
Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
Triton1 is a language and compiler for parallel programming. Specifically it is currently a Python-based DSL (Domain Specific Language) along with associated tooling, that enables the writing of efficient custom compute kernels used for implementing DNNs (Deep Neural Networks) and LLMs (Large Language Models), especially when executed on AI accelerators such as GPUs.
The key goals for Triton are:
- Provide a higher layer of GPU2 programming abstraction as compared to alternatives such as CUDA or ROCm. This lowers the barrier for writing efficient GPU programs enabling a wider set of personas (including data scientists, GPU specialists, infrastructure and application developers) to write and optimize GPU programs.
- Provide a hardware and vendor agnostic layer against which GPU programs can be written once and be portable and efficiently executable on multiple different hardware and accelerator hardware platforms including (but not limited to) GPUs, NPUs and CPUs from multiple hardware vendors.
- Provide the ability to use both compiler-initiated optimizations such as shared memory management and developer-initiated optimizations such as fused kernels (explained later in this article) that result in programs almost as efficient and performant as highly tuned manually coded kernels written using vendor specific frameworks such as CUDA.
- Be open source, providing these benefits through an open source community involving a mix of hardware, software and systems vendors within the AI and GPU ecosystem.
Consequently Triton aims to democratize AI infrastructure, accelerate data science developer productivity (i.e., “developer inner loop”), enabling an open architecture for GPU and AI accelerator programming.
The Triton project is currently released as open source by Philippe Tillet and OpenAI under an MIT license (with growing contributions from Meta and others). Red Hat is a strong proponent of Open Source AI technologies and innovations that facilitate a healthy and diverse hardware ecosystem that lowers costs and expands adoption of AI infrastructure solutions. In this blog post, we describe some of the foundational architecture topics in the Triton space and its connection with frameworks such as PyTorch. In subsequent blog posts, we will go into further details including the use of Triton on Red Hat platforms.
Kernels, GPU programming models
Figure 1 below illustrates a simplified view of a basic AI server model with a single multi-core CPU and a single GPU. A GPU kernel is simply the program/ function that runs on the GPU, loaded and invoked on-demand from the program running on the host CPU. A common GPU architecture is that of a SIMD/ SPMD machine that itself contains a number of processors (often referred to as Streaming Multiprocessors or SMs), which then themselves contain multiple smaller compute cores as well as specialized arithmetic units such as Tensor cores.
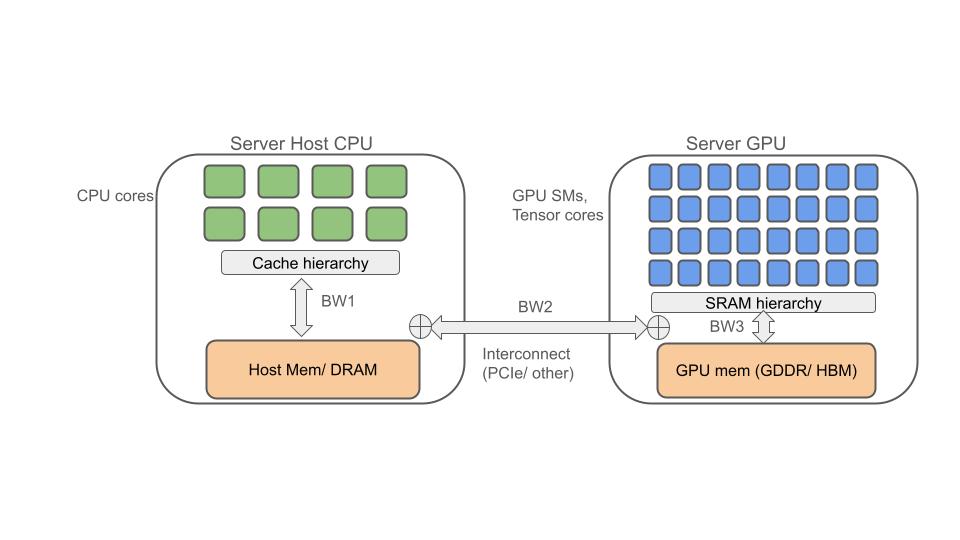
When running a DNN application, the conventional design pattern is that the host CPU launches new GPU kernels onto the GPU, loads a (often very large) set of data into GPU memory, lets the GPU processors execute multiple parallel compute threads on the loaded kernel to perform a set of computations, (usually vector or matrix operations such as matrix multiplications) and then harvests the results back into CPU memory before potentially launching a follow up set of kernels and associated data. Later in this article we see how newer design patterns optimize this. A precise comparison of the vector processing differences between CPUs and GPUs is beyond the scope of this article, save to mention here that general purpose CPUs typically contains 10s or maybe 100s of general purpose compute cores with some amount of vector processing support, whereas GPUs contain 1 or 2 orders of magnitude more special purpose compute threads (e.g., “CUDA threads”) enabling massively parallel processing on large vectors in an SIMD manner and also have special purpose tensor arithmetic units e.g., “tensor cores”.
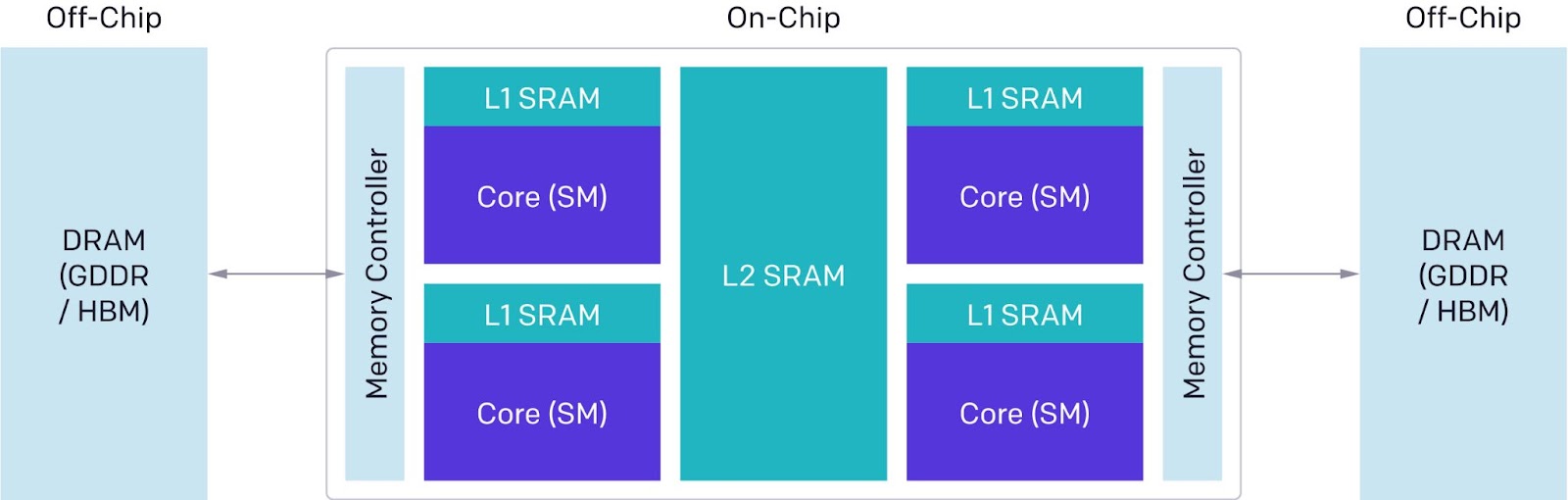
Figure 2 (Ref. article) shows a common abstracted model of a single GPU that can serve for the purpose of this article. This shows that there is a multi-level memory hierarchy even within a single GPU, with an L1 SRAM based cache available to compute threads within a single SM, an L2 SRAM based cache shared by multiple SMs and a global GPU memory (often implemented using a form of DRAM called HBM or High Bandwidth Memory). The SRAM memories support higher throughput and significantly lower access latencies than the global HBM which in turn is faster than CPU DRAM. The exact numbers vary with GPU type but as an example on the H100, HBM memory bandwidth is 3 TB/s, L2 SRAM bandwidth is 12 TB/s and L1 SRAM bandwidth is 33 TB/s.
Newer GPUs continue to add special capabilities that are not shown in the above simplified model, an example being the Tensor Memory Accelerator or TMA. A detailed analysis of the implications of these different memory hierarchies as well as the memory and compute bandwidths of these different components is beyond the scope of this article. The key point to note is that in order to achieve high efficiency and performance for DNNs, it is vital that all the compute cores, SMs and tensor cores of the GPU are kept busy, particularly with large transformer style models. See for example GPUs go brr. Due to advances in GPU hardware design technology, the raw compute capacity of GPU SMs have vastly outpaced the improvements in memory bandwidth implying that the arithmetic cores are often idling if data is not already in the GPU’s SRAM or if there isn’t enough computation designed in per HBM memory fetch.
Due to the mismatch between throughputs of the various compute and memory components, a naively written AI application might well utilize the GPU’s SMs and tensor cores at less than 10% utilization (or sometimes even less than 1% utilization) resulting in both poor overall performance due to increased latency and overall execution time as well as high cost of providing the service given that these expensive GPUs are being utilized at a tiny fraction of their potential compute capacity. See for example “AI and memory wall”. Hence the performance of transformer model based applications is often said to be “memory-bound”, although there can be some scenarios where the performance is “compute-bound” as well.
This is where a well designed GPU kernel can make a huge difference and improve overall performance and efficiency. Industry and academic research in this area has emphasized the need to design kernels that are better tuned to address this compute vs memory performance imbalance. See for example “Data movement is all you need” and “GPUs go brr”.
Having learnt a bit about GPU architecture and the value of well written and tuned GPU kernels, we now come to what types of kernels one could have. CUDA kernels are popular examples of such kernels that are specific to GPUs and AI accelerator hardware from one vendor. Similarly vendors of other AI chips have their own kernel stacks. For instance AMD has open sourced its software platform called ROCm for building compute kernels for its AI accelerators and GPUs.
Triton
With this background perspective, we now come to the Triton kernels. Triton is a DSL for writing GPU kernels that aren’t tied to any one vendor. Additionally, it is architected to have multiple layers of compilers that automate the optimization and tuning needed to address the memory vs compute throughput tradeoff noted above without requiring the kernel developer to do so. This is the primary value of Triton. Using this combination of device-independent front-end compilation and device-dependent backend compilation, it is able to generate near-optimal code for multiple hardware targets ranging from existing accelerators to upcoming accelerator families from Intel, Qualcomm, Meta, Microsoft and more without requiring the kernel developer to know details of or design optimization strategies for each hardware architecture separately.
Effectively, this moves the detailed and often vendor-specific complexity out of the user’s concern and into the vendor’s. This is a more logical design split because vendors are incentivized to highlight their hardware’s differentiating features, and user’s immediately benefit without change to their applications and do not have to build a depth of engineering proficiency in GPU programming for each model GPU they own. However we are still in an early phase of this technology and should monitor how back-end compiler tuning performance evolves.
Figure 3 below illustrates some of the different ways that Triton could fit into a DNN software stack in combination with a PyTorch framework. Triton can also be used in combination with other frameworks such as TensorFlow.
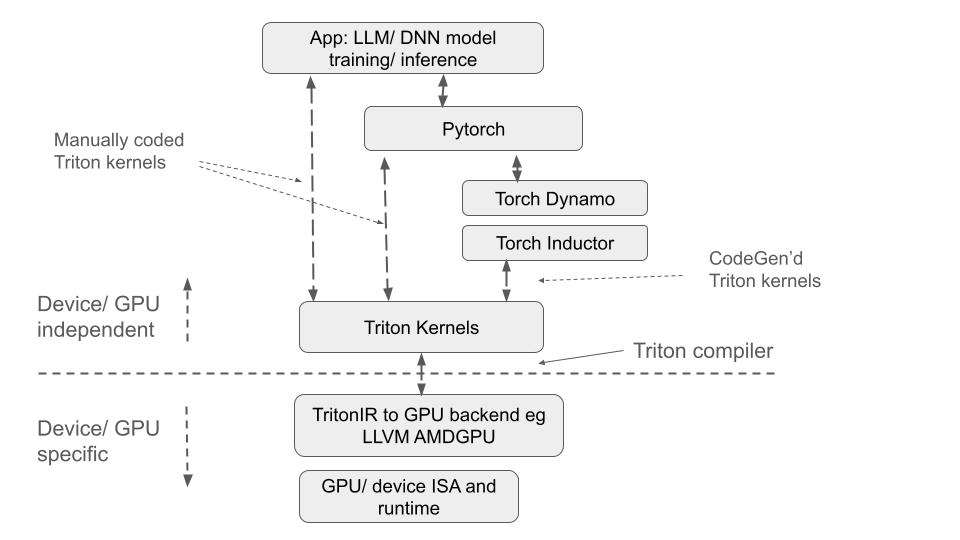
As shown, a DNN application may choose to make direct calls to launch custom Triton kernels (either developer authored or leveraged from open source Triton kernel library repos) to perform certain GPU intensive functions. Alternatively, it may choose to leverage a framework such as PyTorch. Within the PyTorch community, additional frameworks have been recently introduced as part of PyTorch 2.x which can further automate the options for using Triton kernels. For instance by using the Torch Dynamo and Torch Inductor compiler frameworks, Triton kernels can be automatically generated and optimized (including optimizations such as kernel fusions) without the app developer having to manually write, fuse or invoke an existing library of Triton kernels directly. However not all kinds of kernel functions can be automatically generated in this manner with optimal performance, so a mix of generated and manually developed Triton kernels may be used in practice. Several industry and open source projects already exist to develop well designed Triton kernels for various DNN functions. Examples include. LinkedIn’s Liger, Unsloth and sample kernels from the Triton team. We haven’t listed example Triton kernels in this article in order to focus on architecture and analysis. The official Triton repo has some tutorials with kernel examples and explanations that may be referred to.
In any case, once we have the set of well designed Triton kernels, the Triton language compiler performs multiple passes and its own set of optimizations over the kernel code to generate a Triton IR/ Intermediate Representation version of the code. Beyond this point, we enter the realm of device and GPU specific compilations where backend compilers, typically provided by GPU vendors, translate the lower versions of the kernels into GPU specific machine code binaries for eventual execution on the hardware runtimes. Although we have skipped over many of the details, it should be clear to the reader that the overall process involves multiple layers and passes of compilations, code generation and optimizations when going from a high level DNN application all the way to binary code executable on specific hardware devices and GPUs.
Definitions of some key concepts
The prior sections provided some intuition around design issues relevant to Triton, GPU kernels and frameworks such as Pytorch. For completeness it is useful to have a short reference list below of common terminology which the reader may find handy when further researching the literature in this area as well as in advance of our future blog posts on these topics.
Kernel Fusion – Optimization technique of combining multiple compute operations/ kernels into a single GPU kernel, optimizing memory transfers, minimizing latency and improving overall performance by executing related operations together in a single pass on the GPU.
Auto-tuning – A process of automatically optimizing parameters (such as block size, thread count) to find the best-performing configuration for a specific hardware setup and workload, improving execution efficiency.
Arithmetic Intensity – The ratio of computational operations (e.g., floating-point operations) to memory operations (data transfers), indicating how much work is done per memory access.
Conclusion
Triton is an important initiative in the move towards democratizing the use and programming of AI accelerators such as GPUs for Deep Neural Networks. In this article we shared some foundational concepts around this project. In future articles, we will dive into additional Triton details and illustrate its use in enterprise AI platforms from Red Hat.
Acknowledgements: Thanks to Steve Royer (Red Hat), Jeremy Eder (Red Hat), Raffaele Spazzoli (Red Hat), Adnan Aziz (Meta), Adam Goucher (OpenAI), Madhukar Srivatsa (IBM) and Raghu Ganti (IBM) for their valued input and review.
- Not to be confused with NVIDIA’s Triton inference server which is an entirely separate unrelated product. ↩︎
- The term GPU in this article refers to a broad class of AI acceleration processors and these terms are used interchangeably for the purpose of this article. ↩︎