
If you’re working with GPU kernels, you’ve likely encountered Triton – a language and compiler designed to write highly efficient custom GPU kernels. One of Triton’s valuable features is its kernel caching system, which can significantly improve application startup times and reduce unnecessary recompilation.
The goal of this blog post is to explore Triton’s caching mechanism: how it works, what affects it, how different frameworks leverage it, and how you can optimize it for your specific workloads.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
This is article #4 in our series on Triton. To learn more, check out:
- Democratizing AI Accelerators and GPU Kernel Programming using Triton
- Getting started with PyTorch and Triton on AMD GPUs using the Red Hat Universal Base Image
- A container-first approach to Triton development
Here’s a quick demo of what we’ll be discussing in this article:
Why Kernel Caching Matters
Without caching, every time you run a Triton GPU kernel, the system would need to:
- Parse the Triton source code
- Compile to intermediate representations (TTIR, LLIR, etc.)
- Generate target-specific code
- Compile to binary
This process can take significant time, especially for complex kernels, resulting in slower application startup and higher initial memory usage spikes.
Our benchmarks show that with the preloaded Triton cache, startup times improve by approximately 30%.
How Triton’s Cache Works
Cache Key Generation
At the heart of Triton’s caching system is a deterministic process for generating unique cache keys that uniquely identify compiled triton kernels. Let’s examine the components that go into this process:
key = f"{triton_key()}-{src.hash()}-{backend.hash()}-{options.hash()}-{str(sorted(env_vars.items()))}"
hash = hashlib.sha256(key.encode("utf-8")).hexdigest()
This key is derived from:
- Triton Installation Hash (triton_key): Includes Triton version and hashes of core compiler files.
- Source Hash (src.hash()): Based on:
- Kernel function name
- Signature types
- Constant expressions
- Kernel attributes
- Backend Hash (backend.hash()): Identifies the GPU platform and architecture specifics including warp size.
- Options Hash (options.hash()): Compilation options like number of warps.
- Environment Variables: Any cache-invalidating environment variables defined in the CACHE_INVALIDATING_ENV_VARS (e.g., LLVM_IR_ENABLE_DUMP and MLIR_ENABLE_DIAGNOSTICS).
The resulting hash, base32 encoded, determines the directory name in the cache location (by default ~/.triton/cache/).
Cache Storage Structure
The cache is organized as follows and may vary depending on the compilation backend:
~/.triton/cache/ └── [CACHE_KEY]/ ├── [KERNEL_NAME].ttir # Triton IR ├── [KERNEL_NAME].ttgir # Triton GPU IR ├── [KERNEL_NAME].llir # LLVM IR ├── [KERNEL_NAME].ptx # PTX ├── [KERNEL_NAME].cubin # Binary ├── [KERNEL_NAME].amdgcn # AMDGCN ├── [KERNEL_NAME].hsaco # Binary └── [KERNEL_NAME].json # Metadata
Each compiled kernel maintains every stage of the compilation pipeline, along with metadata about the compilation settings.
Cache Validation and Lookup
When a kernel is requested, Triton follows a specific decision flow as shown in the flowchart below:
- Override Check: First, Triton checks if TRITON_KERNEL_OVERRIDE=1 and looks for an override of the compiled kernel with a user-specified IR/ptx/amdgcn in the TRITON_OVERRIDE_DIR directory.
- IR Existence Check: If override is enabled, it verifies if a matching IR file exists for the current kernel.
- Cache Key Computation: If no override exists (or override is disabled), Triton computes a cache key based on the Triton version hash, function signature, constants, GPU backend options, and environment variables.
- Compilation Force Check: Next, it checks if TRITON_ALWAYS_COMPILE=1; if true, it bypasses cache lookup entirely.
- Cache Lookup: If caching is enabled, Triton looks for a matching compiled kernel in the cache.
- Cache Hit or Miss: On a cache hit, it loads the pre-compiled artifacts and executes the kernel; on a miss, it performs full compilation and stores the results.
- Dump Check: Finally, if TRITON_KERNEL_DUMP=1, it duplicates all artifacts to the TRITON_DUMP_DIR directory.
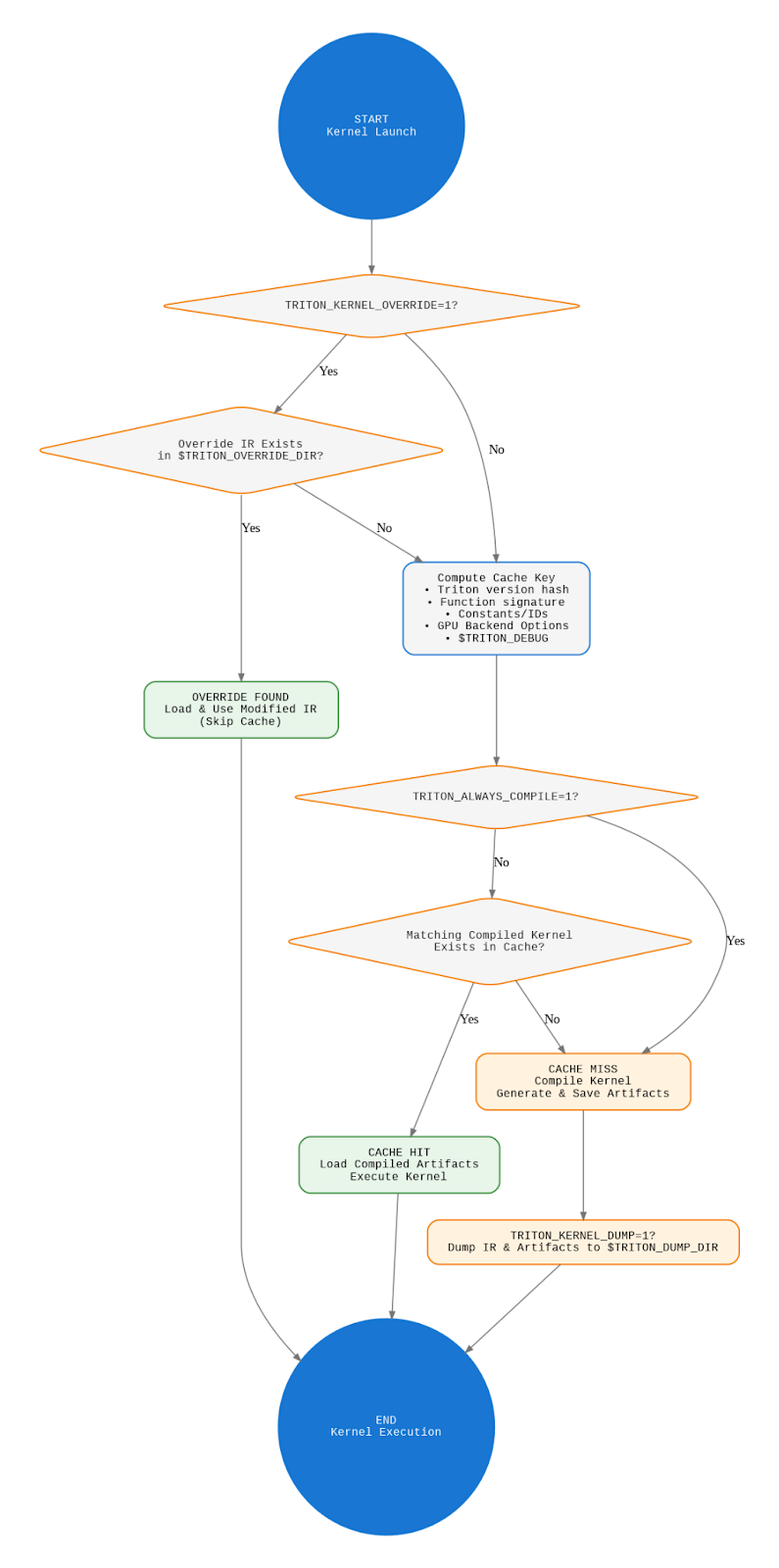
The flowchart illustrates the decision-making process and the various bypass options available to developers working with Triton kernels.
Factors Affecting Cache Generation and Invalidation
Understanding what triggers cache regeneration is important for reliability and performance predictability. By knowing these factors, developers can make informed decisions about when caches might be invalidated and plan accordingly to prevent unexpected compilation overhead during critical application phases:
Source Code Changes: any change to the kernel function, such as function body modifications, signature changes and constant expressions or default values.
Triton Version Updates: upgrading Triton will invalidate the cache, as the triton_key() includes the Triton version and hashes of core files.
Compilation Options Changes: altering any compilation option, such as number of warps and grid size or block dimensions
Environment Variables: several environment variables can affect cache behavior:
| Variable | Default | Purpose |
| TRITON_CACHE_DIR | ~/.triton/cache | Custom cache location |
| TRITON_ALWAYS_COMPILE | 0 | Force recompilation (bypass cache) when set to 1 |
| TRITON_KERNEL_OVERRIDE | 0 | Enable manual kernel IR overrides |
| TRITON_OVERRIDE_DIR | ~/.triton/override/ | Directory for manually overridden kernels |
| TRITON_KERNEL_DUMP | 0 | Enable kernel IR dumping |
| TRITON_DUMP_DIR | ~/.triton/dump/ | Directory for dumped compilation artifacts |
| TRITON_STORE_BINARY_ONLY | 0 | Store only binaries (saves up to ~77% space) |
| TRITON_DEBUG | 0 | Include debug info in cache key (affects hashing) |
GPU Architecture Changes: switching between different GPU architectures or vendors will trigger recompilation, as the target-specific code generation differs.
Hot-Swapping and Implementation Changes
An interesting question is: what happens if you change a kernel’s implementation but keep the same function name and signature?
The answer is that Triton’s caching is content-aware, not just name-aware. The src.hash() function includes the entire function content, ensuring that:
- If you change the implementation but keep the name, a new cache entry is created
- The old cache entry remains but won’t be used for the new implementation
- If a framework explicitly registers binaries with Triton’s cache, it can detect this change since it uses the corresponding hash
This design makes Triton’s cache robust against implementation changes and allows for safe hot-swapping of kernels during development.
Cross-Platform Considerations:
- Cache entries are never shared between platforms
- Moving from different GPU vendor will always trigger full recompilation
- Even changing GPU models within the same vendor may invalidate cache if architectures differ
Benchmark Highlights
Our benchmarks underscore the practical benefits of Triton’s cache:
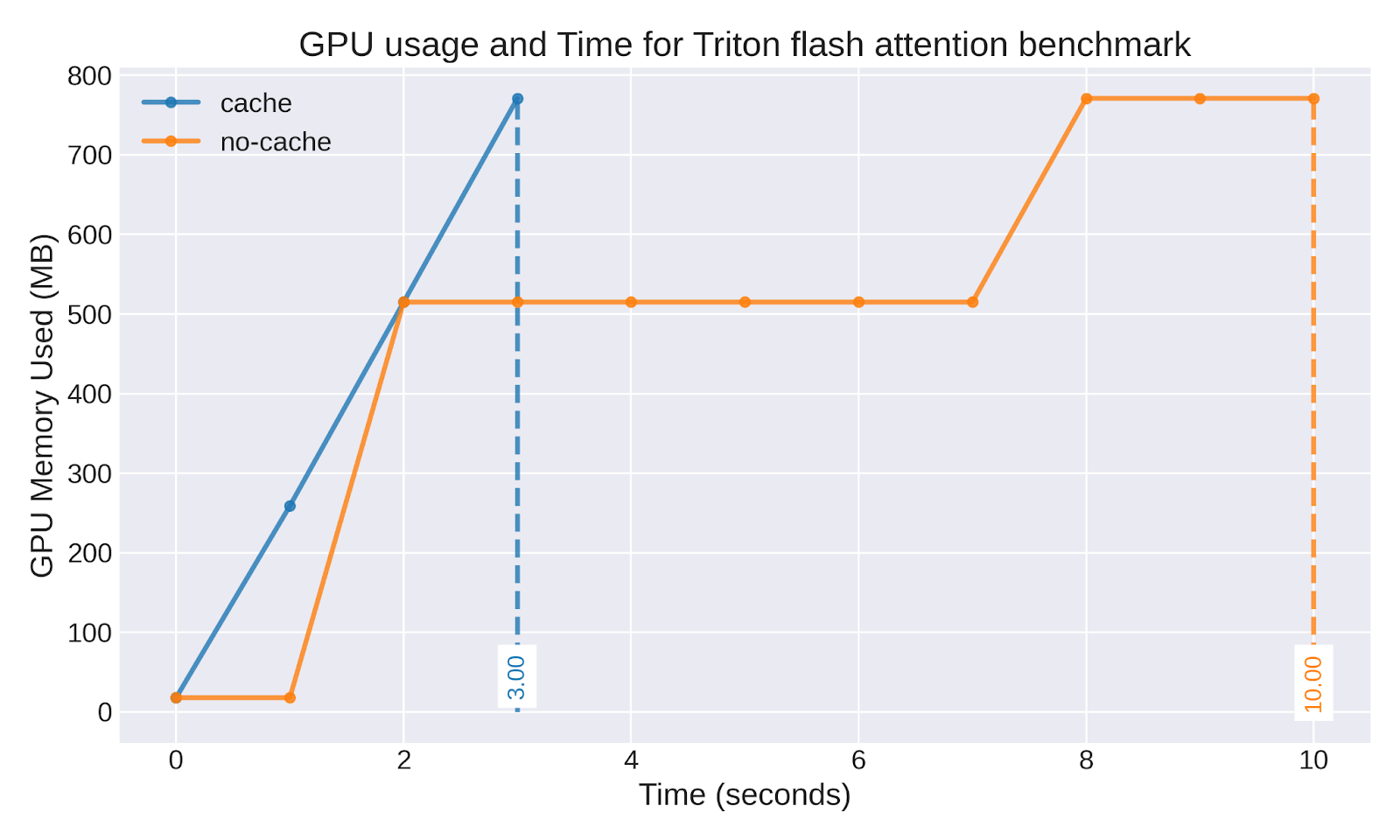
Triton cache significantly improves startup performance
Our key findings:
- Startup Time Reduction: ~30% faster initialization
- Memory Usage Stability: more consistent memory patterns with cached kernels
- Resource Utilization: better GPU resource usage during initial model loading
Advanced Cache Manipulation
For developers needing fine-grained control over Triton’s cache:
Custom Cache Locations : You can specify a custom cache directory:
export TRITON_CACHE_DIR=/path/to/custom/triton/cache
This can be useful for sharing cache between team members and persisting cache across container rebuilds
Kernel Overriding : the TRITON_KERNEL_OVERRIDE feature allows you to substitute specific compilation stages:
export TRITON_KERNEL_OVERRIDE=1
This enables the manual optimization of generated code, testing alternative implementations and debugging specific compilation stages.
Cache Dumping : for inspection and debugging:
export TRITON_KERNEL_DUMP=1
This dumps all intermediate representations to ~/.triton/dump/[HASH]/.
Storage Optimization : If you want to save disk space, you can store only the essential binary files and metadata:
export TRITON_STORE_BINARY_ONLY=1
This reduces stored files to just json (metadata) and .cubin/.hsaco (compiled binaries)
This can save approximately up to 77% of storage space, which is significant when dealing with many kernels.
Conclusion
Triton’s caching system provides significant performance benefits, particularly for applications that repeatedly use the same GPU kernels. By understanding how the cache works and what factors affect it, developers can optimize their inference applications for faster startup times and more consistent performance.
For real-time AI applications, ML inference services, and other latency-sensitive systems, properly leveraging Triton’s cache can make the difference between a sluggish and a responsive user experience.
In future articles, we’ll explore Triton’s powerful autotuning capabilities and the @triton.autotune decorator that lets you benchmark and optimize kernel configurations automatically, further enhancing the performance benefits of the caching system through a smart configuration selection.
Do you want to try our benchmark to compare cache and no-cache kernel runs? Check out the repository here