
In recent years, “edge devices” have evolved from simple IoT sensors to autonomous drones driven by powerful artificial intelligence (AI) software. Similarly, the processes to develop and deploy AI software to “the edge” have also seen a rapid evolution. Today, data scientists specialize in the AI/ML models at the heart of the applications, while software supply chains are responsible for packing and shipping updates and data across the hybrid cloud, to the edge and back.
In this article, we present an end-to-end solution, “from commit to production”, for the development and deployment of AI/ML applications to modern edge devices. Our solution integrates new open source software (OSS) projects with existing Red Hat open hybrid cloud tooling and platforms.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
The goal of this integration project is the following: First, increase the velocity of data scientists that develop AI/ML models; Second, increase the security of software supply chain through automated device attestation and payload signature checks; Third, demonstrate the seamless integration of edge devices into Red Hat’s hybrid cloud platforms.

For our integration demo, we use DonkeyCar, an OSS toolkit for autonomous self-driving toy cars, as our example AI application. The DonkeyCar software suite provides tools to build and train autonomous driving models. In this demo, we run the DonkeyCar application on a Raspberry Pi 4 with Fedora 35. The source repo for our car application and CI/CD scripts is available here.
Background
A new definition of “the edge” has emerged for 2022: the AI device edge. For example, consider the drone-based food delivery services that will become widely available over the next few years. In this model, autonomous drones will navigate the skies of major metropolitan areas to deliver time-sensitive packages, e.g., a burger and fries, to arbitrary addresses. Under the hood, advanced AI/ML inference software is deployed on top of powerful, GPU-equipped edge devices.
To compensate for this new reality, the Red Hat Emerging Technology team has developed tools that help customers quickly develop AI/ML software and deploy it safely, via OpenShift control plane, to edge devices. In the remainder of this post, we walk you through a solution in three parts.
Part 1: Cloud-native AI/ML development
Data scientists and machine learning engineers are ranked among the most in-demand fields in technology today. These roles focus on the creation of trained AI/ML models, typically in an interactive notebook, such as JupyterHub, with support for languages like Julia, Python and R. Through managed cloud services, these notebook environments can be run on the cloud and accessed through a browser, drastically simplifying the overhead for developers.
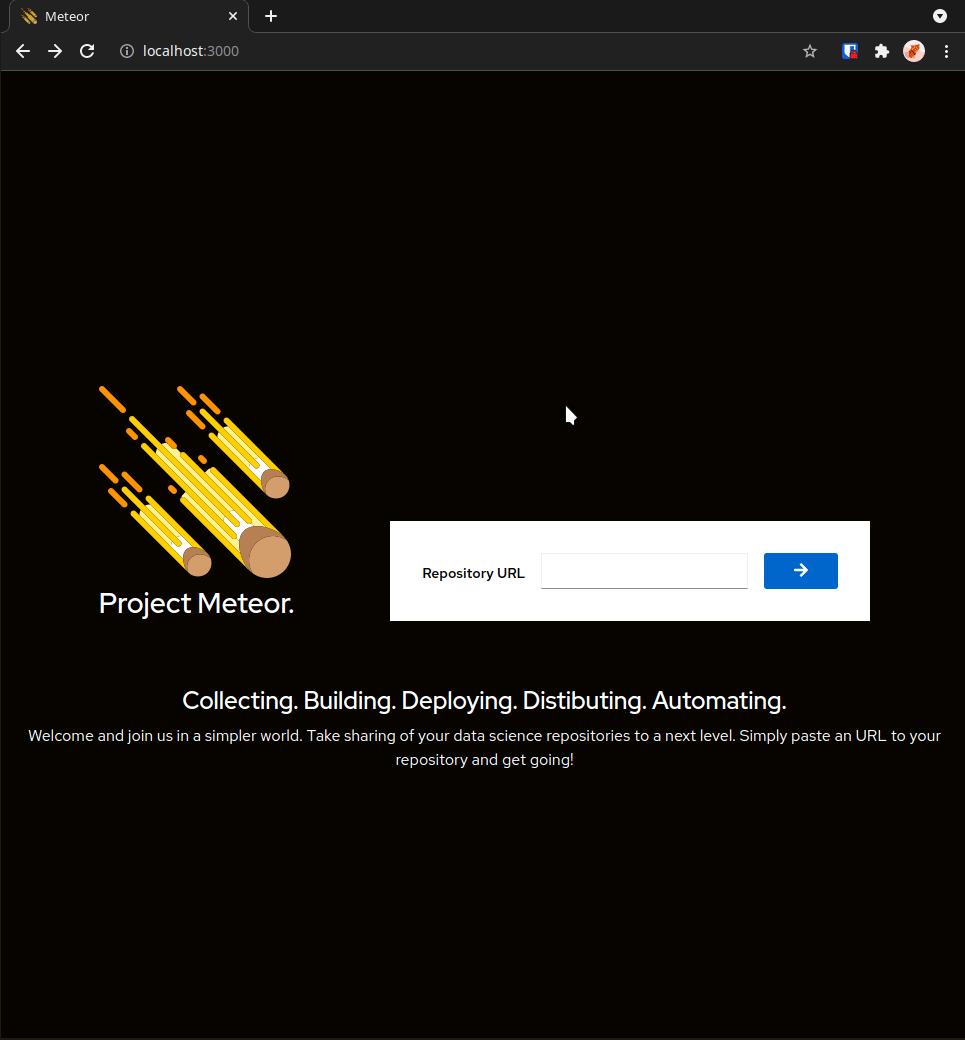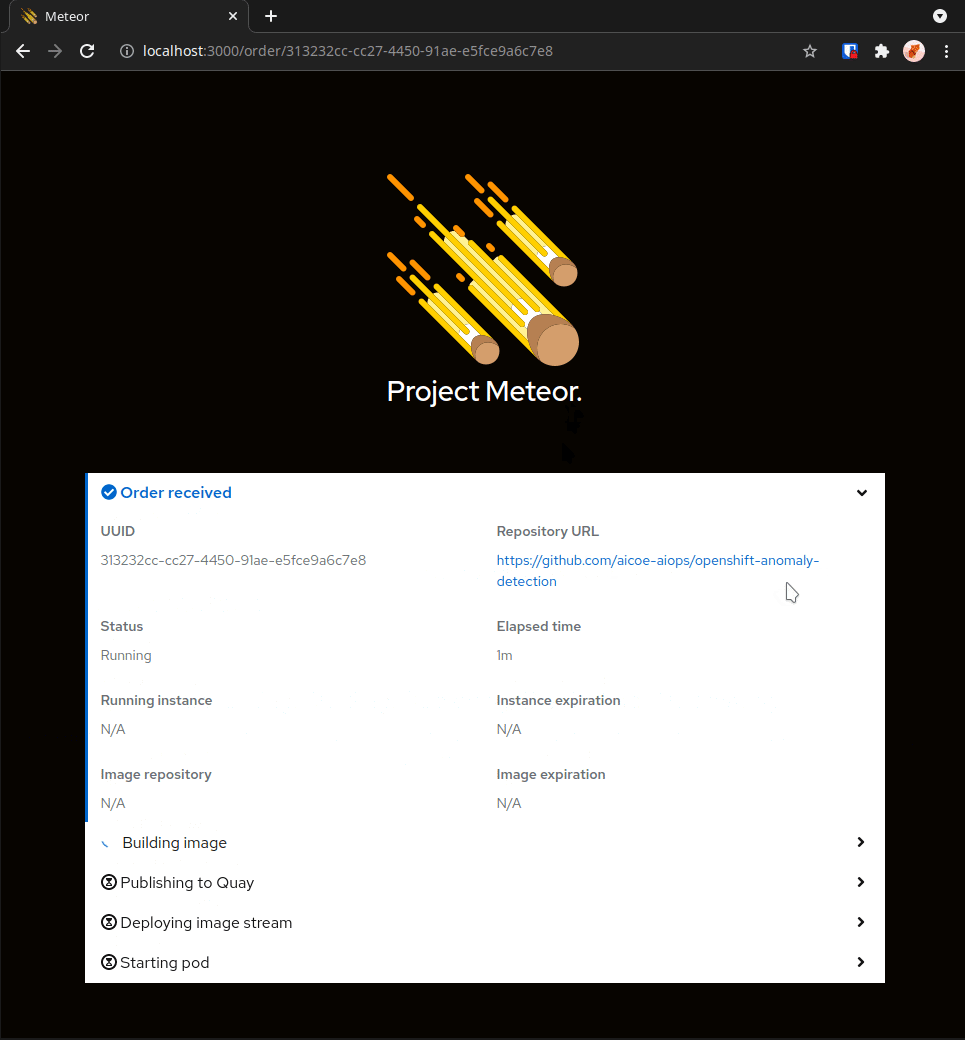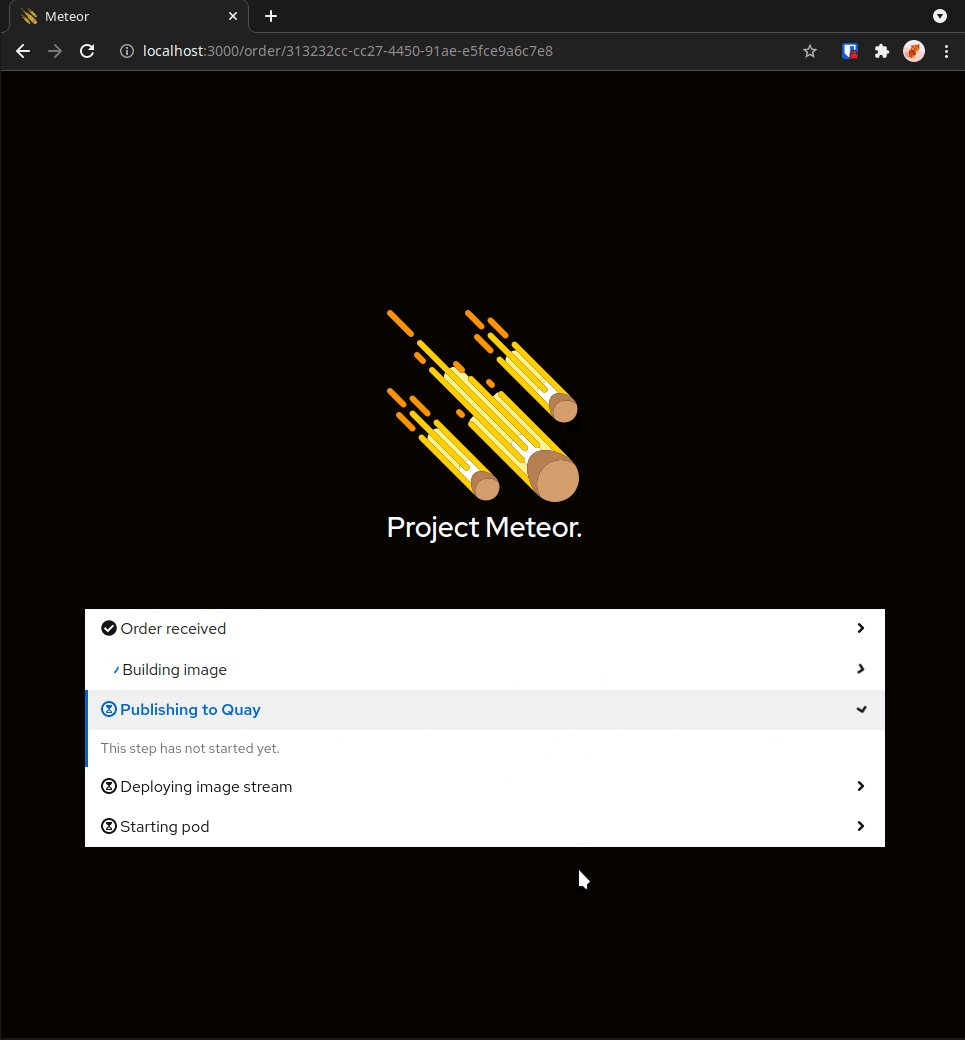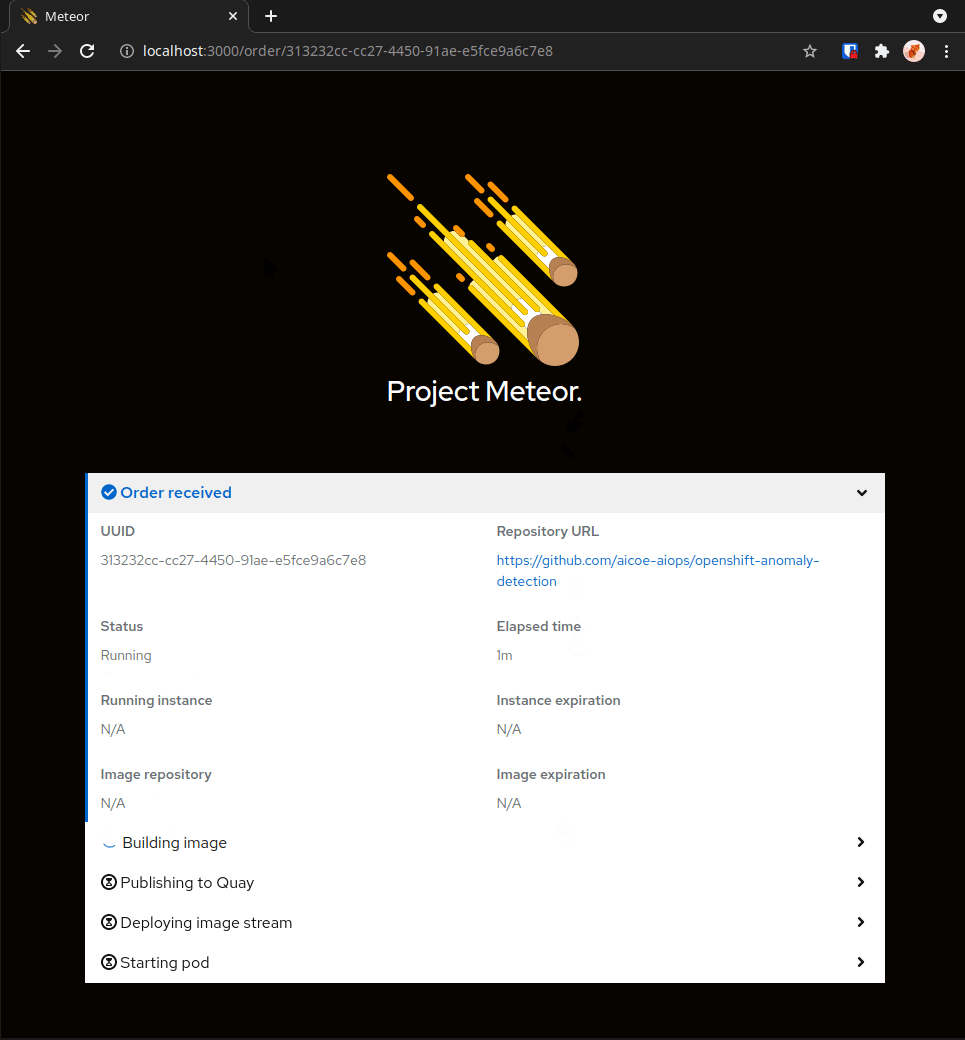
Project Meteor, from Red Hat Emerging Technologies, provides a “bring your own notebook” (BYON) service to the Red Hat hybrid cloud. With a click of a button and a URL to our DonkeyCar notebook image, a data scientist can spin up a complete Jupyter notebook environment fully configured with our DonkeyCar application and dependencies. Here the data scientist can interact with the DonkeyCar tooling to generate data, run experiments, graph results and train new AI/ML models. The results and changes are committed back to the underlying source repo from which the notebook was created.
In addition, the DonkeyCar application suite provides a “digital twin” environment where models are tested in a virtual simulation. In our demonstration, the data scientist uses the DonkeyCar application and model to connect to a simulated track environment, running as a service on AWS. The data scientist can launch a virtual car to test the performance of their model and to generate new data points.
Part 2: Supply chain security
Software supply chain security is especially critical for AI device edge use cases where proprietary software must interpret inputs to derive real-world actions and consequences. Furthermore, the data scientists that build the AI models are unlikely to be experts in cloud security. The cloud platform can cater to the specialized role of the data scientist by offloading the software build and deployment procedures into the automated CI/CD pipelines. Through this automation, security measures are integrated at different stages across the application’s development deployment.
In our demonstration, the procedures to build and deploy the DonkeyCar application are expressed as Tekton pipelines, which are automatically triggered (via Github webhooks) when the data scientist commits a new model version. Two build pipelines are deployed in parallel, one for x86_64 and one for ARM64, which result in container images that bundle the software necessary to drive the car.
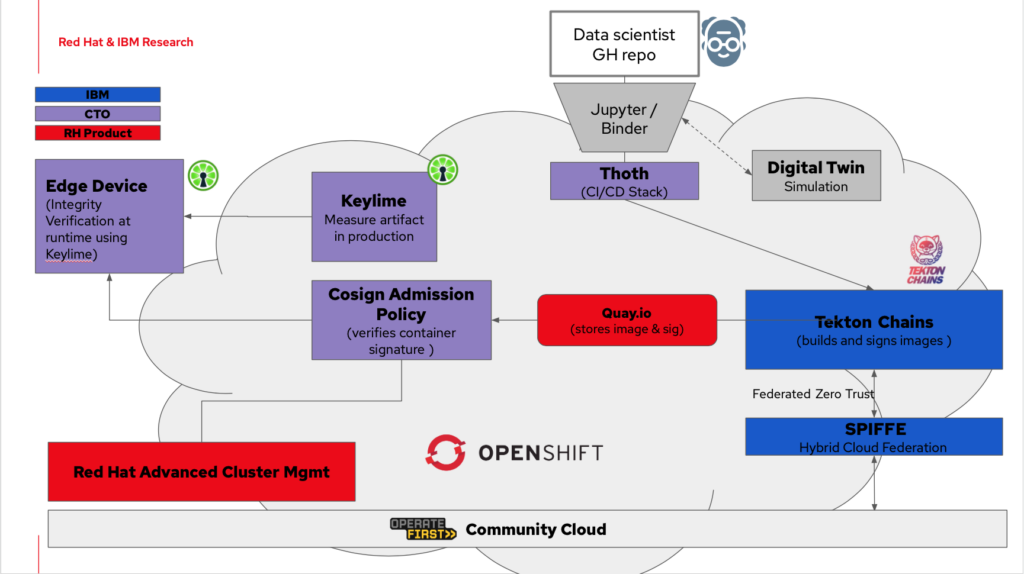
Within the build pipeline, cosign (part of the SigStore project) is used to capture a cryptographic signature of a container image as it is created. The image and signature are published together in a Quay.io repository. Later, the signature will be pulled to the device along with the container image so that the image can be validated by a Kubernetes Admission Controller before it is deployed. When done correctly, the use of signatures verifies that the container image built at the start of the pipeline is the same one being deployed.
To trust the verification of container images we have to first trust the verifier, which in turn means we have to trust the entire software and hardware stack of the device. For this, we can use Keylime, a security service that originates from Red Hat Emerging Technology, to provide boot time attestation and runtime integrity of our device. Using a Trusted Platform Module (TPM) root of trust, Keylime monitors the integrity of the system during runtime, as well as checking for any discrepancies such as modified files or installed packages using the Linux Integrity Measurement Architecture (IMA).
Part 3: Edge deployment
To review, three distinct components run on the physical edge device: Keylime, the admission controller that validates the images and the DonkeyCar application itself. For this to be feasible, each of these components needs to be deployed and managed remotely. What we need is to extend the hybrid cloud control plane to the device itself.
A significant advancement in edge operations is MicroShift, an experimental single-node OpenShift instance engineered for embedded deployments. By connecting to an existing Red Hat Advanced Cluster Management (RHACM) instance, MicroShift provides more seamless integration of the edge device with a larger hybrid cloud installment, allowing Kubernetes pods and services to be deployed to the edge using the standard OpenShift tooling. We use MicroShift in our demonstration to deploy the admission controller and the application services. To assure a trusted deployment, Keylime must be installed and configured on the device before any MicroShift services.
In our demonstration, the DonkeyCar container deployment on the edge device is the final step of the Tekton pipeline that was triggered by the data scientist’s commit-push. In this final step, deployment manifests, which specify where the application is to be run, are updated with the new container image ID and Quay.io URL. The updated manifests are pushed to a Github repository that is being monitored, via git actions, by an ACM deployment. Once the updated manifest is read, the deployment operations are pushed to all the subscribed edge devices. At this point, the container image and signature will be pulled from Quay.io, the signature will be validated by the admission controller and the DonkeyCar application container will be launched with the included mode, beginning the operation of the car.
Conclusion
In this article, we have discussed an end-to-end, “from commit to production”, demonstration of an AI/ML application deployed on a modern edge device. The data scientist uses familiar tools, like Jupyter and Bash, to interact with their AI/ML development software. Using Github actions and Tekton pipelines, the build and deployment procedures of the application are fully automated. Finally, container signatures are verified at the time of deployment to ensure the integrity of the application. The runtime integrity of the device itself is provided through Keylime.

While the DonkeyCar provides a simple toy-like example, we believe the demonstrated infrastructure can be applied to a wide range of devices and AI-driven use cases. We expect the open source technology described in this post will be directly applicable to Red Hat platforms and customers soon.