
Today’s AI environment is experiencing a surge in specialized Large Language Models (LLMs), each possessing unique abilities and strengths123: Some are strong in reasoning and mathematics, while others may excel in creative writing. Yet most applications resort to a “one-size-fits-all” approach, routing all user requests to a general-purpose model and potentially squandering opportunities for improved performance, cost efficiency, and user experience.
In Red Hat’s Emerging Technologies, we believe the ideal approach would route requests to the best model for each specific task, effectively utilizing different yet specialized models based on their capabilities. Furthermore, users often request similar information using different phrasing. Such semantic similarity, once identified through advanced natural language processing (NLP) techniques, can be served through cached results to reduce inference latency and costs.
In this blog, we will explore how the LLM Semantic Router provides a structured solution to this challenge. We’ll demonstrate how it intelligently directs incoming requests to the most appropriate LLM models in a managed pool, focusing on the semantic features of request content, enabling performance improvements, cost savings, enhanced caching capabilities, and privacy protection through automated personal identification information (PII) detection and policy enforcement.
Challenges with current LLM deployments
Consider a typical scenario where an organization deploys multiple specialized LLMs. They might have models optimized for mathematical reasoning, creative writing, domain-specific knowledge, and general conversation. Currently, most systems route all requests to a single general-purpose model, missing opportunities to leverage the specialized capabilities of purpose-built models.
This monolithic approach leads to several inefficiencies:
- Suboptimal performance: May result when LLM requests are not routed to the most suitable models (for example, sending math problems to a creative writing model or creative tasks to a model optimized for mathematical reasoning). Such mismatches can lead to poor user satisfaction.
- Higher costs: Likewise, complex models may be used for simple queries that smaller, more efficient models could process
- Missed caching opportunities: Semantically similar queries processed repeatedly instead of leveraging cached responses
- Compliance: Personally Identifiable Information (PII) must not be allowed in LLM request content to prevent private sensitive information from being exposed to public models.
Intelligent request routing with LLM Semantic Router
We are making progress to address the above issues in the vLLM Semantic Router project, now hosted under vllm-project GitHub Organization.
The LLM Semantic Router introduces several key innovations:
Semantic understanding with BERT
The router uses bidirectional encoder representations from transformers (BERT) models to understand the semantic meaning of incoming requests, in the following sequence:
- The Envoy gateway with the semantic processor ExtProc receives user request for LLM inference service
- The semantic processor retrieves the user prompt from the request
- The semantic process converts the prompt into embeddings, i.e., the numerical vector representation, using the BERT model that is specified in the configuration
- The embeddings are compared to the task vectors to identify the nature of the task
- Then the LLM model that is associated with the task is selected to serve this user request.
Category-based model configuration
The LLM model performance of each category is based on the MMLU-Pro benchmark. The benchmark evaluates the LLM’s results on 14 categories and gives a score of how many questions are successfully answered in each category. The scores range from 0 to 1.0, the higher the stronger performance of the model.
Here’s how to configure model selection based on the categories, based on the sample configuration file. The scores are from the MMLU-Pro benchmark results.
# Category classifier configuration classifier: category_model: model_id: "HuaminChen/category_classifier_linear_model" # Huggingface model used in the category classification threshold: 0.6 # Confidence threshold for category classification use_cpu: true category_mapping_path: "config/category_mapping.json" # Category definitions with model scoring categories: - name: math model_scores: - model: phi4 score: 1.0 # Best for mathematical reasoning - model: mistral-small3.1 score: 0.8 # Good alternative - model: gemma3:27b score: 0.6 # Acceptable fallback - name: other model_scores: - model: gemma3:27b score: 0.8 # Best general-purpose model - model: phi4 score: 0.6 # Good reasoning capabilities - model: mistral-small3.1 score: 0.6 # Balanced performance # Default model when no classification is possible default_model: mistral-small3.1
Model selection in action: Real-world examples
Let’s examine how the router routes different types of content to appropriate models:
Example 1: Mathematical query
curl -X POST http://localhost:8801/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "auto",
"messages": [
{
"role": "user",
"content": "What is the derivative of f(x) = x³ + 2x² - 5x + 7?"
}
]
}'
Router Processing:
- Content Classification: Router classifies content as “math” category with high confidence
- Model Selection: Selects
phi4 - Routing: Request forwarded to phi4 backend
Example 2: Ambiguous Content (Fallback to Default)
curl -X POST http://localhost:8801/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "auto",
"messages": [
{
"role": "user",
"content": "Hello, how are you today?"
}
]
}'
Router Processing:
- Content Classification: Router cannot classify with sufficient confidence (below threshold)
- Model Selection: Falls back to
default_model: mistral-small3.1 - Routing: Request forwarded to mistral-small3.1 backend
PII detection and privacy protection
This semantic router has a comprehensive PII detection and policy enforcement system. It employs a fine tuned BERT-based PII classifier that automatically scans incoming requests for various types of personally identifiable information, including:
- Personal Information: Names, ages, phone numbers
- Financial Data: Credit card numbers, IBAN codes
- Government IDs: Social Security Numbers, US driver’s licenses
- Contact Information: Email addresses, street addresses, ZIP codes
- Digital Identifiers: IP addresses, domain names
- Organizational Data: Company names
When PII detection policy is enabled, the inference request is processed in the following way:
- Content Analysis: The router extracts and analyzes all content from user messages and system prompts
- PII Classification: A fine-tuned BERT model classifies each piece of content, identifying specific PII types with confidence scores
- Policy Evaluation: Detected PII types are checked against model-specific privacy policies
- Routing Decision: Only models that comply with the detected PII constraints are considered for routing
This PII detection policy is useful for hybrid deployment scenarios that use both internally hosted models and public LLM models. Inference requests that contain PII data are redirected to internally hosted models to protect privacy.
Configurable PII policies per model
Organizations can define granular privacy policies for each model in their deployment. Use the same sample config file here.
Here’s how to configure PII policies:
# config/config.yaml model_config: # High-security model - only allows basic contact info phi4: pii_policy: allow_by_default: false # Deny all PII by default pii_types_allowed: ["EMAIL_ADDRESS", "PHONE_NUMBER"] # General-purpose model - more permissive gemma3:27b: pii_policy: allow_by_default: false pii_types_allowed: ["EMAIL_ADDRESS", "PHONE_NUMBER", "ORGANIZATION"] # Restricted model - no PII allowed mistral-small3.1: pii_policy: allow_by_default: false # Empty pii_types_allowed means no PII permitted # PII Classifier Configuration classifier: pii_model: model_id: "HuaminChen/pii_classifier_linear_model" # Huggingface models used in PII classification threshold: 0.7 # Confidence threshold for PII detection use_cpu: true pii_mapping_path: "config/pii_type_mapping.json"
PII detection in action: Real-world examples
Let’s see how the router handles different types of requests.
Example 1: Request with credit card information
curl -X POST http://localhost:8801/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "auto",
"messages": [
{
"role": "user",
"content": "My credit card number is 1234-5678-9012-3456. Can you help me with my account?"
}
]
}'
Router Response:
{
"id": "chatcmpl-pii-violation-1643723400",
"object": "chat.completion",
"created": 1643723400,
"model": "phi4",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "I cannot process this request as it contains personally identifiable information (['CREDIT_CARD']) that is not allowed for the 'phi4' model according to the configured privacy policy. Please remove any sensitive information and try again."
},
"finish_reason": "content_filter"
}]
}
Example 2: Request with allowed PII
curl -X POST http://localhost:8801/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "auto",
"messages": [
{
"role": "user",
"content": "Please send the report to john.doe@company.com"
}
]
}'
Expected Result: Since EMAIL_ADDRESS is in the allowed PII types for most models, the request proceeds normally and is routed to the most appropriate model based on semantic content.
Example 3: Clean request (no PII)
curl -X POST http://localhost:8801/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "auto",
"messages": [
{
"role": "user",
"content": "What is the derivative of x^2 + 3x - 5?"
}
]
}'
Expected Result: No PII detected, request is classified as mathematics content and routed to the model with the highest score for math problems (likely phi4 based on the configuration).
Efficient implementation: The dual-head architecture
To efficiently power both the semantic categorization and PII detection capabilities described earlier, the LLM Semantic Router can implement a Dual-Head Architecture.
This advanced model design is centered around a single DistilBERT base uncased model, serving as a shared foundation for processing incoming requests. Two specialized classification heads are then built upon this common backbone:
- A Sequence Classification Head: This head is responsible for category/topic classification. It analyzes the overall meaning of the request to assign it to a predefined category (e.g., “math”, “general inquiry”), aligning with the semantic understanding processes discussed earlier.
- A Token Classification Head: This head performs PII detection by examining individual tokens (words or sub-words) within the request to identify various types of personally identifiable information, supporting the privacy protection mechanisms.
Semantic caching
An extensible caching system that:
- Caches queries and responses
- Identifies when a new query is semantically similar to one in the cache
- Returns cached responses for similar queries, reducing latency and eliminating unneeded use of backend hardware
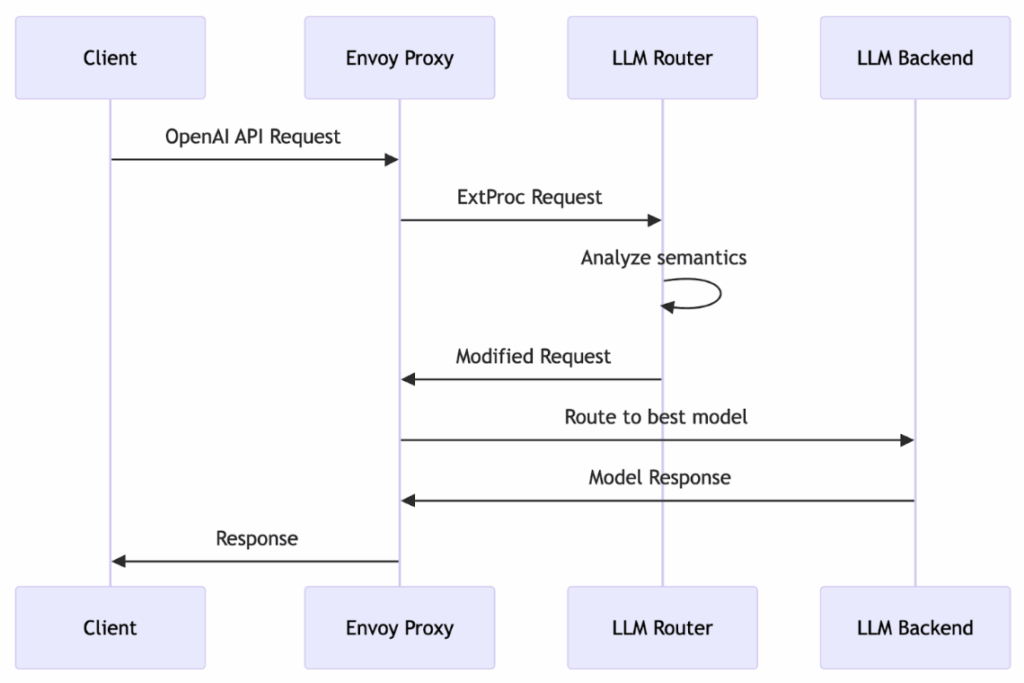
Integration via envoy external processor
The router operates as an Envoy External Processor (ExtProc) filter, allowing it to:
- Intercept incoming API requests
- Examine and modify requests/responses
- Make routing decisions without modifying client code
High-performance Rust+Golang implementation
Implementing semantic processing in Envoy ExtProc for high performance and wide ecosystem adoption is challenging in the following ways:
- Most Envoy ExtProc projects are written in Golang, and standard APIs exist. However, Golang has limited NLP capabilities.
- While Python has a rich ecosystem in NLP and LLM, it is intrinsically not as efficient as Golang in intensive data processing use cases.
To address these challenges, we chose a new architecture that uses Rust and Golang. This architecture leverages:
- Rust Candle Library: Provides efficient BERT embedding generation, similarity matching, and text classification.
- Go FFI Bindings: Allow Golang programs to call the Rust functions directly
- Golang-based ExtProc Server: Handles the communication with Envoy
Conclusion
The Semantic Router for LLM is an extensible solution for routing requests to the correct model. Through BERT embedding’s semantic understanding strength and Envoy ExtProc flexibility, it increases LLM deployment efficiency, performance, and economics. With the growing ecosystem of specialized AI models, smart routing is even more important. Integration with the Gateway API Inference Extension is an emerging development that would take semantic routing strength to Kubernetes/OpenShift-based AI/ML infrastructure and would enable even more efficient AI inference capabilities using llm-d.
- https://crfm.stanford.edu/helm/mmlu/latest/#/leaderboard ↩︎
- https://huggingface.co/spaces/StarscreamDeceptions/Multilingual-MMLU-Benchmark-Leaderboard ↩︎
- https://huggingface.co/spaces/TIGER-Lab/MMLU-Pro ↩︎