
PyTorch is the most popular deep learning framework for both research and industry, allowing millions of developers to build complex neural networks using a high-level Python interface. However, Python alone is too slow to efficiently train and run modern large-scale neural networks. To address this, PyTorch relies on highly optimized kernels written primarily in C++ with CUDA extensions.
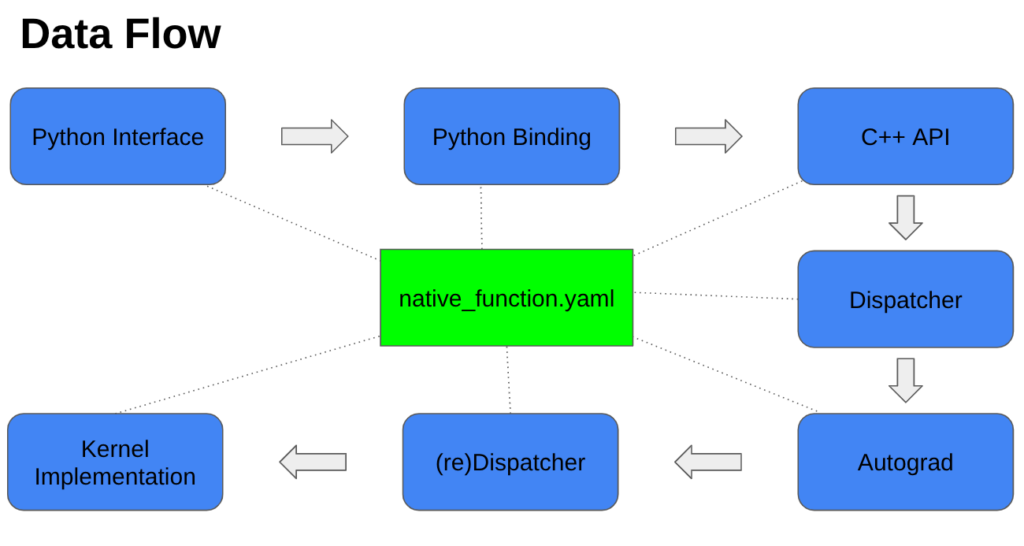
This architecture raises a fundamental question: how does a simple line of Python code trigger a high-performance kernel on a specific device? The answer lies in a sophisticated, multi-layered call stack that handles everything from type conversion to hardware routing. In this post, we will examine the process by which a call to a Python interface sends information to an optimized kernel.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
Key takeaways
The following points summarize the essential mechanisms that drive the PyTorch call stack:
- Configuration-Driven Code: The native_functions.yaml file acts as a master blueprint, defining function signatures and driving the autogeneration of the C++ infrastructure required for dispatching and API variants.
- Type Conversion: The entry point into the C++ backend is an autogenerated “THP” method that validates input types and converts Python objects into their C++ representations.
- The Dispatcher Layer: A central dispatcher routes operations based on several factors, including hardware (CPU vs. CUDA), data types (float vs. int), and tensor layouts.
- Boxing and Unboxing: To pass through the generic dispatcher, C++ arguments are converted into IValue container objects (boxing) and then restored to concrete C++ types for the specific kernel (unboxing).
- Automatic Differentiation: The Autograd layer checks if input tensors require gradients; if they do, it creates a backward gradient node to enable model training during the backward pass.
- Kernel Specialization: The process concludes with a device-specific kernel where C++ macros are used to specialize the logic for different data types, ensuring both mathematical correctness and efficiency.
Example
To better understand this process, we will follow the call stack of the PyTorch method torch.logaddexp(), an element-wise operation that takes in two tensors and calculates
zi=(exi+eyi).
There is nothing special about this method other than it follows a typical execution path from the Python call to the underlying kernel implementation.
Before we dive into the code, we need to discuss one of PyTorch’s most important configuration files: native_functions.yaml. Although it is not part of the call stack itself, it drives the autogeneration of many of the files that are in it. Each entry in this file defines a function’s signature, including its name and the input/output arguments. Additional metadata may specify API variants (e.g. function: torch.logaddexp(x, y) or method: x.logaddexp(y)), as well as how dispatch keys map to different kernel implementations. A common implementation is to use a ‘.out’ structured delegate, which writes to a preallocated output tensor that the main function returns. PyTorch also defines many other keys, such as tags, structured, device_check, etc., each of which influences both the autogenerated C++ code and the runtime dispatch and validation behavior of the operator.
native_functions.yaml
- func: logaddexp.out(Tensor self, Tensor other, *, Tensor(a!) out) -> Tensor(a!) structured: True structured_inherits: TensorIteratorBase dispatch: CPU, CUDA, MPS: logaddexp_out tags: pointwise - func: logaddexp(Tensor self, Tensor other) -> Tensor variants: method, function structured_delegate: logaddexp.out tags: pointwise
The code
Step 1: The Python interface and binding
Now, let’s look at the code. The most common way for a user to interact with PyTorch is through Python, and for most users this is all they will ever need, where low-level backend details can mostly be ignored. However, if you need to update a tensor operation or are simply curious about how your program works under the hood, it helps to know what happens between the lines of Python code. A typical call stack between your Python interface and the C++ kernel can involve over 20 intermediate C++ function calls. Below, we’ll examine the most relevant ones and explain what each is responsible for.
main.py
x = torch.rand(2, device=device)
y = torch.rand(2, device=device)
z = torch.logaddexp(x, y)
# z_i = log(e^{x_i} + e^{y_i})
The first step into C++ code is an auto-generated method of the form “PyObject * THPVariable_…” followed by the method’s name (e.g. THPVariable_logaddexp).
torch/csrc/autograd/generated/python_torch_functions_2.cpp:
static PyObject * THPVariable_logaddexp(PyObject* self_, PyObject* args, PyObject* kwargs)
{
HANDLE_TH_ERRORS
static PythonArgParser parser({
"logaddexp(Tensor input, Tensor other, *, Tensor out=None)",
}, /*traceable=*/true);
ParsedArgs<3> parsed_args;
auto _r = parser.parse(nullptr, args, kwargs, parsed_args);
if(_r.has_torch_function()) {
return handle_torch_function(_r, nullptr, args, kwargs, THPVariableFunctionsModule, "torch");
}
if (_r.isNone(2)) {
// aten::logaddexp(Tensor self, Tensor other) -> Tensor
auto dispatch_logaddexp = [](const at::Tensor & self, const at::Tensor & other) -> at::Tensor {
pybind11::gil_scoped_release no_gil;
return self.logaddexp(other);
};
return wrap(dispatch_logaddexp(_r.tensor(0), _r.tensor(1)));
} else {...
This method verifies that the given input arguments match the expected types, converts the Python objects into their corresponding C++ representations, and then passes the arguments to the C++ API. The C++ API itself is also auto-generated and can be called directly from C++.
build/aten/src/ATen/core/TensorBody.h:
inline at::Tensor Tensor::logaddexp(const at::Tensor & other) const {
return at::_ops::logaddexp::call(const_cast<Tensor&>(*this), other);
}
At this stage, a ‘call’ method is invoked, which retrieves a TypedOperatorHandle object that uses a type-safe handle to access operators through PyTorch’s dispatcher.
build/aten/src/ATen/Operators_2.cpp:
at::Tensor logaddexp::call(const at::Tensor & self, const at::Tensor & other) {
static auto op = create_logaddexp_typed_handle();
return op.call(self, other);
}
Step 2: The dispatcher and argument boxing
After the C++ API, the code flows into the dispatcher layer.
aten/src/ATen/core/dispatch/Dispatcher.h
TypedOperatorHandle::call(Args... args) … Tensor Dispatcher::call(const TypedOperatorHandle<Return(Args...)>& op, Args... args)
This is the most complex section of the call stack and is responsible for routing the operation to the appropriate kernel. People often think of the dispatcher as choosing between a CPU and CUDA kernel, and while it certainly does that, it also handles much more. The dispatcher can route based on data type (e.g. float or int), tensor layout (dense or sparse), and even determine whether autograd needs to run or can be skipped (such as in inference_mode()). Within this layer, the code also boxes and unboxes C++ arguments.
aten/src/ATen/core/boxing/KernelFunction_impl.h
KernelFunction::call(const OperatorHandle& opHandle, DispatchKeySet dispatchKeySet, Args... args) … callUnboxedKernelFunction(void* unboxed_kernel_func, OperatorKernel* functor, DispatchKeySet dispatchKeySet, Args&&... args) …
Boxing converts C++ arguments into generic IValue container objects so they can flow through the dispatcher as generic typed objects, while unboxing restores these IValue objects back into concrete C++ types (Tensor, int64_t, double, etc.) for the kernel. A kernel functor wrapper then uses the unboxed arguments to invoke the appropriate kernel.
aten/src/ATen/core/boxing/impl/make_boxed_from_unboxed_functor.h
wrap_kernel_functor_unboxed_::call(
OperatorKernel* functor,
DispatchKeySet dispatchKeySet,
ParameterTypes... args){ …
Depending on the dispatch key, execution can follow one of two paths. If autograd is not required (e.g., in inference_mode), the dispatcher proceeds directly through the final native-layer wrappers before the kernel implementation. Otherwise, execution is first routed through the autograd layer.
Step 3: The autograd layer
If the dispatch routes to autograd, the auto-generated autograd wrapper for the method is invoked. This wrapper checks whether any of the input tensors have requires_grad set to ‘True’. If so, it creates a backward gradient node; otherwise, the backward node is set to ‘nullptr’. The autograd wrapper then redispatches the call to the underlying functional implementation, following a path similar to the original dispatcher. The results of that call are later used to compute gradients during the backward pass. Since we are following the forward call path to the kernel implementation, the details of the backwards gradient computation are outside the scope of this post.
torch/csrc/autograd/generated/VariableType_2.cpp
at::Tensor logaddexp(c10::DispatchKeySet ks, const at::Tensor & self, const at::Tensor & other) {
auto& self_ = unpack(self, "self", 0);
auto& other_ = unpack(other, "other", 1);
[[maybe_unused]] auto _any_requires_grad = compute_requires_grad( self, other );
[[maybe_unused]] auto _any_has_forward_grad_result = (isFwGradDefined(self) || isFwGradDefined(other));
std::shared_ptr<LogaddexpBackward0> grad_fn;
if (_any_requires_grad) {
grad_fn = std::shared_ptr<LogaddexpBackward0>(new LogaddexpBackward0(), deleteNode);
grad_fn->set_next_edges(collect_next_edges( self, other ));
grad_fn->other_ = SavedVariable(other, false);
grad_fn->self_ = SavedVariable(self, false);
}
#ifndef NDEBUG …
#endif
auto _tmp = ([&]() {
at::AutoDispatchBelowADInplaceOrView guard;
return at::redispatch::logaddexp(ks & c10::after_autograd_keyset, self_, other_);
})();
auto result = std::move(_tmp);
Step 4: Device-specific registration and final kernel execution
If the dispatcher routes to the function kernel, either because autograd has already run or because the operation is in inference_mode, a generated registration wrapper is called for the specific device. This wrapper performs device-specific setup and then calls the structured kernel implementation. Depending on the function, this may route directly to the kernel, or it may invoke a few intermediate methods to construct tensor iterators, allocate output tensors, call dispatch stubs, or perform other necessary setup before finally invoking the kernel.
build/aten/src/ATen/RegisterCPU_1.cpp
Tensor wrapper_CPU_logaddexp(const at::Tensor & self,
const at::Tensor & other){ …
aten/src/ATen/native/BinaryOps.cpp
CREATE_BINARY_TORCH_IMPL_FUNC(logaddexp_out, logaddexp_stub)
aten/src/ATen/native/DispatchStub.h
DispatchStub::operator()(c10::DeviceType device_type, ArgTypes&&... args) { …
Finally, the kernel is invoked. This is where the actual logic and computation occur, and if a user needs to update an operation, this is typically the place where changes are made. PyTorch provides a collection of macros that kernels can use to specialize behavior for different data types (integer, floating-point, complex, etc.). These macros help maintain both correctness and efficiency by selecting logic appropriate for the types. They are also commonly used to raise errors when a function does not support a particular data type (for example, torch.gcd() with non-integer tensors).
aten/src/ATen/native/cpu/BinaryOpsKernel.cpp
void logaddexp_kernel(TensorIteratorBase& iter) {
if (at::isReducedFloatingType(iter.dtype())) {
AT_DISPATCH_REDUCED_FLOATING_TYPES(iter.dtype(), "logaddexp_cpu", [&]() { …
} else if (isComplexType(iter.dtype())) { …
} else {
AT_DISPATCH_FLOATING_TYPES(iter.dtype(), "logaddexp_cpu", [&]() {
cpu_kernel_vec(
iter,
[=](scalar_t a, scalar_t b) -> scalar_t {
if (std::isinf(a) && a == b) {
return a;
} else {
scalar_t m = std::max(a, b);
return m + std::log1p(std::exp(-std::abs(a - b)));
}
},
[=](Vectorized<scalar_t> a, Vectorized<scalar_t> b) {
Vectorized<scalar_t> inf(std::numeric_limits<scalar_t>::infinity());
Vectorized<scalar_t> m = maximum(a, b);
return Vectorized<scalar_t>::blendv(
m + (a - b).abs().neg().exp().log1p(),
a,
(a == b) & (a.abs() == inf));
});
});
}
}
Conclusion
In this post, we traced the path from a high-level PyTorch Python call down to its underlying C++ kernel implementation. If the input tensors reside on a CUDA device, the call stack follows a nearly identical pattern, except the last few calls would have been dispatched to the CUDA kernel rather than the CPU version. Although we followed torch.logaddexp() specifically, the same dispatch machinery underlies most PyTorch tensor operations implemented in ATen. This layered design (Python front end, dispatcher, and backend kernels) allows PyTorch to remain both easy to use and highly extensible. Understanding these components not only demystifies what happens beneath the Python API, but also provides valuable insight for developers who need to modify kernels, debug dispatch behavior, or contribute to PyTorch’s backend.