
Zero trust is becoming a norm as organizations look to enhance the security posture of their workloads in cloud environments. A core principle of the zero trust approach is the ability to prove and verify identity for all – whether these entities are inside or outside the organization’s security perimeter. This necessitates solutions that ensure identities are associated with workloads and deployments and access is authorized and granted only when required.
Red Hat OpenShift, as well as upstream Kubernetes, supports methods for assigning identities to applications running on the platform. OpenShift integrates with several cloud providers, such as AWS, GCP and Azure, to consume workload identities provided by the IAM solution of these cloud providers. This becomes a challenge in hybrid cloud environments, however, where each cloud provider has their own identity solution with varying support for workload identity federation, different definitions of workload identities, identity interpretation issues and difficulty establishing universal trust relationships. Even more difficult is operating within environments where there is no support establishing workload identities whatsoever, such as a physical datacenter.
Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
For organizations seeking a single identity framework across their hybrid cloud environments, the SPIFFE (the Secure Production Identity Framework For Everyone) and SPIRE (the SPIFFE Runtime Environment) frameworks provide a single root of trust that can be associated with workloads across on-premise and cloud platforms.
In this article, we will elaborate on how you can integrate the SPIFFE/SPIRE framework with OpenShift to address your workload identity concerns, an introductory use case which demonstrates the benefits of the SPIFFE/SPIRE framework and how the framework can be extended beyond this use case for securing your platform and applications. This article is a collaboration between members from the IBM Research and Red Hat teams to demonstrate upstream SPIFFE/SPIRE capabilities with the OpenShift platform and help solve real-world customer concerns around workload identity.
Cross-cloud workload identity and its challenges
What does “workload identity” really mean? Most cloud platforms come with a trusted identity provider that is integrated with the platform or the cloud infrastructure. This provider consists of a certificate authority, or root of trust, to provision identities for the application workloads running on top of the platform. This means that when an application container running within these environments wants to access a service, it takes that identity which comes in the form of a x509 cert or JWT (JSON Web Token), and presents it to a Policy Enforcement Point which verifies this identity with the Identity Service. Then, based on defined policies, access is either granted or rejected. This process works fine in a single cloud provider environment, but when there are two or more providers in use, there is no common “Trust Domain” to verify the identity as there will likely be different Identity Schemas defined by each of the cloud providers.
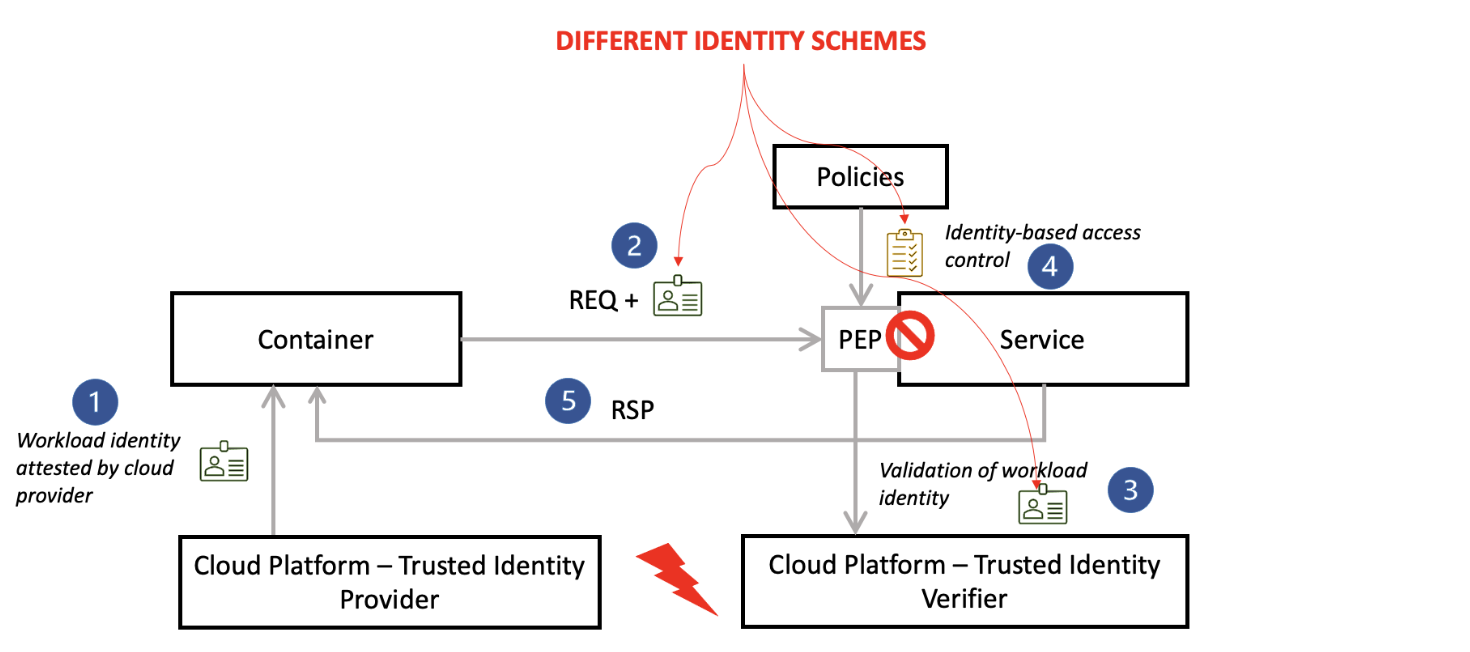
Picture A: Cross-cloud identity challenge with different cloud schemas
Achieving cross-cloud workload identity with SPIRE and Tornjak on OpenShift
Picture A above changes dramatically with the addition of SPIFFE, SPIRE and Tornjak on OpenShift, as reflected in Picture B below. SPIFFE is a Cloud Native Computing Foundation (CNCF) graduated project that defines an identity format and specifies how workloads can securely obtain identities in heterogeneous and dynamic cloud environments. SPIRE, also a CNCF graduated project, provides a production-ready implementation of the SPIFFE standards and enables organization-wide management of SPIFFE identities and identity attestation. It issues and rotates identity tokens and provides a single point of federation using an OpenID Identity Provider (OIDC) discovery service. Refer to the SPIRE documentation for a detailed overview on architecture and concepts. Lastly, Tornjak, a control plane and user interface for SPIRE, defines and presents organization-wide universal workload identity schemes. The Tornjak project was donated to CNCF by IBM.
As the picture below depicts, with SPIFFE and SPIRE deployed, a common schema is now available that is NOT dependent on any specific cloud and uses workload identity instead of hardcoding static keys.

Picture B: Cross-cloud identity with SPIRE and Tornjak on OpenShift
A practical use case with workload identities
With a baseline understanding of SPIFFE, SPIRE and Tornjak, let’s look at a simple use case of workload identity. Picture C below illustrates how a workload in an OpenShift cluster securely accesses a remote S3 bucket in the AWS cloud. Unlike traditional methods involving hardcoded API keys or passwords, AWS policies and roles and utilizing the identity of the workload for managing access will be leveraged. This identity management capability is facilitated by SPIRE for a more secure and scalable approach to access control.
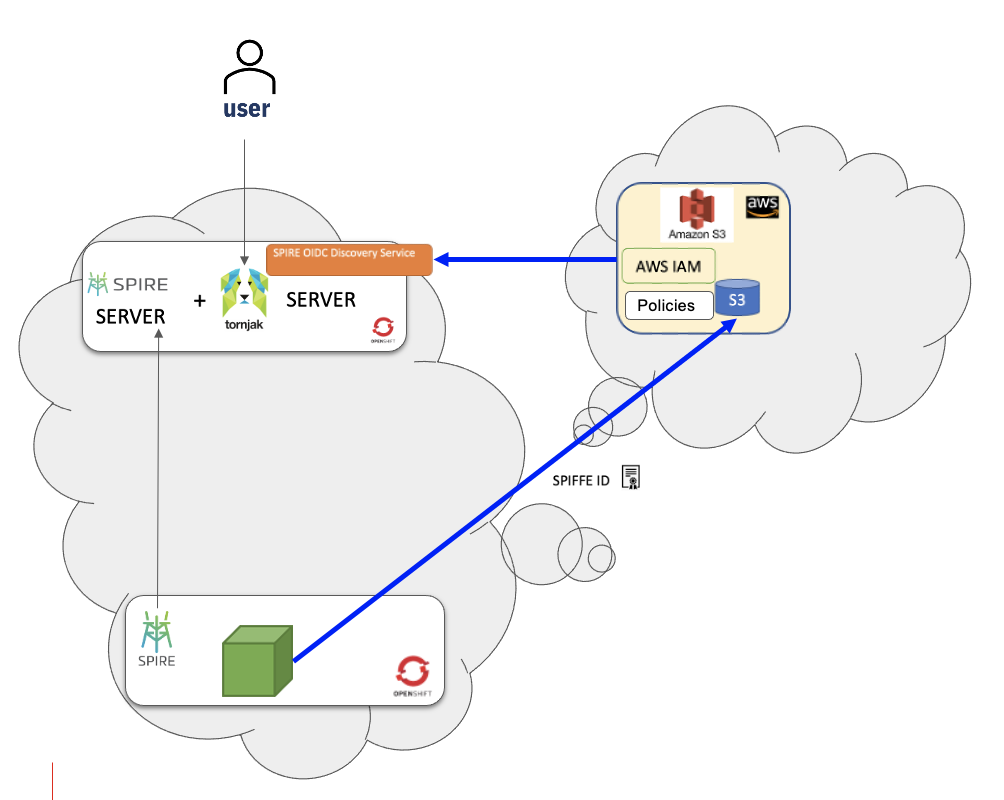
Picture C: Cross-cloud identity with SPIRE and Tornjak on OpenShift
The following are a step-by-step set of instructions on how to achieve the desired workload identity outcomes with SPIRE and Torjnak on OpenShift.
Key components:
A set of Helm charts are available to simplify the installation of SPIRE. The Helm charts will accomplish the following:
- Install SPIRE CustomResourceDefinitions providing APIs for key constructs
- Core SPIRE components
- SPIRE Server: The core server responsible for managing workload identities.
- OIDC Discovery Service: Facilitates OpenID Connect (OIDC) integration for identity verification.
- SPIRE Agents: Deployed on each node hosting workloads. These agents play a crucial role in identity attestation.
Configuration steps:
- Setting up SPIRE: The first phase involves configuring SPIRE to manage workload identities effectively. This includes the deployment of a centralized SPIRE server and SPIRE agents on every working node hosting the desired workloads.
- OIDC integration: Establishing a secure connection between AWS Identity and Access Management (IAM) and SPIRE by configuring IAM to use an OIDC. This integration provides a seamless identity verification process.
- AWS IAM configuration: Defining AWS IAM policies and roles that references the SPIRE OIDC service. This step is pivotal in specifying the characteristics of workloads eligible to access the data stored in the designated S3 bucket.
Prerequisites
The following resources need to be available prior to proceeding.
Cloud resources:
- An OpenShift 4.13 or higher environment (in our example we used IBM Cloud ROKS https://cloud.ibm.com/kubernetes/overview?platformType=openshift )
- The ability to manage AWS IAM
Additional utilities to facilitate the deployment and configuration
- git
- helm
- kubectl or oc
- aws CLI
- openssl
- sed
- envsubst (Included in most Linux distributions and installable on OSX with Homebrew using the
brew install gettextcommand)
SPIRE deployment
With the prerequisites in place, the first step is to clone the Git repository containing the SPIRE Helm charts. A specific tag (0.18.0) tag is specified to protect against future changes of the charts.
Clone supported version (currently the version 0.18.0 contains everything we need)
git clone -b spire-0.18.0 https://github.com/spiffe/helm-charts-hardened.git cd helm-charts-hardened
Namespace for Helm install
Please note that our Helm deployment will use the namespace “spire-mgmt” for the installation only. The actual SPIRE deployment will use the namespace provided by the chart e.g.”spire-server”. During the deployment this namespace will be labeled with “privileged” level. After installation is complete, it can be safely tighten back to “restricted’
SPIRE is using a collection of CRDs. Let’s deploy them first
# deploy the required CRDs: helm upgrade --install --create-namespace -n spire-mgmt spire-crds charts/spire-crds
With the Kubernetes APIs for SPIRE now installed, let’s shift our focus to the deployment of SPIRE itself.
Custom values
In order to install the SPIRE Helm chart for our specific OpenShift environment, we will create a custom Helm values file containing the essential metadata about our deployment (name of our cluster, name of our organization, a country code, and a Trust Domain associated with our deployment, etc). The custom values file also specifies ingress information that is typically used for accessing this cluster externally.
Create a custom values file examples/production/example-my-values.yaml with the following content:
global: spire: clusterName: test-openshift spire-server: ca_subject: country: US organization: Red Hat ingress: enabled: true spiffe-oidc-discovery-provider: enable: true # SPIRE Root CA is currently set to rotate every 2h # this means the thumbprint for OIDC needs to be updated frequently # the quick fix is to disable the TLS on SPIRE: tls: spire: enabled: false ingress: enabled: true # tlsSecret: tls-cert
In the above configuration, for now we will not be using TLS for OIDC access, due to frequently rotating SPIRE root CA.
Obtain the OpenShift apps subdomain for ingress
We will be using the OpenShift application subdomain during our deployment, so let’s capture it now and create environment variable by executing the following command:
export appdomain=$(oc get cm -n openshift-config-managed console-public -o go-template="{{ .data.consoleURL }}" | sed 's@https://@@; s/^[^.]*\.//')
echo $appdomain
We can now use this variable during the installation of the SPIRE Helm charts.
Helm chart installation
One of the benefits of Helm is that it can produce a different set of manifests depending on the input parameters specified. When targeting an IBM Cloud OpenShift deployment, an additional values file examples/openshift/values-ibm-cloud.yaml provides the necessary parameters to enable a successful deployment to the environment. Other OpenShift environments should be able to make use of the standard installation of the chart.
There are parameters that reference $appdomain created above
Standard OpenShift deployment
Deploy a production level SPIRE Server, Agents, CSI driver, with Tornjak on OpenShift using the following command.
helm upgrade --install --create-namespace -n spire-mgmt spire charts/spire --set global.spire.namespaces.create=true \ --set global.openshift=true \ --set global.spire.trustDomain=$appdomain \ --set spire-server.ca_subject.common_name=$appdomain \ --set spire-server.ingress.host=spire-server.$appdomain \ --values examples/production/example-my-values.yaml \ --values examples/production/values.yaml \ --values examples/tornjak/values.yaml \ --values examples/tornjak/values-ingress.yaml \ --render-subchart-notes --debug
IBM Cloud OpenShift deployment
Since IBM Cloud requires a specific configuration as mentioned previously, execute the following command to install the SPIRE Server, Agents, CSI driver, with Tornjak using the following command:
helm upgrade --install --create-namespace -n spire-mgmt spire charts/spire --set global.spire.namespaces.create=true \ --set global.openshift=true \ --set global.spire.trustDomain=$appdomain \ --set spire-server.ca_subject.common_name=$appdomain \ --set spire-server.ingress.host=spire-server.$appdomain \ --values examples/production/example-my-values.yaml \ --values examples/production/values.yaml \ --values examples/tornjak/values.yaml \ --values examples/tornjak/values-ingress.yaml \ --values examples/openshift/values-ibm-cloud.yaml \ --render-subchart-notes --debug
After a successful SPIRE deployment you can tighten up the security level for the spire-server namespace
kubectl label namespace "spire-server" pod-security.kubernetes.io/enforce=restricted --overwrite
Validation
Note: This section requires the following environment variable, defined above:
- appdomain
Once the SPIRE Helm chart has been installed within the OpenShift environment, it is time to test and validate the installation! Let’s start reviewing the available services.
Test the SPIRE deployment elements
First, we can check if Tornjak service is operating correctly. As mentioned earlier, Tornjak is the SPIFFE component representing a control plane for SPIRE in the form of the graphical user interface.
Confirm access to the Tornjak API (backend):
curl https://tornjak-backend.$appdomain "Welcome to the Tornjak Backend!"
If the APIs are accessible, we can verify the Tornjak UI (a React application running in the local browser) can be accessed.
Test access to Tornjak by opening the URL provided in Tornjak-frontend route:
oc get route -n spire-server -l=app.kubernetes.io/name=tornjak-frontend -o jsonpath='https://{ .items[0].spec.host }'
The value should match the following URL:
echo "https://tornjak-frontend.$appdomain"
Open a browser and point at the Tornjak URL obtained previously.
Navigate to the “Tornjak ServerInfo” page and capture the current Trust Domain.
Export the TRUST_DOMAIN environment variable by adding spiffe:// as a prefix similar to the following:
export TRUST_DOMAIN=spiffe://<Trust Domain from ServerInfo Page>
The TRUST_DOMAIN environment variable is used while setting AWS role and policy.
Configure AWS Services
This section outlines the configuration for AWS services that the application, running within the OpenShift environment, will access. In particular, the following will be created:
- An S3 bucket with a sample file
- An Identity Provider of type OIDC pointing to the OIDC Discovery service managed by SPIRE
- An IAM role and policy for access to the S3 bucket
The following steps use the AWS CLI. If you prefer to use the AWS console, follow the steps documented here:
Verify that the AWS CLI is authenticated making use of the steps described here.
Create S3 Bucket
Create an AWS S3 bucket and place a sample message within a test file in the newly created bucket. Since the names of S3 buckets must be unique per region, enter a unique name and export the bucket name and AWS region. The following will generate a unique bucket name and obtain the currently configured AWS region.
export S3_BUCKET=spire-blog-$(shuf -i 2000-65000 -n 1)
export S3_REGION=$(aws configure get region)
# list current buckets:
aws s3api list-buckets --output text
# create a new bucket:
aws s3api create-bucket --bucket $S3_BUCKET --region $S3_REGION --create-bucket-configuration LocationConstraint=$S3_REGION
# Upload a file to the bucket
echo "my secret message" | aws s3 cp - s3://${S3_BUCKET}/test
You can test the bucket using your AWS credentials:
aws s3 cp s3://${S3_BUCKET}/test -
Configure OIDC identity provider
These steps configure AWS IAM to point at OIDC service managed by SPIRE.
First, test the access to our OIDC service installed previously. Use the OIDC route and verify it is returning a valid response by appending the /keys suffix.
export OIDC_SERVER=oidc-discovery.$appdomain curl https://$OIDC_SERVER/keys
A response similar to the following displaying one or many public keys for your OIDC service should be displayed:
{
"keys": [
{
"kty": "RSA",
"kid": "FhpDhZHWzx1md6vQedtGDxFCM16lGJT7",
"alg": "RS256",
"n": "yZAKdBaI-RVkHZg5NhPsPm70JUM3mMl7PfgbFapZQLEheSOM7aQTRKzoYCN0cTzQ70GijzjttLV91-073DW4r2PD7Cu3GAm9TrMTJ_B3YrPPKADdsQXJgVW-PYXAwtVuhmYrFMgJqjIDiapaAcMvAMxh0wyUD3n6rQnr8DIhOtOgHHb_6ZsbAbtYKXupvcj498BdngmpgtKl4mob90Ga9kJvJMnNyJPnV-pdF_gefduSWhjGZN3eJXj4EYgQwZyTA-8Hr89GgyiNTcyFCqvz_msapeKV-8t9tURl8GxWZYtyzemiXShyxkQfc1obMML15QO2kFDmquKTY3mc6387Sw",
"e": "AQAB"
}
]
}
Use this OIDC URL while setting up the Identity Provider for IAM. Capture and parse the certificate into a file called certificate.pem:
# get the OIDC certificate
openssl s_client -servername ${OIDC_SERVER} -showcerts -connect ${OIDC_SERVER}:443 | awk '/BEGIN CERTIFICATE/{data=""; capture=1} capture {data=data $0 ORS} /END CERTIFICATE/{block=data; capture=0} END {print block}' > certificate.pem
Now create a thumbprint for this cert, then create Identity Provider:
# Obtain Certificate Thumbprint
export OIDC_THUMBPRINT=$(openssl x509 -in certificate.pem -fingerprint -sha1 -noout | awk -F= '{print $2}' | sed 's/://g');echo $OIDC_THUMBPRINT
# create Identity Provider type Open Id
aws iam create-open-id-connect-provider --url https://${OIDC_SERVER} --thumbprint-list $OIDC_THUMBPRINT --client-id-list mys3
export OIDC_ARN=`aws iam list-open-id-connect-providers | jq '.OpenIDConnectProviderList[].Arn' | grep $OIDC_SERVER | tr -d '"'`
# Remove the certificate file
rm -f certificate.pem
Create IAM role in AWS
Note: This section requires the following environment variables, defined above:
OIDC_ARNTRUST_DOMAINS3_BUCKET
IAM Policy defines the type of access and actions that can be done on that S3 bucket.
IAM Role defines what workload identities can access this bucket. Instead of static values as below, you can use more complex conditions using wildcards and “ForAllValues:StringLike” as provided in this example.
Create a Role and Policy from these templates:
cat <<EOF >assume-role.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "${OIDC_ARN}"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"${OIDC_SERVER}:aud": "mys3",
"${OIDC_SERVER}:sub": "${TRUST_DOMAIN}/ns/demo/sa/demo"
}
}
}
]
}
EOF
cat <<EOF >iam-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutAccountPublicAccessBlock",
"s3:GetAccountPublicAccessBlock",
"s3:ListAllMyBuckets",
"s3:ListJobs",
"s3:CreateJob",
"s3:ListBucket"
],
"Resource": "*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::${S3_BUCKET}",
"arn:aws:s3:::${S3_BUCKET}/*",
"arn:aws:s3:*:*:job/*"
]
}
]
}
EOF
Then use these files to create actual Role and Policy:
# create AWS IAM role
aws iam create-role --role-name role-${S3_BUCKET} --assume-role-policy-document file://assume-role.json
# create AWS IAM policy
aws iam put-role-policy --role-name role-$S3_BUCKET --policy-name policy-$S3_BUCKET --policy-document file://iam-policy.json
export ROLE_ARN=$(aws iam get-role --role-name role-$S3_BUCKET | jq .Role.Arn | tr -d '"')
echo "ROLE_ARN=`aws iam get-role --role-name role-$S3_BUCKET | jq .Role.Arn | tr -d '"'` *** Use this in the Test step ***"
Connect to S3 from a sample application
Now that SPIFFE/SPIRE has been deployed to OpenShift and the necessary assets have been created within the AWS Cloud, the final step is to deploy a sample application to access the S3 bucket using the identity provided by SPIFFE/SPIRE.
Setup a namespace and permissions
Create a namespace called demo for the sample application:
oc apply -f - <<EOF apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: demo EOF
The SPIFFE Workload API is made available to applications using a CSI driver. Most OpenShift environments use the restricted-v2 SecurityContextConstraint by default. Apply the following policies only when running in IBM Cloud to enable the workload to access the restricted-v2 SCC.
oc apply -f - <<EOF apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: creationTimestamp: null name: system:openshift:scc:restricted-v2-csi rules: - apiGroups: - security.openshift.io resourceNames: - restricted-v2-csi resources: - securitycontextconstraints verbs: - use --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: creationTimestamp: null name: system:openshift:scc:restricted-v2-csi namespace: demo roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:openshift:scc:restricted-v2-csi subjects: - kind: ServiceAccount name: demo namespace: demo EOF
Deploy the sample application
Note: This section requires the following environment variables, defined above:
ROLE_ARNS3_BUCKET
Finally, apply the following to create a Service Account called demo and deploy the sample application.
oc apply -f - <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: demo
namespace: demo
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo
namespace: demo
labels:
app: demo
spec:
replicas: 1
selector:
matchLabels:
app: demo
template:
metadata:
labels:
identity_template: "true"
app: demo
spec:
hostPID: false
hostNetwork: false
dnsPolicy: ClusterFirstWithHostNet
serviceAccountName: demo
containers:
- name: demo
image: docker.io/tsidentity/spire-demo:latest
env:
- name: SPIFFE_ENDPOINT_SOCKET
value: "/spiffe-workload-api/spire-agent.sock"
- name: AWS_ROLE_ARN
value: "${ROLE_ARN}"
- name: S3_AUD
value: "mys3"
- name: "S3_CMD"
value: "aws s3 cp s3://${S3_BUCKET}/test -"
- name: AWS_WEB_IDENTITY_TOKEN_FILE
value: "/tmp/token.jwt"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: false
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
volumeMounts:
- name: spiffe-workload-api
mountPath: /spiffe-workload-api
- name: empty
mountPath: /.aws
volumes:
- name: spiffe-workload-api
csi:
driver: "csi.spiffe.io"
readOnly: true
- name: empty
emptyDir: {}
EOF
Confirm that the application is running within the demo namespace.
# Obtain a list of pods in the demo namespace oc get pods -n demo
Rerun the command until a pod with a “Running” status is achieved.
This demo image contains everything needed to execute the demo including all the required assets including the AWS client, SPIRE client, and also a demoscript for automating the demo.The image for the demo container can be found in this repository.
All the demo variables including the S3 bucket location, the IAM access role etc. are passed as container environmental variables.
Execute the workload
Obtain a shell session in the running ‘demo’ pod:
oc -n demo rsh deployment/demo
This container has a nice demo script that bootstraps all of the required commands for you based on the environment variables injected within the container. To run the script just type:
demo-s3.sh
Move through the demo by continuing to press the space bar.
The result should look similar to the following:
$ /opt/spire/bin/spire-agent api fetch jwt -audience mys3 -socketPath /spiffe-workload-api/spire-agent.sock token(spiffe://mc-ztna-04-9d995c4a8c7c5f281ce13d5467ff6a94-0000.us-east.containers.appdomain.cloud/ns/demo/sa/demo): eyJhbGciOiJSUzI1NiIsImtpZCI6ImxCRXl0d05MMkpibWxGa1JIaHUybzFoTHFxVEtnWWVDIiwidHlwIjoiSl . . . . $ /opt/spire/bin/spire-agent api fetch jwt -audience mys3 -socketPath /spiffe-workload-api/spire-agent.sock | sed -n '2p' | xargs > /tmp/token.jwt $ AWS_ROLE_ARN=arn:aws:iam::203747186855:role/role-mc-ztna-demo AWS_WEB_IDENTITY_TOKEN_FILE=/tmp/token.jwt aws s3 cp s3://mc-ztna-demo/test - my secret message
So, what did the demo script illustrate?
First, the spire-agent CLI was utilized to obtain a JWT token from the Workload API. The Workload API is served via the CSI driver and mounted within the container at /spiffe-workload-api/spire-agent.sock.
Then two environment variables (AWS_ROLE_ARN and AWS_WEB_IDENTITY_TOKEN_FILE) are set based on an injected environment variable and a file representing the output of the obtained JWT token).
Finally, the file stored in the AWS S3 bucket is retrieved and then contents are printed to the screen verifying that we were able to access the content using the SPIFFE/SPIRE framework.
For more information about the demo application, please refer to the following article:
https://github.com/IBM/trusted-service-identity/blob/main/docs/spire-oidc-aws-s3.md
Cleanup
To remove the resources that were created as part of this use case, utilize the steps included in the following sections.
AWS Cleanup
Note: This section requires the following environment variables, defined above:
OIDC_SERVERS3_BUCKET
aws s3 rb s3://$S3_BUCKET --force aws iam delete-role-policy --role-name role-$S3_BUCKET --policy-name policy-$S3_BUCKET aws iam delete-role --role-name role-$S3_BUCKET export OIDC_ARN=`aws iam list-open-id-connect-providers --output=json | jq '.OpenIDConnectProviderList[].Arn' | grep $OIDC_SERVER | tr -d '"'` aws iam delete-open-id-connect-provider --open-id-connect-provider-arn $OIDC_ARN
OpenShift Cleanup
kubectl -n demo delete deploy demo kubectl -n demo delete sa demo kubectl delete ns demo helm --namespace spire-server uninstall spire helm --namespace spire-server uninstall spire-crds kubectl delete ns spire-server
Wrap up and future considerations
We were able to demonstrate a simple use case of cross-cloud access using SPIRE. In future articles, we aim to demonstrate more complex use cases, such as communication between services across multiple public and on-prem cloud platforms. These use cases will leverage SPIRE capabilities, such as nesting and federation for scaling across clouds. We will also demonstrate how SPIRE integrates with Sigstore and provides identities to the worker nodes that are used for signing and deploying images within a trusted software supply chain framework.