
Organizations are dedicating significant resources to produce and distribute top-quality software at a more accelerated pace due to the growing competition in the software market (source). To achieve this goal, they use practices such as Continuous Integration (CI), Continuous Delivery/Continuous Deployment (CD), which aim to speed up software development and delivery while maintaining high standards of quality (source). By automatically building, testing and deploying code changes, CI/CD helps teams deliver software faster and with fewer errors. However, managing CI/CD processes can be complex, especially for large organizations with multiple teams and repositories.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
That’s where the AI4CI project comes in. As a part of this project, we collect open operations data from a variety of sources, including Prow, testgrid, GitHub, and others. By analyzing this data, we aim to improve CI/CD and testing processes and identify bottlenecks that may be slowing down development.
One of the ways we do this is by collecting key performance indicator (KPI) metrics and displaying them on dashboards. These metrics can help software engineering teams track the performance of their CI/CD processes and identify areas where improvements can be made. For example, if a team notices that their build times are consistently longer than expected, they may decide to invest in more powerful build servers or optimize their build scripts.
The time to merge model
In addition to collecting and analyzing data, the AI4CI project also develops machine learning services that can help optimize CI/CD processes. One such service is the time to merge model, which is a classification model that predicts the time it will take for a pull request (PR) to be merged into a repository. By analyzing various features of the PR, such as the size of the PR, the day it was created and the number of commits, the model is able to provide estimates for how long it will take for a PR to be reviewed and merged.
This model can be especially useful for open source projects, where contributions from a wide range of developers are common. By giving contributors an estimate of when their PRs will be reviewed and merged, the time to merge model can help encourage participation and improve the efficiency of the development processes.
Github Action for time to merge
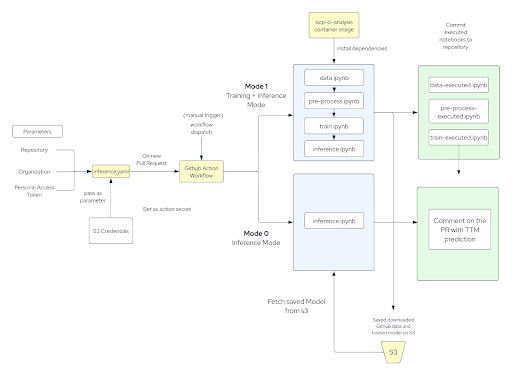
To make it easier for users to integrate the time to merge model with their own repositories, it is made available as a Github Action. Leveraging GitHub-hosted runners, users can train a custom model for their GitHub repositories of interest and integrate this tool with repositories within their community.
GitHub Actions is a powerful tool that allows developers to automate their workflows and build, test and deploy their projects. It is integrated into the GitHub platform and can be used to trigger actions based on events that occur within a repository, such as the opening of a new PR. The time to merge GitHub Action gets triggered automatically on a new PR and the training action on a repository can also be triggered on-demand. As a new PR is opened, the action is triggered and the workflow begins.
The training workflow for the time to merge tool consists of several steps that are carried out in sequence. The first step collects data from historical PRs of the repository using the GitHub API. The next step performs feature engineering, which involves automatically creating and selecting features that will be most useful for training the model and making accurate predictions. Once the important features have been identified, the next step in the workflow trains the classifier. This involves using machine learning (ML) algorithms to find patterns in the data and build a model that can make predictions about the time it will take to merge new PRs. After the model has been trained, the model is able to make predictions about the time it will take to merge new PRs on the repository with a certain confidence level.
Use this tool for your own repository
To use the Github Action tool available on the GitHub Marketplace for your own repository and train the model, you need the following:
Pre-requisites:
- S3 bucket credentials: You will need an S3 bucket to store the data and the model generated as a part of the training process.
- Personal Access Token: You need a personal access token to trigger the workflow and download github data. You can generate that by going here.
Step 1
Once you have the prerequisites in place, add your S3 credentials to your repository action secrets. In order to do that, go to your repository “Settings” -> “Security” -> “Secrets” -> “Actions” -> “New Repository Secret” and add secrets for S3_BUCKET, S3_ENDPOINT_URL, AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, your personal access token as your GITHUB_TOKEN, the prefix/folder where you want to store the data on the S3 bucket as CEPH_BUCKET_PREFIX, and the GitHub repository that you want to train the model on and the organization it belongs to as REPO and ORG.
Step 2
To use this Github Action, you would need to first train your time to merge model and then use it on new PRs on your repository.
Step 1: Train the model
For every new repository, you need to first train the model on the historical PRs.
To do that you need to add a train-ttm.yaml file to your .github/worklows/ folder in your GitHub repository. To make sure that the action runs in training mode you will need to specify the MODE as 1.
name: Run Time to Merge Model Training
# Controls when the workflow will run
on:
workflow_dispatch:
jobs:
pipeline:
# The type of runner that the job will run on
runs-on: ubuntu-latest
container:
image: quay.io/aicoe/ocp-ci-analysis
steps:
- name: Run Model Training
uses: redhat-et/time-to-merge-tool@v1
env:
AWS_ACCESS_KEY_ID: ${{ github.event.client_payload.AWS_ACCESS_KEY_ID || secrets.AWS_ACCESS_KEY_ID}}
GITHUB_REPO: ${{ github.event.client_payload.REPO || secrets.REPO }}
GITHUB_ORG: ${{ github.event.client_payload.ORG || secrets.ORG }}
S3_ENDPOINT_URL: ${{ github.event.client_payload.S3_ENDPOINT_URL || secrets.S3_ENDPOINT_URL }}
S3_BUCKET: ${{ github.event.client_payload.S3_BUCKET || secrets.S3_BUCKET }}
AWS_SECRET_ACCESS_KEY: ${{ github.event.client_payload.AWS_SECRET_ACCESS_KEY || secrets.AWS_SECRET_ACCESS_KEY }}
CEPH_BUCKET: ${{ github.event.client_payload.S3_BUCKET || secrets.S3_BUCKET }}
CEPH_BUCKET_PREFIX: ${{ github.event.client_payload.PREFIX|| secrets.CEPH_BUCKET_PREFIX }}
CEPH_KEY_ID: ${{ github.event.client_payload.AWS_ACCESS_KEY_ID || secrets.AWS_ACCESS_KEY_ID }}
CEPH_SECRET_KEY: ${{ github.event.client_payload.AWS_SECRET_ACCESS_KEY || secrets.AWS_SECRET_ACCESS_KEY }}
GITHUB_ACCESS_TOKEN: ${{ secrets.ACCESS_TOKEN || secrets.GITHUB_TOKEN }}
# Setting mode by default as 0, this will only run inference mode and if defined as 1 will train and run inference.
MODE: 1
REMOTE: 1
ACTION: 1
This mode will initiate the model training process by following the steps of data collection, feature engineering, model training on the PR data available and finally running the inference, i.e. predicting the time to merge for the latest PR on the repository.
Step 2: Inference mode
Now that you have trained a model, to set this tool up to comment the predicted time to merge on each incoming PR, you need to add another file called predict-ttm.yaml file to the .github/worklows/ folder. You can follow the same format for this workflow file as the train-ttm.yaml file, except the MODE here will be 0 which enables triggering this workflow on each new incoming PR, and adds a comment to the PR specifying the approximate time it will take to be merged.
Once set up correctly, the GitHub action bot comments a time to merge estimates on new PRs on the repository.

To see an example of how this action is being used in a repository, check this out.
In closing
In addition to the time to merge model, the AI4CI project also consists of other ML services, such as an optimal stopping point classifier and a build log classifier. These models can help teams identify the best point at which to stop testing and deploy their code, and can also identify common issues that may cause builds to fail.
To make it easy for teams to use these models, we provide a variety of tools and resources, including notebooks, scripts, dashboards and pipelines. We also make all of our notebooks, templates, tools and scripts available as templates. This allows teams to easily integrate the models into their own CI/CD processes and customize them to meet their specific needs.
Overall, the AI4CI project is working to improve the efficiency and effectiveness of CI/CD and testing processes by collecting and analyzing open operations data and developing machine learning services that can help optimize workflows.
If you are interested in looking at more detailed documentation or contributing to the project, please check out our GitHub repository.