
Red Hat’s Office of the CTO is collaborating in the upstream project Tinfoil community to explore pioneering a complete, cloud-native solution for Confidential AI. The community is focused on solving one of the toughest AI security challenges facing the enterprise: Enabling a more secure AI inference experience with highly sensitive private data using proprietary AI models. Our team is helping to foster an open community around this effort, and all of our collaborative work – from the application layer to the underlying infrastructure – will be developed in the open and hosted on GitHub. We encourage everyone, including developers, security researchers, and AI practitioners to join us in building the next generation of trustworthy AI services.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
The challenge for enterprise AI
The era of Large Language Models (LLMs) has fundamentally changed how enterprises interact with data, creating immense value but also a critical security challenge. To get meaningful insights, users would have to feed their most sensitive private data–from proprietary business strategies to personal medical or financial records–into powerful, cloud-hosted LLM services. This creates an immediate and pressing conflict: how can an organization integrate its critical data into an AI service while maintaining absolute confidentiality?
This challenge is equally urgent for the frontier LLM providers themselves. The advanced models they offer are the product of massive investment and represent valuable proprietary intellectual property. If a provider allows their model to be executed on a remote server, how can they prevent it from being inspected, copied, or stolen by privileged administrators, cloud personnel, or other unauthorized parties? The need, therefore, is not just to protect data at rest or in transit, but to enhance the security of both the private data and the proprietary LLM while they are in active use.
The solution to this dual security requirement lies in Confidential Computing, specifically Trusted Execution Environments (TEEs), also known as Secure Enclaves. TEEs use hardware-backed cryptographic technologies to create an isolated, verified execution environment for code and data. Think of a TEE as a digital vault installed directly into the CPU and GPU. Before any sensitive operation begins, a process called attestation cryptographically proves the vault is authentic and untampered. Only then is the private data or proprietary model unlocked for use inside the secure boundary, establishing a foundation of trust that is verifiable, even to those who do not own the underlying hardware.
This hardware-backed approach is what enables true private data inference with proprietary LLMs, and Red Hat is focused on making this an accessible cloud-native capability with solutions like Red Hat OpenShift sandboxed containers.
Model confidentiality and secure loading with attested enclaves
A critical security challenge for running private AI inference is ensuring that a proprietary LLM remains confidential, even when it is physically located on external infrastructure. This challenge is magnified by the typically large size of LLM weights, which must be loaded into memory for processing. Red Hat and Tinfoil are investigating how to combine existing security technologies to solve this problem:
- Protecting Intellectual Property
- Verifying confidentiality
- Secure loading
- Secure GPU inferencing
Protecting proprietary model IP through encryption
The most effective way to address the immense size and proprietary nature of frontier LLM weights is by using encrypted Open Container Initiative (OCI) container images as the packaging and delivery mechanism. Container images are already the industry standard for distributing cloud-native applications. By applying encryption to the container image itself, the entire model artifact becomes inert–a cryptographic payload–until it reaches the attested and verified TEE. This approach maintains that the model’s intellectual property stays at the appropriate level of security throughout its entire journey.

Source: Red Hat
Verifying confidentiality, the power of mutual attestation
Securing the model isn’t just about encrypting the package. It’s about verifying the destination. This verification is achieved through attestation, a cryptographic process that proves the TEE is running the expected hardware and software configuration. As also defined in a recent whitepaper by Anthropic, for truly private data inference with proprietary LLMs, this attestation must be mutual, satisfying two key stakeholders:
- LLM Provider Verification: The provider verifies the TEE is genuine and uncompromised before releasing the private key needed to decrypt the OCI container image carrying the model weights. This helps confirm that their intellectual property is only executed in an environment that meets specified security levels.
- End User Verification: The end user verifies the TEE is configured to run the precise, approved software i.e. the LLM and its inference code, to verify their sensitive input data will be processed according to policy.
The secure loading process, decryption in a secure enclave
The integrity of this process lies in its sequence. Only upon successful mutual attestation is the enclave authorized to pull the encrypted OCI image and the LLM provider’s private key permitted to be securely transferred to the enclave. Crucially, the model weights are then decrypted only inside the TEE’s encrypted memory region. This isolated, hardware-protected decryption guarantees that the proprietary model is never exposed to the host operating system, the hypervisor, or any unauthorized administrator. At this point, the LLM is loaded and ready to accept the end user’s private data for inference.
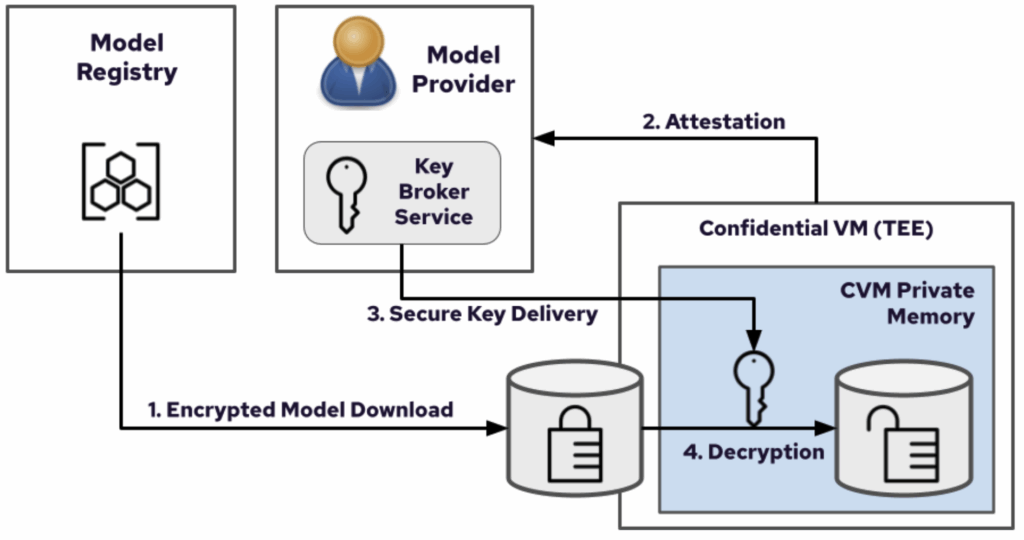
Source: Red Hat
Extending trust to accelerated inference with confidential GPUs
Modern LLMs demand high-performance computing, making Graphics Processing Units (GPUs) essential for fast inference. As a result, protecting the model on the CPU is not enough. The TEE boundary must be extended to the GPU itself. To extend the TEE boundary to the GPU, a protected area called the Compute Protected Region (CPR) is created within the GPU’s memory. This CPR is isolated by hardware firewalls that block any unauthorized access from the host operating system or cloud administrators. Data—including private data and proprietary model weights—is encrypted by the CPU’s TEE before it crosses the connection (PCIe bus) and is only decrypted and loaded into the CPR once the GPU’s secure components have verified the environment. See https://arxiv.org/pdf/2507.02770 for details.
By using GPU hardware with confidential computing capabilities like in the NVIDIA Hopper or Blackwell Architectures, the proprietary LLM weights remain confidential and protected even when loaded onto the high-performance GPUs. This confirms that the entire hardware stack maintains a verified end-to-end trust boundary.

Source: NVIDIA GPU Confidential Computing Demystified–arXiv:2507.02770
Demo video
From specialized hardware to cloud-native abstraction
Successfully implementing private data inference with proprietary LLMs requires bridging the gap between specialized, hardware-backed TEEs and the standardized, scalable environment of the cloud. Kubernetes is the operating model for modern AI workloads, but managing TEEs–with their complex cryptographic attestation and specialized operational constraints–does not easily fit into a containerized workflow.
The need for a cloud-native solution
The challenge for enterprise IT is turning a specialized security capability into a reproducible, easily manageable service. Developers need a way to request a confidential workload without becoming experts in the nuances of hardware security, like setting up Intel TDX or AMD SEV-SNP. They need to deploy their workloads using existing Kubernetes manifests and tools, not bespoke hardware interfaces. The platform needs to handle the heavy lifting of provisioning the secure environment, managing attestation, and key management.
This core infrastructure challenge is addressed by using Red Hat OpenShift sandboxed containers built with Kata Containers, an abstraction layer that brings TEE capabilities directly to the cloud-native infrastructure. By automatically provisioning a Confidential Virtual Machine (CVM) and facilitating the secure container lifecycle–including the critical steps of mutual attestation and decryption of the LLM–sandboxed containers offers a robust, existing building block by making confidential computing a native service within the Kubernetes ecosystem. The open source community, working with Tinfoil, can leverage this foundation to focus on building the higher-level application and privacy features needed to deliver private data inference at true cloud scale.
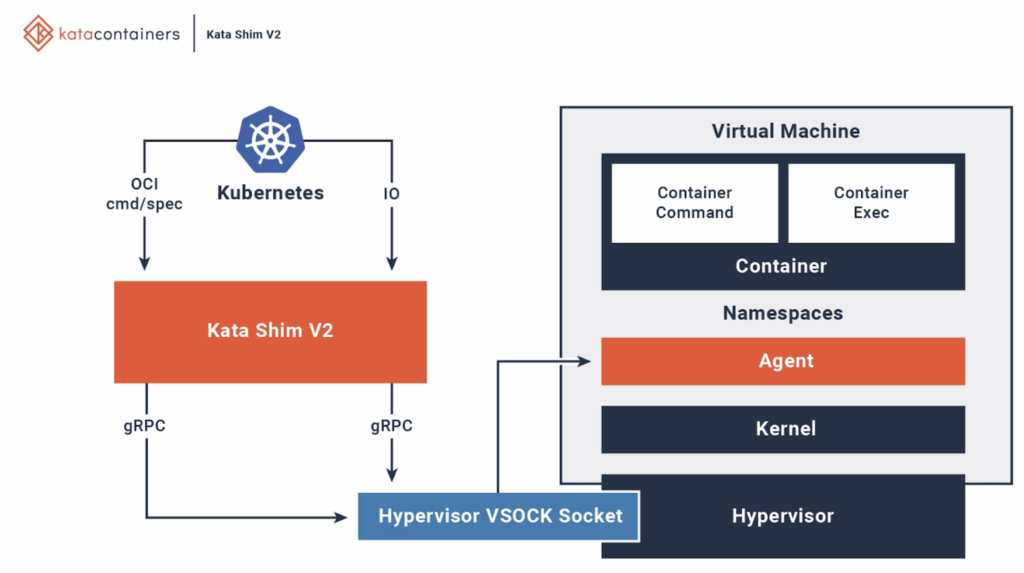
Source: katacontainers.io
New opportunities for LLM providers and users
The adoption of confidential computing is not simply a technical security upgrade; it is a catalyst for new business models and competitive advantage. By establishing hardware-backed trust, enterprises can unlock high-value use cases previously stalled by data privacy and intellectual property (IP) concerns.
Unlocking new business models
Confidential computing provides the verifiable assurance that IT leaders need to move forward with sensitive AI projects. The ability to guarantee data protection in use enables new operational and commercial opportunities:
- Secure Data Collaboration: In regulated industries like finance, pharmaceuticals, and healthcare, organizations can now perform multi-party data analyses without exposing individual datasets to any partner. For example, competing banks can jointly analyze fraud trends without revealing their customers’ private transaction data.
- Accelerated Regulatory Compliance: Meeting stringent data sovereignty and privacy mandates (such as GDPR or industry-specific regulations) becomes straightforward. By proving data isolation at the hardware level, IT teams can simplify their compliance audits and accelerate time-to-market for new confidential services.
- LLM IP Protection and Market Advantage: For model providers, the guaranteed protection of the proprietary model’s encrypted OCI image is paramount. This protection is essential to enable secure, high-value AI-as-a-Service, a capability currently offered by a major public cloud vendor through architectures like Azure AI Confidential Inferencing. By preventing the LLM weights from being decrypted outside the verified TEE, providers can more safely offer their most valuable, state-of-the-art models as a service on public or private cloud infrastructure, maintaining a clear competitive edge.
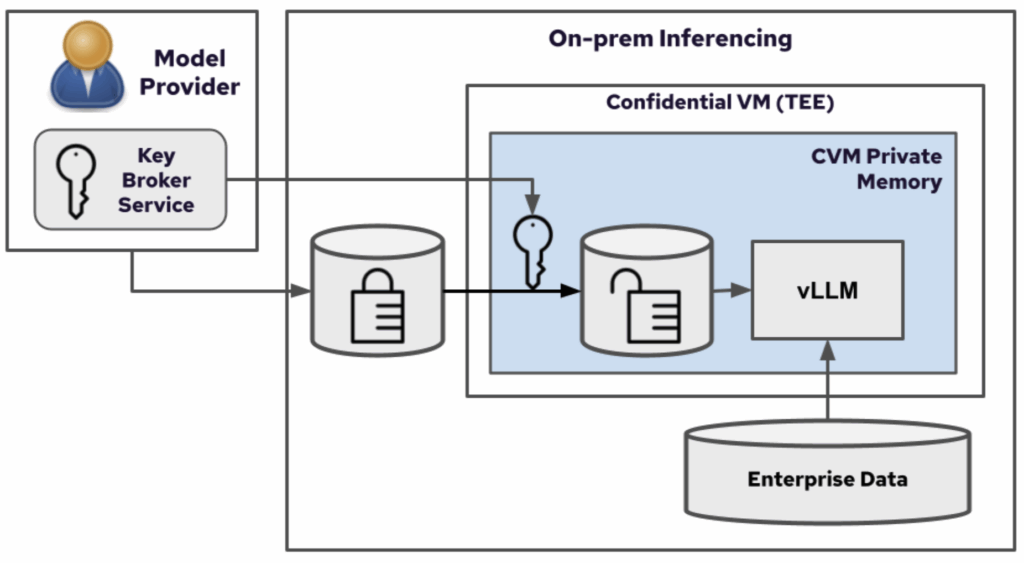
Source: Red Hat
The future of confidential and proprietary AI
The challenge of securing private data inference with proprietary LLMs is one of the greatest obstacles to widespread enterprise AI adoption. Relying on traditional security measures–where data protection ends the moment an application is running–is no longer sufficient for organizations handling sensitive information or valuable intellectual property. Confidential Computing provides the verifiable, hardware-backed solution needed to close this gap.
We are moving past the time when organizations had to choose between using the best AI models and protecting their most sensitive data. The future of security-by-design enterprise AI is being built today, in the open, by the community. We invite you to join our collaborative effort with Tinfoil. Contribute to the open source project (https://github.com/tinfoilsh/coco-inferencing) to help define the next generation of private data inference solutions. To get started with the foundation technologies, you can also explore Red Hat OpenShift sandboxed containers and Red Hat OpenShift AI.
References
Azure AI Confidential Inferencing: Technical Deep-Dive, Mark Russinovich, Microsoft
Confidential Inference Systems Design principles and security risks, Pattern Labs, Anthropic
NVIDIA GPU Confidential Computing Demystified, arXiv:2507.02770