harness memory, memory features of OpenClaw, and many more. At Red Hat, along with the rest of the industry, we see these technologies as foundational components of the future AI-enabled enterprise.
This post covers four areas: (1) memory-related challenges with current inference architectures, (2) end-to-end system architecture and terminology for agent memory, (3) a brief survey of existing open source projects, and (4) an initial deployment example using OpenClaw agents with agent memory. Future blog posts will explore additional agent+memory deployment options, implementation details, benchmarking, and hands-on experimentation.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
Challenges with current memory-less inference
LLM inference is fundamentally stateless—each input prompt produces an output response, leaving the model unchanged with no retention of the interaction. While this statelessness offers benefits like reproducibility and simplicity, it creates significant challenges:
- Computational inefficiency: All queries require full recomputation from scratch. It is an inefficient use of AI hardware to have it redo similar computation over and over.
- Context window limitations: Long multi-turn conversations, agentic workflows, and long-running tasks require long context and re-introducing entire chat histories into each prompt. As context grows, models suffer from attention errors and ‘context rot’ while also incurring massive KV cache computation costs at the same time.
- No long-term learning across inferences: Models cannot self-improve from deployment experience without full retraining.
- Isolated agents: No mechanism for cross-agent knowledge sharing or swarm intelligence.
- No knowledge base build-up: There is no build up of a persistent knowledge base using inferred knowledge and memories
While context engineering techniques (e.g.,compaction, filtering, retrieval-augmented generation, caching) help mitigate these issues, they address symptoms rather than the root cause. Agent memory systems—infrastructure that enables agents to create, manage, and retrieve memories to augment inference—represent a more fundamental solution.
Terminology and sample E2E architecture
This section outlines a sample end-to-end architecture to establish terminology and provide architectural context on multiple approaches. This is illustrative, not prescriptive—many valid architectures exist.
Note: Unless otherwise specified, “agent” refers to both human users and agent applications interacting with inference systems.
Client-Side vs. Server-Side Agent Memory
Client-side agent memory is private to the agent and directly managed by it. Example: memories created by a developer’s personal OpenAI assistant.
Server-side agent memory is provider-managed, with capabilities for multi-agent learning, enterprise data governance, security, auditing, versioning, and content attribution. This blog focuses a bit more on server-side agent memory, though both paradigms are covered.
Memory Types
Terminology in this space is still emerging. Common classifications include:
Session memory: Contains the complete history of queries and responses within a single agent-LLM session. Lifetime is scoped to one session. Example: OpenAI Responses API conversation state management implementations.
Long-term file system memory: Memories stored as files in a filesystem, often with supplemental indexing. Effective because agent runtimes naturally traverse directory structures.
Long-term episodic memory: Persistent memory structured around events and temporal sequences, with lifetime beyond individual sessions.
Long-term semantic memory: Persistent memory stored using embeddings to enable semantic search and retrieval, typically in vector databases augmented with graph metadata and indexing.
This is a broader topic than covered here. Additional memory types exist for different mutability patterns, access patterns and so on. A more complete discussion of this topic would include memory categorization along multiple dimensions such as temporal scope, cognitive type, storage type, and functional type.
Sample E2E Architecture
The diagram below illustrates a multi-agent system where different agent types (e.g., workflow oriented agents using Langgraph SDK, persistent agents using PI/OpenClaw) interact with LLM instances while sharing memory infrastructure.
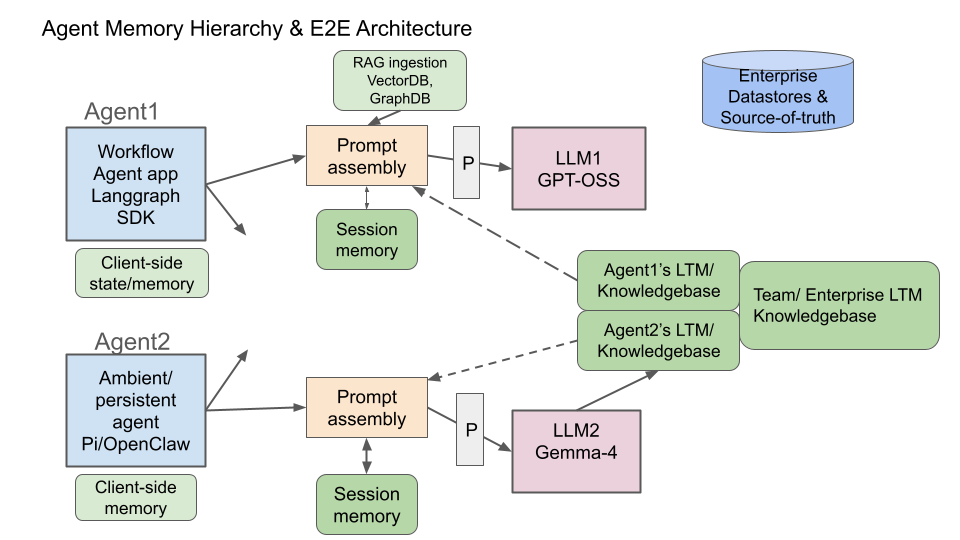
Key architectural flows:
1. Prompt assembly: Each model being served has its own prompt assembly function that aggregates context from:
- Session memory (conversation history)
- RAG-ingested data (VectorDB, GraphDB)
- Long-term memories (LTM) from memory file systems, semantic memories
- Enterprise datastores and sources of truth
Note: Prompt assembly (as well as other functions in this architecture) can be implemented either at the client side or server/provider side, or at both locations. As noted previously, this is an illustrative architecture to convey concepts that can be implemented either as client-centric or provider-centric solutions or a combination of both.
2. Inference: The assembled prompt is sent to the agent’s chosen LLM.
3. Memory write-back: Post-inference, new memories are written back to Long-Term Memories. The various available agent memory frameworks offer multiple options for how and when memories are created and written back. This could be an implicit operation performed by transparently intercepting the query response flow between a client and LLM or could be via explicit control and memory tools and skills from the client or provider after each query/response sequence.
4. Hierarchical memory structure:
- Agent-scoped LTM: Private to individual agents (Agent1’s LTM, Agent2’s LTM)
- Shared LTM: Team or enterprise-wide knowledge bases accessible across agents
This enables both personalization and collective learning. There could be more than two levels of hierarchy here. Consider the possibilities when team and enterprise tribal knowledge is captured, maintained, and shared in this way. A new human or digital worker joining a team can immediately have access to the team’s prior tribal knowledge and get jumpstarted for contribution. Loss of individual workers on a team will have less impact if their knowledge has been assimilated into such team memories or hive brains. We can see how knowledge from human and agentic workers starts to get codified into hierarchical “enterprise mind architectures” of the coming future.
5. Data separation: Agent memories remain distinct from enterprise source-of-truth databases, which are never modified by agent memory operations
6. Background memory maintenance and dreaming: Framework-dependent processes continuously process, curate, and optimize LTMs to reduce duplication, evict stale memories, form new memory associations, and derive new knowledge. This is also referred to as “dreaming” in some of the agent memory solutions.
Implementation details vary by framework, agent runtime, and deployment patterns. All this futuristic enterprise brain infra and agentic memory dreaming will need a range of new monitoring, administration, vetting, and security functions, but will also be core to an enterprise’s intellectual property and captured tribal knowledge.
Community and open source projects in this space
Across the ecosystem, a clear pattern is emerging: memory in AI agents is being treated less as a single feature and more as a composable layer that can be designed, swapped, and optimized. Below are just a few examples of representative community initiatives in this space.
One notable projects is Mem0. Mem0 focuses on building a memory layer for AI assistants and agents capable of automatically extracting and storing useful information from conversations, curating it, and recalling for injection into future prompts in a cross-session manner. The project features multiple memory extraction options with and without dependence on agent harness skills, and these happen asynchronously from inline agentic inference. It claims good results in benchmarks designed around long conversation memory such as LoCoMo. Mem0 open source can be deployed as a memory plugin for multiple agent harnesses in local AI deployments as well as via the Mem0 cloud platform. In the next section we have a simple initial exercise of using mem0 in combination with OpenClaw. We expect to dive further into this in upcoming work and share our findings in future blog posts.
The OpenClaw agent project includes a customizable memory architecture with both built-in agentic memory features as well as options to plugin external memory providers (such as mem0 and others). OpenClaw’s built-in memory is file-based and explicit: the agent “remembers” by writing plain Markdown into its workspace—primarily MEMORY.md for durable facts and memory/YYYY-MM-DD.md for daily notes. At runtime, the active memory plugin (default memory-core) provides memory_search and memory_get, using keyword and optional vector search over those files. Before conversation compaction, OpenClaw runs an automatic “memory flush” pass to save important context so it isn’t lost. An optional “dreaming” pipeline can later consolidate short-term notes into higher-signal long-term memory. The plugin architecture further enables external plugins to provide additional agentic memory features.
Many coding agents, including Claude Code, Codex, Letta , Mastra and others, have also developed memory architectures allowing them to be used for both coding and more general purpose tasks. Well-designed memory architecture is important for coding workflows. In coding workflows, these agents often need to remember repository structure, previous debugging attempts, coding preferences, and long-running tasks carried across multiple sessions. These long-term memory features become an asset when these agents are applied to more general workflows. Starting with the CLAUDE.md file, which can be seen as the earliest form of simple agent memory, Claude (and other similar coding agents) are now introducing advanced memory and dreaming features, which we are also evaluating as part of this study.
A category of community projects has emerged from Andrej Karpathy’s LLM-Wiki project. These projects explore the idea of using wiki-style knowledge organization as a long-term memory system for language models and agents. Raw data is ingested, then “compiled” into a wiki-like derived memory base of linked notes. These notes can then be curated, evolved, and made available to an agent harness augmented with wiki traversal skills, as in this example. The visibility around this project has led to an ecosystem of similar and complementary projects. Graphify and Graphiti are examples of tools that create a more structured, machine-oriented graph database of memory elements from raw data beyond just wiki notes.
Other notable projects in this space include agentmemory, OpenViking, MemoryHub, Zep/Graphiti, Honcho and more, all of which explore different abstractions for persistent agent memory and long-term context management. These differ in their focus around personal vs. enterprise AI, deployment options, the granularity and types of agent memory, enterprise security, and governance security features. Although many of these systems are still experimental, together they demonstrate how quickly the open source community is iterating on the challenge of making AI agents more stateful and adding richer memory features both for personal AI as well as emerging Enterprise level agentic AI.
OpenClaw and Mem0 memory example
To see these concepts in action, let’s look at an introductory practical example. We compared the built-in memory of the OpenClaw agent with an external memory plugin, Mem0, to see what difference a dedicated memory layer can make. This is a basic introductory example, since this blog post has been primarily focused on technology background. Additional deep dives and details will be shared in a future blog post.
OpenClaw provides a basic out-of-the-box memory solution: a series of markdown files that persist across sessions. These are loaded into context on startup but they focus heavily on remembering who you are, your preferences, and its own personality rather than specific task details. While the agent can update these memory files, it must choose or remember to do so. To show how much that judgement can vary, we ran it side by side against the Mem0 plugin, which runs an extraction pipeline after each turn.
We gave the agent a two-session task: research free weather APIs and recommend one for a hobby project called Beacon, then start a new session and pick up where it left off. Same script, two configurations.
“Research the top free weather APIs available today and recommend the best one for a project called Beacon. I want something with a generous free tier that’s easy to use.”
Session 1 was identical in both cases. The agent researched the options, landed on Open-Meteo (no API key, 300k calls/month free, open source), and offered to start building.
Session 2 is where they diverge. With the default setup, the agent had no memory of the previous conversation:
“I have no record of a ‘Beacon project’ or any API we discussed. As far as I can tell, this is the first time we’ve spoken.”
With the Mem0 plugin installed, it picked up the context immediately, scaffolded the project, and ran it against the live API:
“Live data flowing — Dublin’s 15.6°C and overcast right now. Beacon is scaffolded, working, and committed.”
This is the difference between having persistent memory and not having it. The agent is technically capable of saving context as it persisted personal details like names and preferences during testing. It simply did not judge project details to be worth saving. If it missed an explicit brief after a single prompt, that judgement will only become less reliable across weeks of work. Mem0 removes that risk.
This test can be reproduced by following the readme and using the configurations found in this repo.
Conclusion and next steps
This blog was only an introduction to the important and emerging topic of agent memory. As we continue our investigations on this topic, we will share additional findings and analysis via future blog posts.