
Universal Object Reference (UOR) is a radically different approach to serverless and decentralized systems.
The term “everything is an object” may be familiar to some. It is typically used to convey a fundamental object-oriented programming concept. We can also apply that concept practically to how we look at the world. What if we thought about everything in the universe as an object?
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
We’ll keep this conversation rooted in the internet for now. This idea of everything being an object can, for example, apply to websites, videos, CI pipelines, network addresses, DNS domains and zones, Terraform configurations… The list is almost endless and, most importantly, all of those objects can be represented uniquely (as a hash [digest]).
One interesting point to note about everything being represented by a hash is that it is (almost) impossible to know the original hashed object’s value. The only information we can know about an object is the description that someone or something assigns to it. It could then be said that the description of an object conveys its attributes. When we address objects by their attributes, that is called Universal Object Reference (UOR). The UOR Framework gets its name from its ability to address any type of object that can exist within an information system.
Some of the major components of the UOR Framework are the UOR Model, the UOR Client, Universal Runtime and the concept of attribution.
UOR Model
UOR is a framework that conveys a standard way to reference and interact with objects. The UOR Model is a standard within UOR that provides us with three base attributes to associate with objects: size, mediaType and digest. Objects can be generally referred to exclusively by any of those base attributes or by using a combination of the three. If we need to describe an object using additional attributes, those can be incorporated into UOR and imported as schema extensions. Schema extensions are UOR’s extensibility framework that extends referenceable attributes. When multiple objects share the same schema, they become a dataset.
This concept of datasets is exemplified in the following diagram which depicts a query for objects with the attributes of a duck. In this example, a dataset is queried for an object that can be described as having webbed feet, feathers and a bill. A query that omits the “feathers” attribute would also return a platypus. A query that adds the “beak” attribute would return zero objects.

Coming back to the concept of the entire internet being represented as objects; Everything becomes a dataset. Each object within that dataset can be addressed by its attributes. Datasets are, of course, objects too.
Turning the entire internet into a dataset that is attribute-addressable might sound compelling in its own right, but it is the ability for objects to reference other objects by their attributes that makes UOR most profound.
One can consider the correlation between objects within a dataset as fundamental as the objects themselves. Object attribute correlations can represent hierarchical structures, like DNS domains and zones or the contents of a website. They can represent a decision tree, and they can contain images that are used as AI training data. Object attribute correlations can represent almost any data structure. The Universal Object Reference Model defines how correlations between objects can be described within a dataset.
Another important aspect of UOR is that there are at least three modes of objects. These three object modes are:
- Immutable Singular Objects: provide integrity because all references to them are by digest. The object can be hashed to confirm its integrity.
- Mutable Singular Objects: provide human-readable addressing schemes and dynamic content.
- Mutable Array Objects: provide human-readable addressing schemes and have an unknown number of any type of objects until observed.
For example, a website blog allowing comments has a blog post that is addressed by a mutable singular object, The mutable singular object has a reference to the blog data that is addressed by an immutable singular object. Each comment on a blog post is stored as a mutable singular object. Since the number of comments is unknown, the comments on each blog are referenced as a mutable array object.
The diagram below illustrates a client performing a lookup for a webpage via its location. The webpage then addresses objects that have the attributes of comments.
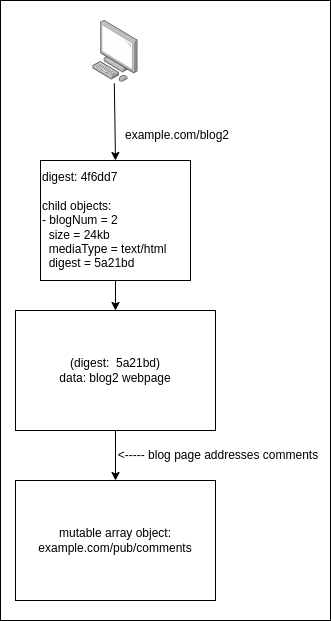
It should also be pointed out here that DNS is one way of specifying location. UOR supports alternative methods of specifying location. Although attribute addressable objects described by the UOR Model are handled by the UOR Client, it can also perform location-based lookups.
UOR Client
To allow end-users to interact with attribute-addressed objects, the UOR Framework will provide a client reference implementation. The UOR Client is capable of retrieving, publishing, querying, deleting and executing attribute addressed objects.
When the UOR Client addresses an object, it performs a series of object lookups to find objects with the attributes of the query. Each query that the UOR Client constructs can also be considered to be a dataset. An example might best convey the concept:
If a user browses to https://www.example.com/my-site/blog, the UOR Client will perform an object query to locate and retrieve the requested resource. The query would be processed in the following order:
- Locate an object that has the attributes of the A record of www.example.com and use that object data as the server location.
- Reference my-site as the namespace object.
- Reference https as the protocol indicator object.
- The context path is the object’s mutable or immutable name
If the above website lookup is published as a dataset, it can be used to link datasets together. The object lookup can also be written to a mutable array object to describe an object’s location within a decentralized system. This enables the UOR Client to retrieve an object from any location within an information system via any protocol as required. The UOR Client will have core retrieval protocols such as HTTP, s3, git, IPFS and OCI; with the ability to extend supported protocols via Universal Runtime (see subsequent section).
Universal Runtime
Universal Runtime (UR) is the concept of making datasets executable and is the serverless engine of UOR. Executable objects referred to as Universal Runtime Objects (UROs) can optionally be embedded within datasets and executed by the UOR Client. URO’s can provide dataset rendering/processing logic, storage provider protocol drivers and any utility needed to run or interact with a dataset.
A Universal Runtime Object is versioned with a dataset schema. This is to ensure that the embedded URO is compatible with the extended attributes of the dataset. URO’s are intended to be published and shared as part of dataset schemas. This allows standards to be published authoritatively per dataset type and globally referenced.
For example: When a website is rendered from a website dataset, the UOR Client retrieves the dataset’s default schema and URO from a publicly published and authoritative source. The URO is then executed and presents the website content to the browser engine. When the browser engine requests a web element, it sends its request to the URO which then retrieves the requested web element from the dataset and presents it to the browser engine.
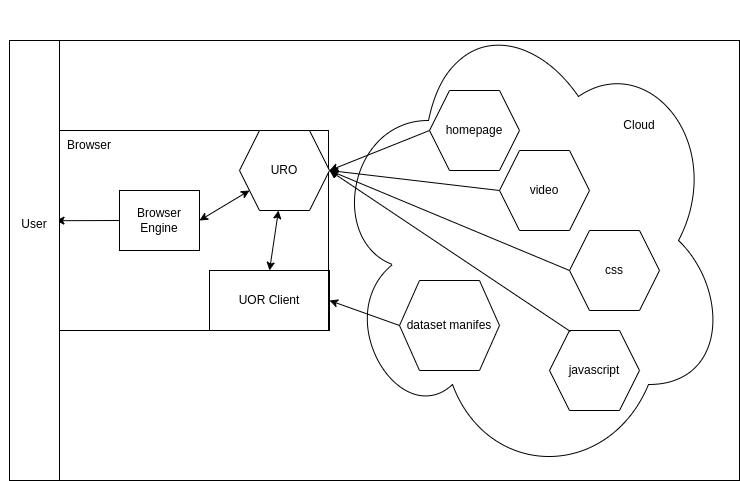
In the example above, a dataset is requested by the browser. The UOR client retrieves the dataset manifest and then retrieves the dataset URO. The URO then serves the homepage, video, CSS and JavaScript objects from the dataset to the browser engine for rendering.
Attribution
Let’s recap to see why this all matters.
- Everything is an object
- Objects have attributes
- Objects can be executable
Datasets are composed of many objects that can have many attributes as defined across multiple schemas. When we add Universal Runtime, the concept of embedded algorithms, those datasets can convey attribution. The use of the word attribution in this context conveys intent or behavior. Attributes allow us to, for example, correlate a user with their phone, laptop, emails and other data. Attribution conveys the behavior of the user and the interactions between themselves and their correlated objects.
If we take this back to the website example: The attributes of a dataset that contains a website correlate its objects with its content. Attribution in this context conveys the behavior or the intent of the webpage, we would usually refer to this as how the webpage is presented to the browser engine.
What if we throw expert system training into the mix? Attribution can be used to convey the intent of a dataset to an expert system. A dataset of objects, with attribution, becomes an end-to-end Terraform provisioning configuration. Attribution can be conveyed to an expert system by executing the URO and analyzing its output. Once the intent of a dataset is established, an expert system can then form correlations between objects, not only within a single dataset, but by referencing all objects of a certain type across multiple datasets. The expert system can analyze the attribute correlations between objects and also analyze the correlations between in-content references to adjacent objects.
The Universal Runtime section made a reference to an RPC-based standard called URi that is used to communicate between URO’s. Since everything is an object, we can address UROs running on other devices. When a client does not need to download a URO, it could interact with a URO running on another system. The running URO could then serve content to the requesting system. This could be a mechanism to serve content in a decentralized system or be used for other forms of decentralized computing.
Looking ahead
By using an object reference model to shift the way that we perceive the universe and information systems, we are able to realize some of the efficiencies that can be achieved from serverless and decentralized computing, while turning information systems into homogenous datasets prepared for expert system training. The other aspect of UOR, embedded algorithms, then provides us with a serverless mechanism for interacting with any component of an information system and conveying any concept to an observer. The opportunities that are unlocked truly become limitless.
The UOR Framework, related concepts, and use cases are currently being cultivated in the open source community. If you are interested in learning more about these concepts, please refer to the UOR Framework site which contains references to how to get involved in the discussions and participating in the community.