
The battle between userspace networking and kernel networking has been ongoing since the dawn of high performance Data Plane Frameworks in 2010. With the transition of networking applications to the cloud-native paradigm, developers have had to weigh the benefits of flexibility vs. performance for their applications, and sacrifice one of these attributes for the other at a significant cost. Due to the latest innovations with eBPF, AF_XDP and Cloud Native Data Plane (CNDP), there is a unique opportunity to develop a hybrid networking stack that leverages the best of both worlds (kernel smarts and userspace performance). As such, developers no longer need to pick one attribute over the other. This article demonstrates how to build a hybrid networking stack application that accomplishes Data Plane Development Kit (DPDK)-like speeds with kernel smarts.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
Why would anyone want a Cloud Native Packet Processing Framework?
High performance packet processing applications are notoriously difficult to manage in a cloud environment. They are typically leveraging non cloud-native frameworks (DPDK/VPP) that have strict resource demands and require complex mechanisms to synchronize with the kernel or need to re-invent kernel network stack functionalities in user space. The application developers have leveraged many techniques to “modernize” or otherwise work around the provisioning and management issues of these applications in cloud environments (e.g. SR-IOV operator, vDPA Kernel Framework, CPU manager…), but are still far from having a truly cloud-native packet processing framework. Some of the benefits we could gain from a cloud-native solution are:
- Lowering provisioning and management costs.
- Unlocking the scale, upgradability and faster time-to-market benefits of the cloud.
- Enabling one application API to rule them all: The framework creates a one stop shop/application API for sending/receiving packets that supports multiple backends under the hood. Enabling applications to use separate backends in different cloud environments transparently (without changes to the application logic).
What is Cloud Native Data Plane (CNDP)?
CNDP is a new cloud-native open source packet processing framework that aims to offer:
- A collection of userspace libraries for accelerating packet processing for cloud applications.
- A lightweight (hybrid) networking stack that interworks with the Linux kernel networking stack.
- The components necessary to provision and manage a CNDP deployment in a Kubernetes environment.
CNDP works with the Kernel to provide the relevant libraries/components listed. It’s mainly C based, but provides language bindings for both Rust and Go. A high level view of CNDP is shown below:
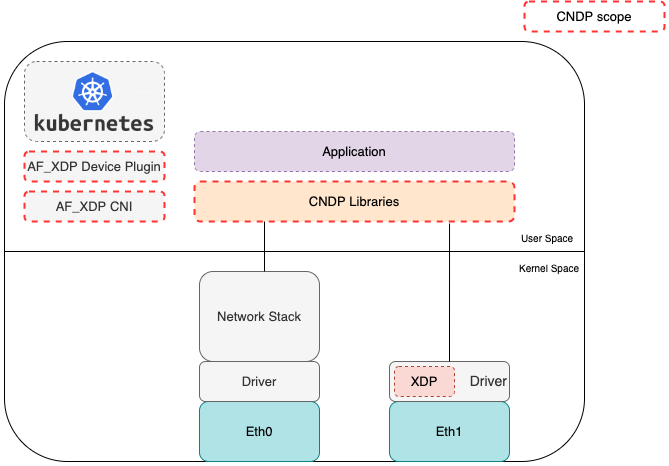
CNDP abstracts the I/O interface details from the application, so the application doesn’t need to directly interact with a specific interface. This essentially decouples the application from the underlying interface details and allows the application to leverage different interfaces depending on what’s available in a cloud environment. Today CNDP supports: TUN, TAP, AF_XDP, ring and memif. vDPA, io-uring or other interfaces could be added to CNDP as additional interface types. Runtime detection, possibly using an init container, could be used to configure CNDP to use the right backend inside a pod. One potential application of CNDP could be to use it as a common packet I/O interface for applications, allowing an application to be ported from one environment to another with no change to the application.
A snapshot of some of the “drivers” supported by CNDP is shown below:
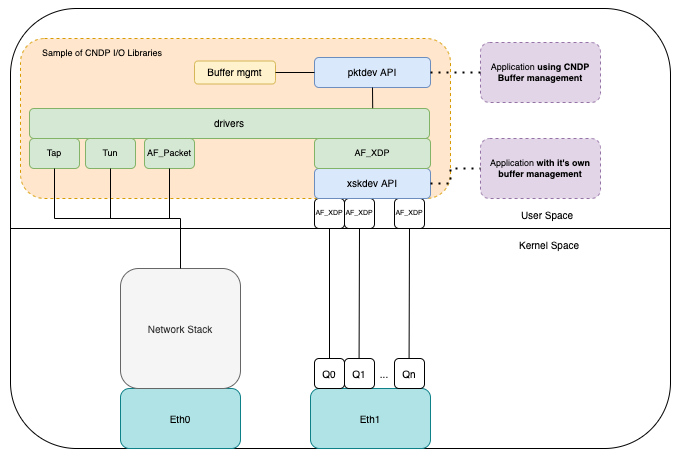
Note: Drivers in figure 2 is a misnomer – this can simply be thought of as an adaptor API. There are no drivers in CNDP.
What is a hybrid networking stack?
A hybrid Networking stack is one that somewhat leverages the concept of Control and User Plane Separation (CUPS). Where the kernel can be thought of as the control plane and user space implements a lightweight data plane that can be thought of as the user plane. Typically, traffic is immediately directed to the right place (kernel/user space) from the receive interface based on the traffic type.
CNDP currently provides a lightweight networking stack called CNET. CNET reads ARP/routing information from the kernel. The stack is based on Marvells RFC to DPDK to leverage graph traversal for packet processing. From the RFC:
“Graph architecture for packet processing enables abstracting the data processing functions as ‘nodes’ and links them together to create a complex ‘graph’ to create reusable/modular data processing functions”.
This means the developer can either:
- Build their application using the graph by implementing the “nodes” that are relevant to their application, or,
- Attach applications to a predefined lightweight stack (IPv4, UDP, TCP…) in CNDP via channels (which are conceptually very similar to sockets).
Currently, the graph nodes supplied by CNDP include: IPv4, UDP, TCP, Quic, punt (to the kernel) and drop nodes. CNDP uses a netlink agent to monitor the kernel routing and ARP tables as well as neighbor information (for networking devices it’s managing). Existing routing projects that leverage netlink (e.g. FRR) can be combined with CNDP to build a hybrid data plane that uses the kernel to process and build routing information while application traffic can traverse a fastpath (using AF_XDP) directly to the target application. As such, the application isn’t bogged down with non-application traffic.
A key difference with AF_XDP vs previous implementations of user space networking stacks is that control plane traffic can be passed to the kernel directly from the NIC/interface (doesn’t go to user space first), and the data plane traffic is redirected to user space without traversing the Kernel networking stack. The following diagrams show the difference between the traditional flow of packets from a networking interface to the application vs the hybrid data plane path.
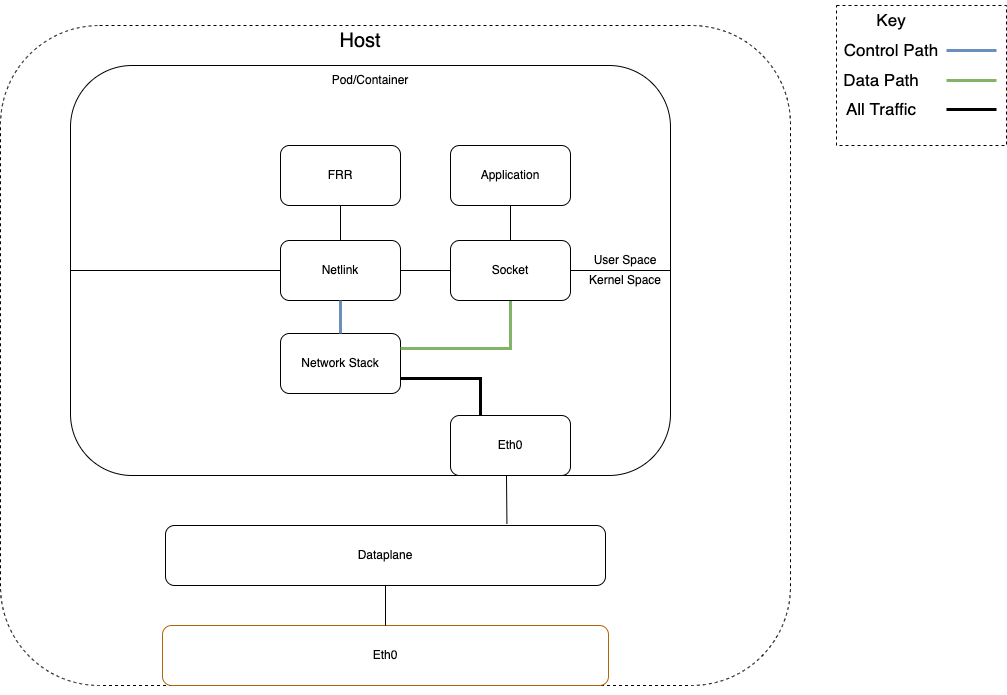
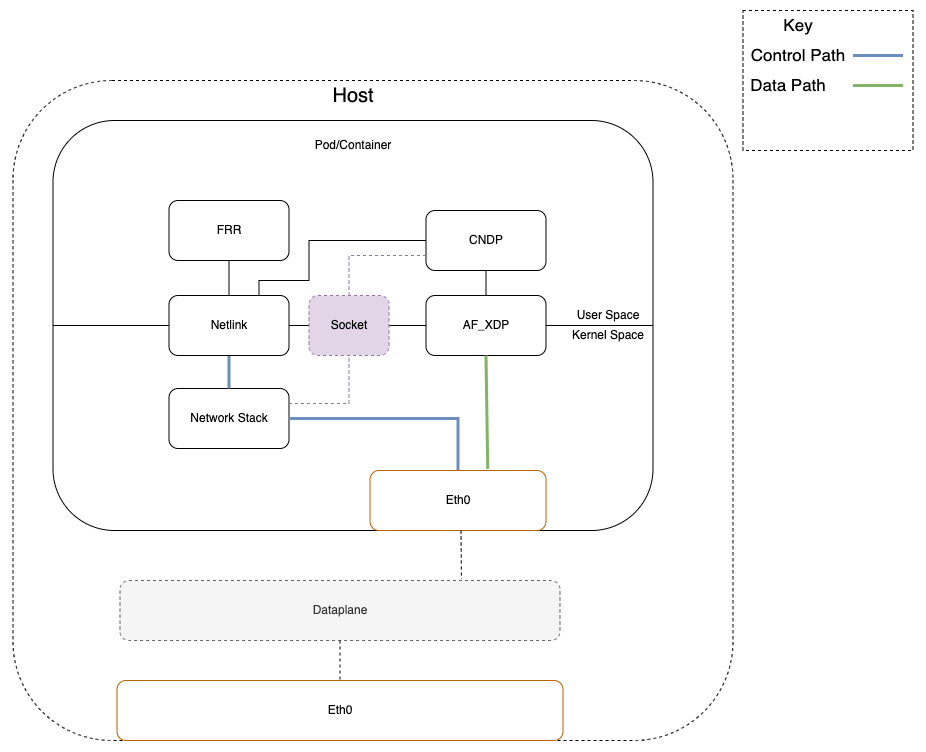
Note: the data plane in Figure 4 is optional.
Can we build a CNDP-FRR vRouter?
The short answer is yes. The diagram below provides an overview of the CNDP-FRR vRouter example, an example of a hybrid data plane. Two clients residing in two different networks are interconnected via vRouters. The vRouters use OSPF (via FRR) to learn routes to the other networks. The CNDP network stack interworks with FRR (and the kernel) to learn the OSPF routes and then traffic is forwarded via AF_XDP interfaces from one router to another.

Note: The shared example isn’t configured for optimal performance.
AF_XDP performance observations
A number of benchmarks were carried out as part of the investigation into the hybrid networking stack. The observations below were captured as part of that effort.
The performance of XDP or AF_XDP is currently very dependent on the deployment scenario. On the receive side:
- North/south traffic arriving on a NIC can be consumed with AF_XDP in native mode using zero copy buffers, yielding comparable performance to DPDK.
- East/west traffic originating from a container vEth pair incurs significant cost when consumed with AF_XDP in native mode due to SKB to xdp_buff conversion and causing immediate segmentation. This yields a drop in performance.
On the transmit side:
- North/south traffic can be sent to a NIC using AF_XDP with zero copy buffers, yielding comparable performance to DPDK.
- East/west traffic destined for a container vEth again incurs significant conversion cost.
Currently, XDP and hybrid networking is best suited to vRouter style use cases where traffic both originates from and is destined for NICs. Traffic that either originates from or is destined for a container vEth will incur copy and conversion costs and is limited to MTU-sized segments at the vEth interfaces. East/west traffic that both originates and is destined for a container vEth on the same node will incur conversion costs at both ends and is limited to MTU-sized segments.
It’s important to note that with east/west traffic (which originates and is destined for a container vEth on the same node) will achieve considerably higher throughput if it is left in SKB mode end-to-end. There are several reasons for this:
- The SKB transit through the kernel network stack is essentially zero-copy
- A single SKB can carry a TSO/GRO sized (64k) buffer that never gets segmented
- No checksum calculations or other tx/rx costs are incurred
Even outbound traffic originating from a container vEth is best left in SKB mode because it will either get segmented at the egress NIC driver or segmentation will get offloaded to the NIC.
Therefore, AF_XDP can be used in generic mode for east/west traffic, giving much better performance than AF_XDP in native mode or the native Linux stack for this type of workload.
There is considerable work needed before XDP and AF_XDP in native mode can deliver comparable performance to same-node SKB traffic or SKB egress traffic.
It’s important to note that CNDP can cater for east/est SKB traffic and yields a significant performance boost when combined with XDP (redirect) in generic mode.
Conclusions
AF_XDP is a promising technology that overcomes a lot of challenges of previous generations of I/O interfaces. The AF_XDP API (through CNDP) makes it easy to work with both software- and hardware-based interfaces. This uniquely positions it as a ‘transferable/adaptable’ interface. There are, however, a number of challenges that need to be addressed for AF_XDP, including:
- Its capability to leverage existing NIC offloads (two proposals exist to date: xdp-hints and xdp hints via kfuncs).
- The east / west traffic (native) performance through vEth.
- On the infrastructure side, leveraging a generic framework to manage the loading of its eBPF program on an interface. This framework would ideally manage all eBPF programs on the system and interact with existing loaders to enable the application of policy and priority to loading the programs.
Resolving these issues would firmly position AF_XDP as the next gen interface for user space applications, and wrapping them in CNDP will provide a better user experience to the application developers.
CNDP is a flexible packet processing framework that can be used to build a truly hybrid networking stack that can leverage kernel smarts and still accomplish DPDK-like speeds for north/south traffic. Also, it can greatly accelerate east/west traffic on a node when combined with XDP redirect to process SKBs.