
Imagine this: you’re building an AI assistant that can book flights, summarize documents, analyze spreadsheets, and schedule meetings. You give it access to dozens – or even hundreds – of tools and APIs. But instead of becoming smarter, it gets confused. It picks the wrong tool, fails to act, or simply hallucinates an answer.
Why? LLMs, as powerful as they are, can only handle so much context at once. This is similar to the well-known challenge that classic RAG (Retrieval-Augmented Generation) addresses: when trying to answer knowledge-intensive questions, models can’t ingest the entire document corpus at once, so we retrieve only the most relevant snippets. Feeding all available tools into a single prompt overwhelms the model and degrades its performance. What if there was a better way to help the AI pick exactly the right tool, at the right time?
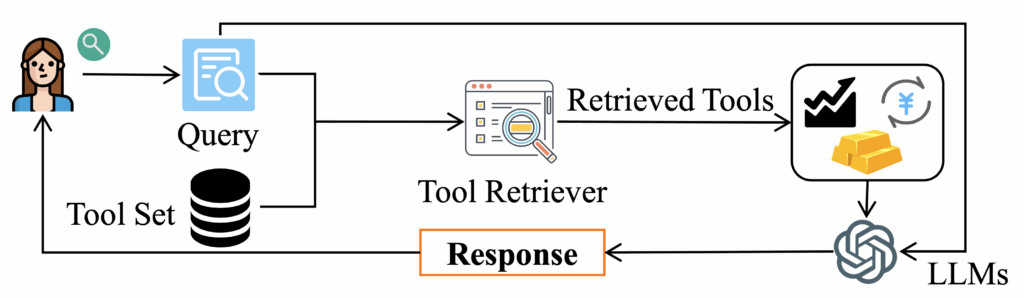
That’s where Tool RAG comes in. Instead of showing the LLM every possible tool, we first retrieve the most relevant ones based on the user’s intent, and only then present them to the model. This approach not only streamlines the model’s reasoning, it dramatically boosts performance. In fact, recent studies show that intelligent tool retrieval can triple tool invocation accuracy while reducing prompt length in half.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
Now, you might think: “I only have five tools in my system – I don’t need this”. But even with small, curated toolsets, the cost of a mistake in identifying the right tool can be enormous. Imagine a financial advisor chatbot used by a bank to assist customers. It has access to just a few tools: one for retrieving account balances, one for transferring funds, one for analyzing investment portfolios, one for flagging suspicious activity, and a few more. If a customer says, “I noticed a weird charge and want to move my money,” the assistant needs to first use the transaction review tool, then alert fraud detection, and only afterwards suggest a funds transfer. Picking the wrong tool sequence could result in missing a fraud report or initiating an unauthorized transfer. Even with just a few tools, the stakes are high, and smart retrieval makes all the difference.
In this post, we’ll break down what Tool RAG is, how it builds on classic RAG, and why we believe Tool RAG is the future of AI agents. Whether you’re a developer, a machine learning engineer, or a product owner thinking about automation, this is a topic that should be on your radar now – not later.
The Problem: Tools Are Powerful—But Hard to Scale
Large language models (LLMs) have made remarkable strides in understanding and generating language. But to truly be useful in the real world beyond simply answering questions, they need to be able to act. This is where tools come in. A tool might be a calculator, a calendar API, a web search endpoint, a SQL query engine, or a company-specific service. Tools allow LLMs to access external data, perform actions, and accomplish complex tasks that go far beyond the model’s internal knowledge.
We’ve seen this in action – all major closed and open-source models and agentic frameworks include the ability to use tools.
A major inflection point came with the introduction of Anthropic’s Model Context Protocol (MCP) in late 2024. MCP established a standardized schema for describing tools and their capabilities, enabling LLMs to discover and understand tools more effectively. Today, all major models and agentic frameworks, both closed and open source, have the ability to use tools.
However, as we move into enterprise-scale use cases, the number of tools quickly grows into the dozens, hundreds, or even thousands. Giving the model access to all of them at once simply doesn’t scale. The model’s context window gets overloaded. It struggles to distinguish between similar tools. Hallucinations increase, and overall performance degrades.Enter Tool RAG, a novel approach that emerged as a solution to the tool scaling problem. Just as classic RAG retrieves only the most relevant knowledge snippets from a large corpus, Tool RAG retrieves only the most relevant tools from a large registry. This avoids the pitfalls of overloading the model with irrelevant options, and allows it to focus on the best tools for the user’s query. In effect, Tool RAG transforms LLMs into intelligent, actionable agents that can operate in dynamic, tool-rich environments.
Tool RAG: A Natural Evolution of Classic RAG
Classic RAG changed how we build question-answering systems. Instead of relying only on a model’s internal knowledge, we retrieve relevant documents and inject them into the prompt, enabling the model to respond with grounded, up-to-date information.
Tool RAG works the same way – but instead of retrieving documents, we retrieve tools. When a user query comes in, we first semantically search a database of tool descriptions, API schemas, and usage patterns. We select the most relevant ones and present only those to the LLM. The model then decides which tool(s) to call and how. This simple idea unlocks scalable, robust agentic AI.
Just like classic RAG, Tool RAG can benefit from a broad array of enhancements. Dense and hybrid retrieval methods (combining semantic embeddings with keyword-based or structured retrieval) can improve both recall and precision of tool selection. LLM-assisted reranking, where a dedicated model can modify the order in which the tool candidates are presented to the main LLM, improves the quality of final selection. Query rewriting allows the model to transform the user request into a more effective retrieval query, especially useful for ambiguous or multi-intent inputs. Feedback loops, where tool outcomes are monitored to refine future retrieval or reranking steps (for example, if a tool fails or returns a null result, that experience can inform the retriever), are also beneficial, along with many other techniques and optimizations inherited from document RAG.
In essence, Tool RAG doesn’t just extend classic RAG – it inherits its best practices while addressing an entirely new challenge: how to turn language understanding into intelligent action.
How Mature Is Tool RAG in 2025?
Considerable progress has been made in Tool RAG since the emergence of the concept about two years ago. While the conceptual breakthrough is well underway, much of what currently exists is still at the prototype or academic benchmark stage rather than fully packaged, plug-and-play software. Tool RAG is not yet a mature ecosystem—but it’s evolving quickly.
Most of the current solutions come from research labs and universities, and they tackle different slices of the tool selection problem. Anthropic’s RAG-MCP demonstrated that even the basic retrieval strategy can boost tool selection accuracy from 13% to 43% in a large toolset while dramatically cutting prompt size. Projects like Tool2vec, Toolshed and Amazon’s recent work explore the impact of incremental improvements to this basic strategy, such as embedding example queries instead of the tool descriptions, rewriting user requests into retrieval queries, reranking the fetched results, and so on.
More sophisticated approaches leverage the intricate collaborative relationships between tools. For example, COLT proposes a solution based on contrastive learning and graph neural networks, and Graph RAG-Tool Fusion constructs dedicated knowledge graphs to represent the inter-tool relation information.
Some works introduce compelling alternatives to the core Tool RAG idea. Gorilla, developed at Berkeley, is an LLM fine-tuned specifically to use a large number (over 1,600) of tools. It outperformed GPT-4 on API usage benchmarks. MCP-Zero implements a concept similar to agentic RAG, where the agent is the one to initiate tool discovery instead of passively reading the available tool definitions from the prompt.
While all of these projects contribute valuable pieces to the puzzle, they still need custom engineering to be useful in production. We are yet to see end-to-end, robust, production-ready frameworks that can support thousands of tools with high precision and recall are rare. The field is clearly transitioning from research to practice, and we are now at the tipping point where prototypes are being productized. And that is a huge opportunity.
What’s Holding Us Back: The Hard Problems
Despite the rapid progress of Tool RAG, a number of important challenges still stand between today’s research prototypes and tomorrow’s production-grade AI agents. Many of these challenges echo the same issues faced by early document-based RAG systems. Others are unique to tools, because tools require not just selection, but execution and validation.
One of the biggest hurdles is retrieval quality at scale. As toolsets grow into the hundreds or thousands, false negatives become a serious problem. While vector search over tool descriptions gets us part of the way, it often struggles with complex or ambiguous queries. Simple similarity matching doesn’t always surface the right tool, especially when tools are described inconsistently or in overly generic terms, and advanced techniques are needed. False positives are also a concern, as models may pick tools that sound relevant but don’t quite match the user’s intent.
Another challenge is tool compatibility. Even if you retrieve the “right” tool, the model has to use it correctly. That means calling it with valid arguments, in the right format, and for the right kind of task. Without a validation layer, this step is fragile. Some systems are experimenting with test executions or schema checks before committing to a tool call, but this area is still underdeveloped.
Safety is another major concern. Autonomous agents that can use tools are powerful, but also potentially dangerous. If an AI is allowed to take real-world actions, it needs guardrails: permission controls, audit logs, sandboxes, and fallback behavior when things go wrong. Tool RAG introduces the opportunity for greater control, but it also demands more careful system design.
Finally, there’s the problem of multi-step reasoning. Real-world tasks often require chaining tools together – querying a database, filtering results, generating a report, sending a message. Most Tool RAG systems today operate at the level of single-tool calls. Emerging research is starting to explore multi-step workflows, but it remains an open frontier.
In short: we have strong foundations, but there’s still a lot to figure out. Tool RAG is already good at narrowing down options. Now it needs to get better at executing reliably, working safely, and thinking multiple steps ahead.
Looking Ahead: What’s Next?
We’re still in the early days. But with new frameworks, improved retrieval algorithms, and emerging standards like MCP, the pace is accelerating.
We expect Tool RAG to become a core component of every mature AI agent framework in the near future.
Whether you’re building a customer support bot, a business intelligence assistant, or a general-purpose workflow agent – retrieving the right tool will be just as important as retrieving the right knowledge.
Our team aims to explore and build a stable, production-ready Tool RAG solution designed for real-world, enterprise-scale deployments. In our next blog post, we are looking forward to sharing the technical architecture of our Tool RAG system and showing how you can start integrating it into your own projects. Stay tuned!
[Update 05-FEB-2026] Our Tool RAG library, ToolScope, is now available on Github and PyPI. Make sure to check it out!