
In the world of Large Language Models (LLMs), speed is very important. Much of this speed comes from highly specialized functions called GPU kernels which are small, focused routines that instruct the GPU how to perform calculations with the maximum efficiency. Traditionally, experts would write these kernels by hand, which requires deep knowledge of GPU architecture in some cases. Today, a new wave of DSLs (domain-specific languages) and AI-powered tools promises to facilitate and/or automate this work. This post shares a reproducible benchmark that compares these different ways to develop GPU kernels.
This is the third installment in a three-week deep dive into Triton kernel trust and performance. In our previous articles we covered OCI caching and cryptographic signing.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future. The conclusions expressed in this article are solely those of the authors, and do not constitute an official Red Hat policy or position.
Why this matters
Writing and maintaining hand-tuned Triton kernels is expensive, and it doesn’t scale across rapidly changing models and hardware. This post shares a reproducible benchmark that compares four approaches to GPU kernel development:
- Hand-written Triton: the expert-tuned baseline.
- torch.compile / TorchInductor: PyTorch’s built-in compiler that generates optimized GPU kernels with minimal manual effort.
- Helion: a higher-level, tile-first DSL that compiles to Triton and autotunes schedules for the fastest kernel configuration.
- LLM/agent-based kernels: Triton kernels generated using KernelLLM and Makora Generate.
We evaluate each approach against three pillars of production ready kernels: correctness, performance, and portability across GPU vendors. We also include an often-missed fourth pillar: the cost to get results (tuning time and engineering time).
TL;DR
- Best plug-and-play default: TorchInductor (PyTorch’s built-in compiler) was consistently strong and required the least manual work, making it an excellent starting point for most teams.
- Best peak performance (when you can pay the tuning bill): Helion often matched or exceeded the best results, but tuning can take hours for a full sweep, and we observed an issue with small-shape correctness on both consumer and data-center GPU B, which corresponds to a portability anomaly.
- Strong baseline but not “free”: Hand-written Triton is a great starting point, but competitive performance typically needs expert tuning and per-GPU iteration.
- Promising but variable: LLM-generated kernels. KernelLLM can produce working Triton, but requires manual fixes and generalization work. Makora Generate reduced friction significantly, but performance was more shape- and kernel-dependent without an explicit tuning loop.
Backends Overview
Before diving into results, it helps to frame what we’re actually comparing. In this benchmark we evaluate a spectrum of kernel-development approaches. We began with hand-written Triton kernels, which typically demand the most engineering effort but offer the highest performance ceiling. We then moved to compiler-driven approaches, comparing the more automated TorchIndutor backend with Helion, a high-level tile-first DSL for kernel authoring. Finally, we explored generative workflows using LLM-hosted tools KernelLLM and Makora Generate. Each backend represents a different trade-off between engineering effort, tuning cost, peak performance, and portability across GPU vendors.
The table below summarizes what each one is and the key practical notes we observed while using them.
| Backend | Description | Key Notes |
| Triton[1] | DSL and compiler for highly efficient GPU kernels. It abstracts low-level GPU details like memory allocation and thread synchronization | Requires understanding tile design and memory usage; While it supports @triton.autotune, defining the search space remains a manual task and requires expertise. |
| TorchInductor [2] | PyTorch’s graph-level compiler (default backend for torch.compile) that converts dynamic Python code into a static, optimized graph. | Very easy to use; supports kernel fusion (combining multiple operations into one), scheduling optimization, and autotuning. Minimal manual effort required. |
| Helion[3] | Python-embedded DSL for tile-oriented kernel programming (“PyTorch with tiles”). It can generate multiple Triton variants and autotune for the target GPU. | Reduces boilerplate; supports flexible tiling and schedule decisions. Autotuning can take 15+ minutes per kernel/shape. |
| KernelLLM[4] | Fine-tuned LLM for generating Triton GPU kernels from PyTorch code; primary interface is generate_triton. | Can generate working kernels but often requires manual fixes and generalization. Higher friction compared to other backends. |
| Makora Generate[5] | Hosted workflow that generates GPU kernels from PyTorch references or KernelLLM prompts. | Easy-to-use; validates prompts, produces generalizable kernels, and handles compilation/benchmarking automatically. |
Comparison rules (fairness)
This benchmark is meant to answer a practical question: “If I want the best performance across different GPU vendors and models with reasonable effort, what should I use?“. It is not a contest of “best possible Triton” or “best possible Inductor”.
To keep comparisons meaningful:
- We measured steady-state kernel performance following compilation and warmup.
- For hand-written Triton, we used well-known tutorial-style kernels as a baseline, with minimal changes for bf16 and shape coverage (and autotuning where noted). We used tutorial kernels because this represents the ‘starting point’ for 90% of engineers.
- For Inductor, we tested max-autotune mode.
- For LLM-generated kernels, we report performance from the generated implementation after the minimal fixes needed for correctness and benchmarking. We did not attempt to build a full shape-specific autotuning pipeline for those kernels because the engineering cost was disproportionate for this evaluation.
Kernel implementation notes (short version)
This post is about trade-offs, so we keep backend notes to what you need to know to reproduce and/or interpret results:
Hand-written Triton
- MatMul: based on the Triton tutorial MatMul kernel [6], adapted to bf16 and our shape set.
- LayerNorm: based on the Triton tutorial LayerNorm kernel, adapted to bf16 and forward-only. We added autotuning to search for the best configuration.
- GEMM+GELU: based on Triton tutorial MatMul kernel [7], we added a bias and replaced the activation with a custom gelu-erf function.
Inductor (torch.compile)
- We wrapped the PyTorch reference implementations and benchmarked compiled kernels in max-autotune (better peak performance).
Helion
- MatMul: hl.tile([m, n]) defines the output tile grid; hl.tile(k) defines the reduction loop. Accumulate in fp32 and cast back to the promoted output dtype.
- LayerNorm: row-wise tiling; mean/variance computed in fp32; normalize and cast within the same kernel body. Note: TritonBench passes (x, weight, bias, eps); our Helion kernel ignores affine parameters, which matches the benchmark setup where weight=1 and bias=0.
- GEMM+GELU: expressed as one tiled kernel where bias and GELU stay fused with the MatMul accumulator.
KernelLLM
- KernelLLM produced working Triton kernels, but we repeatedly hit the same classes of issues: grid specification mismatches (needed explicit grid lambdas), dtype mismatches in intermediate buffers, and hard-coded shape assumptions that required manual generalization.
- We generalized kernels for shape coverage; we did not build an extensive autotuning loop due to time and stability issues (including frequent crashes).
- For LayerNorm, we had to manually promote the intermediate accumulation buffers from bf16 to fp32 to ensure numerical stability.
Makora Generate
- We reused prompts from KernelLLM and relied on Makora Generate’s pipeline for validation, compilation, and benchmarking.
- For GEMM+GELU, we enforced the erf-based GELU in the prompt to avoid tanh approximations.
Intro + kernels video:
Hardware and methodology
We ran the benchmark across two consumer GPUs and two data center GPUs (four total). To keep the focus on portability, we refer to them as Consumer GPU A/B and Data Center GPU A/B, where A and B represent different vendors.
Benchmarking details:
- Harness: TritonBench[8] using Helion benchmark, driven by our repository to run the same operators across backends.
- Default TritonBench settings: 25 warmup iterations and 100 timed repetitions.
- Metrics:
- MatMul and GEMM+GELU: TFLOPS (trillions of floating-point operations per second) derived from standard GEMM FLOP counts and measured latency.
- LayerNorm: effective GB/s (gigabytes per second) derived from measured latency, since this operation is memory-bandwidth-bound rather than compute-bound.
- Correctness:
- We evaluated 852 (backend, shape, operator) test configurations.
- Overall pass rate: 850/852 (99.77%).
Benchmark video:
Results
We benchmarked MatMul, LayerNorm, and GEMM+GELU across two consumer GPUs and two data center GPUs. All runs used bf16 and correctness was validated with torch.allclose(atol=1e-5, rtol=1e-2). The json results are available in the benchmark repo [9].
Performance
MatMul
Across all four GPUs, the plots show autotuned stacks at (or above) the Triton baseline: Helion and Inductor consistently match/exceed Triton, with Inductor peaking at 706 TFLOPS on a data center GPU for large shapes.
As expected, data center GPUs land ~3-10× higher TFLOPS than consumer GPUs, and the lower-end consumer GPU shows the largest spread between backends which is a clear signal that portability matters most on less-optimized hardware paths. KernelLLM and Makora Generate generally trail the autotuned approaches by ~20–50% on MatMul, consistent with “no tuning loop” behavior.
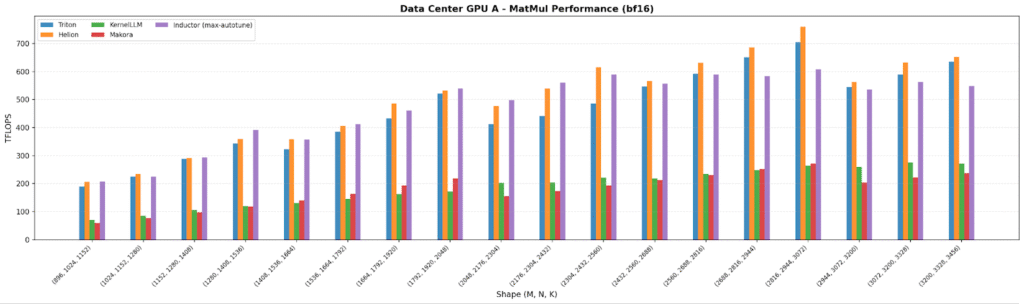
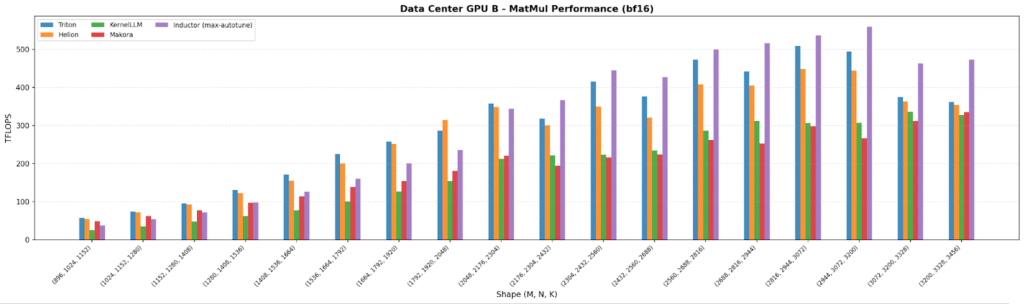

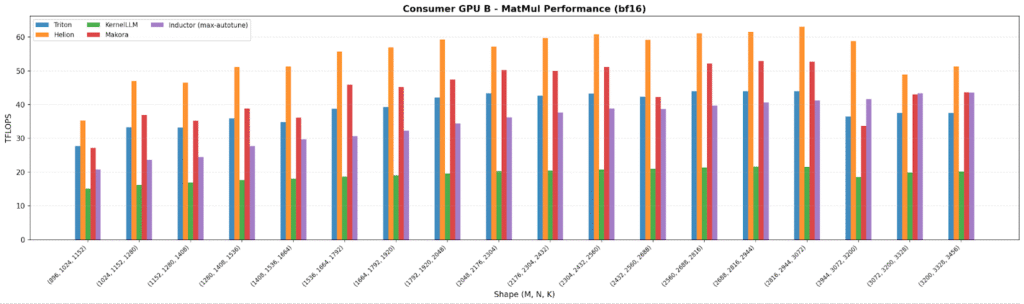
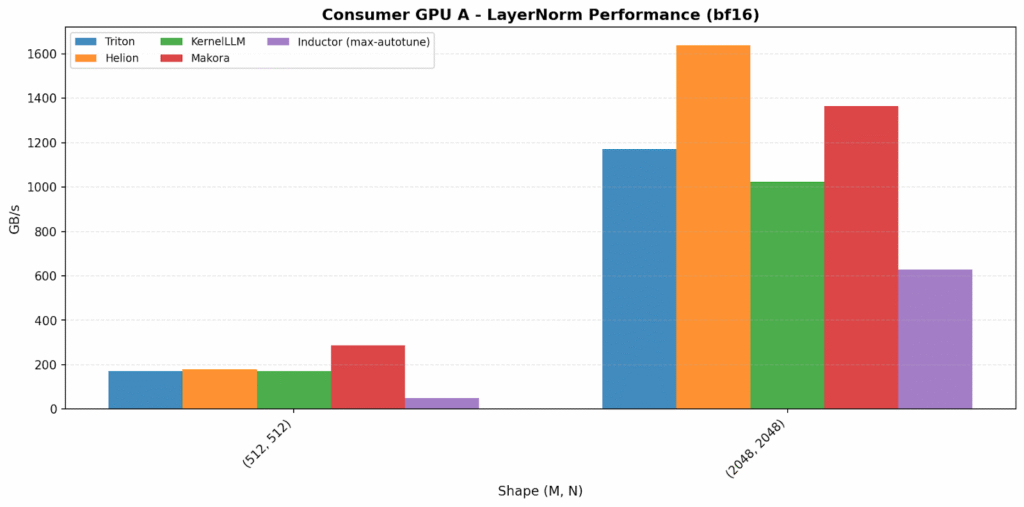
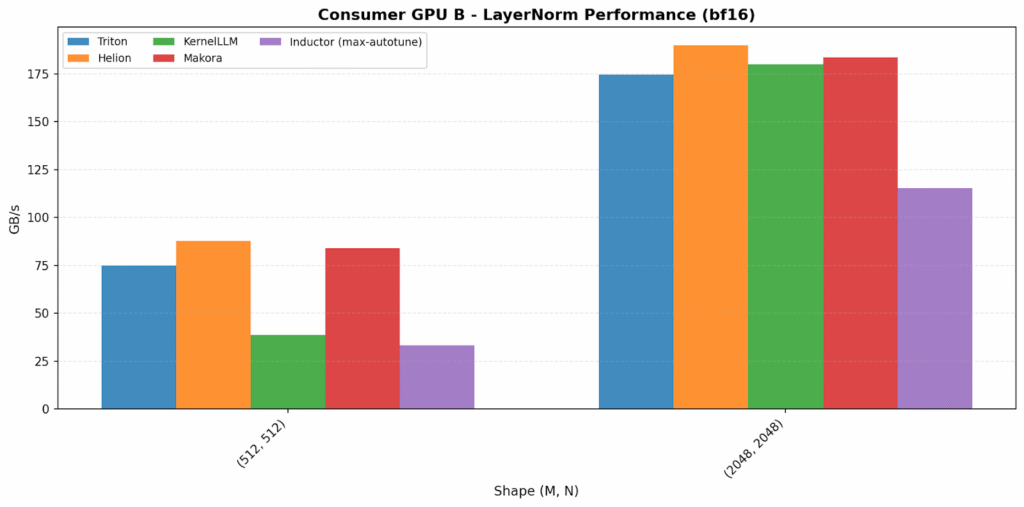
LayerNorm
The bandwidth-bound plots have the widest backend variation. Helion is the standout on data center GPU A, reaching 1949 GB/s (~60% over Triton). On data center GPU B, Makora Generate is the surprising outlier at 982 GB/s (2.6× over others).
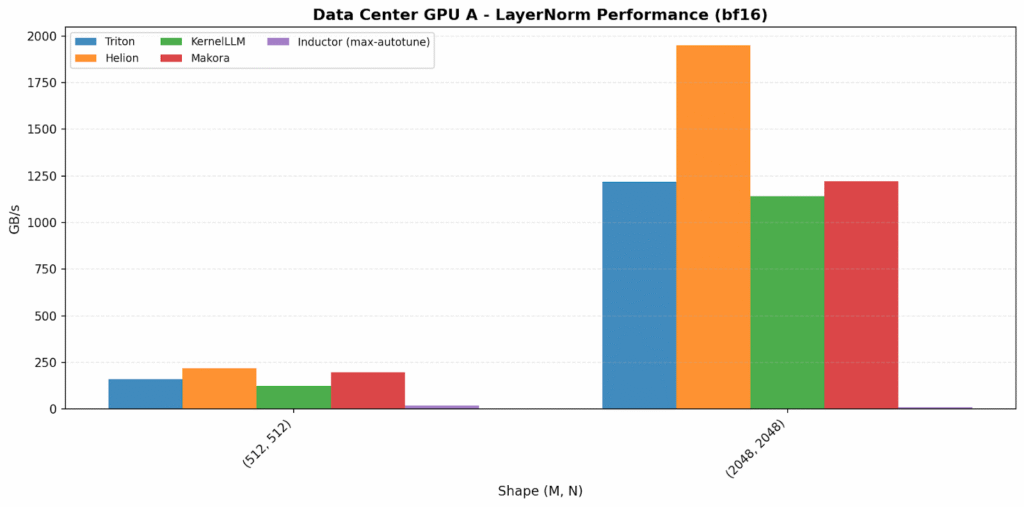
On consumer GPUs, Helion and Makora Generate again achieve the highest bandwidth, outperforming the other backends.
GEMM+GELU
Kernel fusion – combining multiple operations into a single kernel to reduce memory traffic – increases both opportunity and variability. On one data center GPU, Inductor and Helion lead (~375–380 TFLOPS). On the other hand, KernelLLM is best (215 TFLOPS), showing LLM-generated kernels can land on excellent fused implementations.
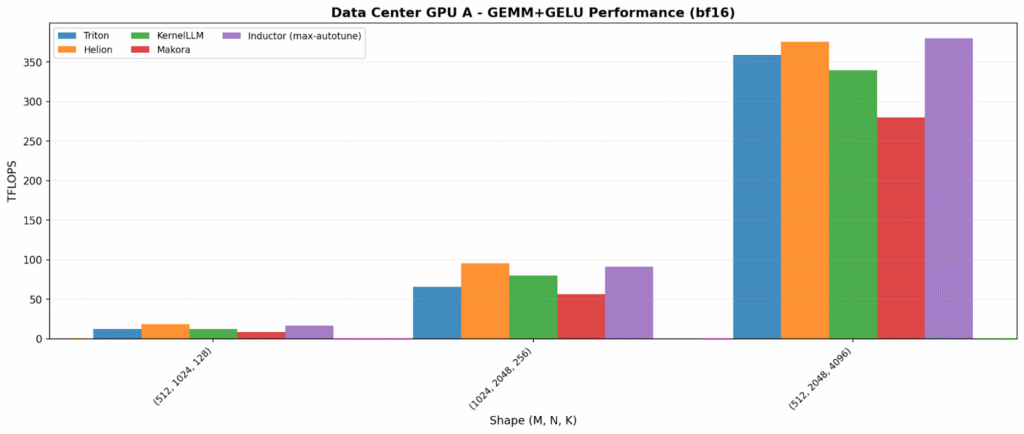
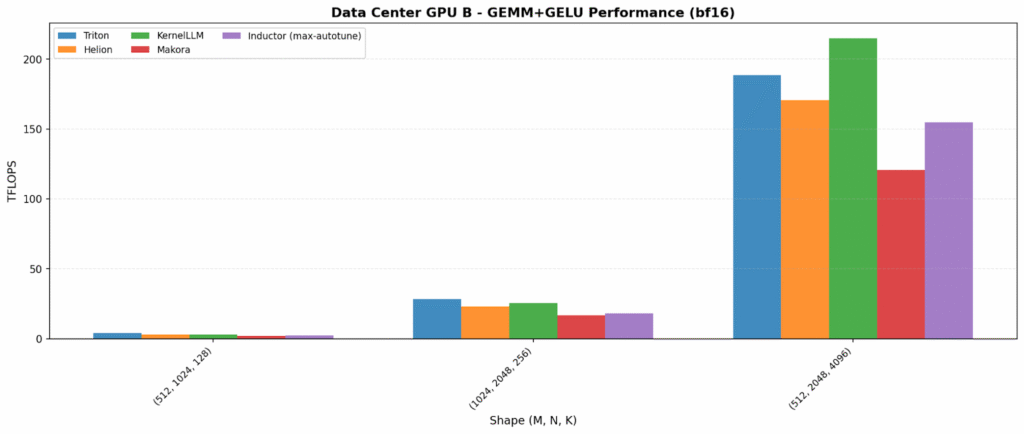
The consumer plots also reveal an important portability flag: Helion is anomalously low on Consumer GPU A (27 TFLOPS vs 150+ for others), suggesting a tuning/path-selection issue on that platform.
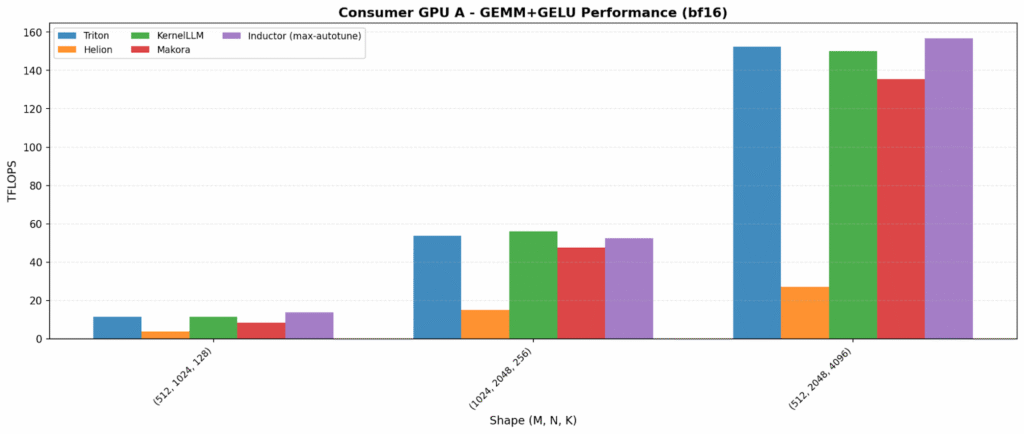
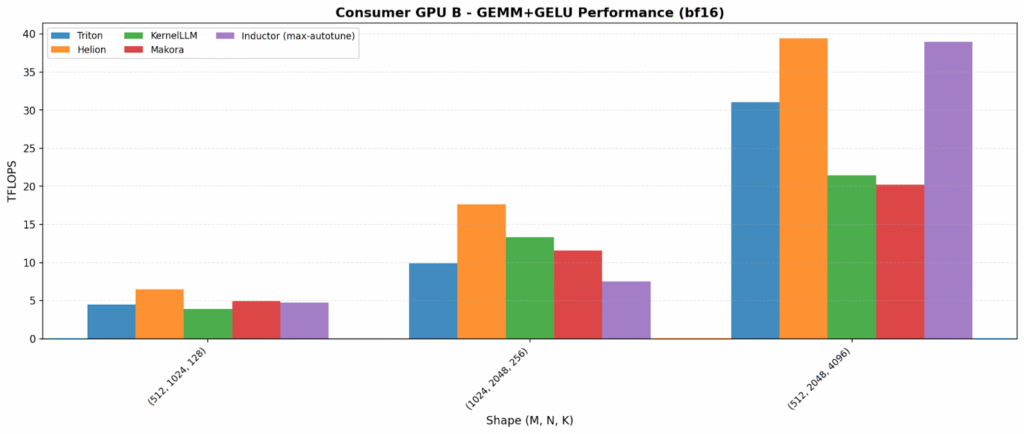
Tuning cost (time-to-results)
The flip side of “portable performance” is time: in our runs, while Inductor’s max-autotune adds compilation latency, it was significantly faster than Helion’s full search space exploration in our tests since Helion’s broader search space meant we often waited several hours to finish the full benchmark sweep. That’s a real trade-off : great peak performance, but a higher up-front tuning bill.
Correctness
Across 852 test configurations, 850/852 passed (99.77%).
The only backend we encountered issues with was Helion for very small shapes on GEMM+GELU on the Consumer and data-center GPU B [10]. At production-relevant sizes, all backends reached 100% correctness.
Score
We summarize trade-offs with a qualitative E/C/P/R/S scorecard: Ease-of-Use, Correctness, Performance, Portability (Runs everywhere), and an overall Score Composite
Legend: 🟢 strong · 🟡 good/caveats · 🟠 variable · 🔴 high friction
| Backend | Ease-of-Use | Correctness | Performance | Portability (Runs everywhere) | Score Composite |
| Hand-written Triton | 🟠 | 🟢 | 🟡 | 🟠 | 🟡 |
| torch.compile / Inductor | 🟢 | 🟢 | 🟢 | 🟢 | 🟢 |
| Helion | 🟡 | 🟡 | 🟢 | 🟡 | 🟡 |
| KernelLLM | 🔴 | 🟡 | 🟠 | 🟠 | 🟠 |
| Makora Generate | 🟢 | 🟢 | 🟠 | 🟡 | 🟡 |
A simple decision guide:
- Start with Inductor if you want a low-friction, production-friendly default that is consistently strong across hardware.
- Use Helion if you can afford offline tuning and want a realistic path to peak performance without living in low-level Triton details.
- Use hand-written Triton when you need maximum control or when the compiler stacks cannot express a critical kernel. Expect iterative tuning work.
- Treat LLM-generated kernels as an accelerator for prototyping and exploration: KernelLLM can work but needs debugging; Makora Generate reduces friction, but performance can be more variable depending on operator and shapes.
Limitations
- We evaluated three operators; results may differ for other kernels (attention, softmax, RMSNorm, etc.) and for backward passes.
- This benchmark emphasizes steady-state kernel performance; end-to-end model speedups depend on graph-level fusion and surrounding operators.
- We used a tutorial-style Triton baseline rather than an expert-per-GPU hand-tuned implementation; that is intentional for a ‘what should I try first?’ comparison.
Reproducibility
The full benchmark, prompts, and JSON outputs are available in the companion repository. The harness uses TritonBench thru Helion benchmark and runs the same operator definitions across backends with consistent warmup/repeat settings.
Companion repository: https://github.com/LironKesem/KernelGeneration
References
1. Triton: Introducing Triton: Open-source GPU programming for neural networks https://openai.com/index/triton/
2. TorchInductor: https://docs.pytorch.org/docs/stable/torch.compiler.html
3 . Helion: A High-Level DSL for Performant and Portable ML Kernels (PyTorch blog) – https://pytorch.org/blog/helion/
4. KernelLLM (Hugging Face model card) – https://huggingface.co/facebook/KernelLLM
5. Makora Generate (workflow overview) – https://makora.com/blog/introducing-makogenerate-ai-powered-gpu-kernel-generation-in-under-60-seconds
6. Triton tutorial MatMul kernel – https://triton-lang.org/main/getting-started/tutorials/03-matrix-multiplication.html
7. Triton tutorial LayerNorm kernel – https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html
8. TritonBench (benchmark harness) – https://github.com/meta-pytorch/tritonbench
9. Repository – https://github.com/LironKesem/KernelGeneration10. Issue with Helion bf16_gemm_gelu (small matrix): https://github.com/pytorch/helion/issues/1342