
Exploring a small form factor OpenShift designed for field deployed edge computing devices
Edge Computing spans a broad range of use cases and deployment models. On one end, it can refer to micro data centers located in controlled environments that are formed by a small number of servers. On the other end, edge computing includes embedded systems with low-power CPUs and few GBs of RAM deployed in the field under harsh environmental conditions, e.g. sparse and costly network connectivity and no physical access security.
Note: Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
Kubernetes distributions like OpenShift have traditionally been engineered for the cloud and data center-like environments. For example, OpenShift can deploy cloud-native applications as well as lifecycle-manage Kubernetes cluster, underlying OS and infrastructure.
Systems deployed in remote edge locations often use device management software to lifecycle-manage these systems including the OS. Companies are looking for the best of both worlds for these remote systems: using Kubernetes to manage cloud-native applications and device management to manage OS and underlying hardware.
MicroShift is a project that we are currently working on. Though not currently supported, it is being designed for field-deployed edge computing devices and to provide workload portability and a consistent management experience – very similar to the functionality we find in Red Hat OpenShift. As we work on this project, we would like to share what we are working on and gather some early feedback from those of you that are interested in collaborating with us.

(photo credit: Laserlicht under CC BY-SA 4.0)
What makes field-deployed devices different?
In comparison to a system for managing field-deployed devices, OpenShift has been optimized for the needs and conditions of the cloud. Architectural decisions like self-managing clusters orchestrating changes across Kubernetes, OS, and machines are a result of this.
Arguably, optimizing for field-deployed devices would have resulted in different trade-offs, e.g. optimizing for adverse network conditions or minimizing resource footprint. This situation motivated us to investigate an edge-centric way of applying the concepts of Kubernetes, and the result of our ideas is a project called MicroShift.
“Field-deployed” refers to mass-deployment and operations in remote, uncontrolled locations with highly challenging network connectivity. There are dozens of use cases where having a field-deployed edge computing device might bring the processing and storage capabilities we need closer to the user. Imagine one of these small devices located in a vehicle to run AI algorithms for autonomous driving, or being able to monitor oil and gas plants in remote locations to perform predictive maintenance, or running workloads in a satellite as you would do in your own laptop. Now contrast this to centralized, highly controlled data centers where power and network conditions are usually very stable thanks to high available infrastructure — this is one of the key differences that define edge environments.
Field-deployed devices are often Single Board Computers (SBCs) chosen based on performance-to-energy/cost ratio, usually with lower-end memory and CPU options. These devices are centrally imaged by the manufacturer or the end user’s central IT before getting shipped to remote sites such as roof-top cabinets housing 5G antennas, manufacturing plants, etc.
At the remote site, a technician will screw the device to the wall, plug the power and the network cables and the work is done. Provisioning of these devices is “plug & go” with no console, keyboard or qualified personnel. In addition, these systems lack out-of-band management controllers so the provisioning model totally differs from those that we use with regular full-size servers.
Indeed, in field-deployed environments, autonomous registration* and configuration models are a necessary step in the configuration process. A very common scenario might be to push a faulty version of software, or network configuration that might brick the device. Therefore, devices that are deployed in a pre-registered, pre-configured state must also be able to autonomously recover from the failed update rolling back to a previous state.
* A very good example is the FIDO Device Onboarding specification that allows an automated IoT device provisioning workflow designed with security in mind.

(photo credit: NVIDIA Corporation under CC BY-NC-ND 2.0)
What is MicroShift?
MicroShift is an explorative project created by the Edge Computing team in Red Hat’s Office of the CTO. MicroShift’s goal is to tailor OpenShift for field-deployed device use cases, providing a consistent development and management experience across all footprints.
The idea is for MicroShift to be an application that users can optionally deploy onto their field-deployed devices running an edge-optimized OS like RHEL (using its edge extension such as rpm-ostree based transactional updates and greenboot-based auto-rollbacks designed for field-deployment), and then manage those devices as MicroShift clusters through Red Hat Advanced Cluster Manager (RHACM) as they can with OpenShift. RHACM allows you to control clusters and applications from a single console, with built-in security policies. Extend the value of Red Hat OpenShift by deploying apps, managing multiple clusters, and enforcing policies across multiple clusters at scale. The upstream project for RHACM is Open Cluster Management.
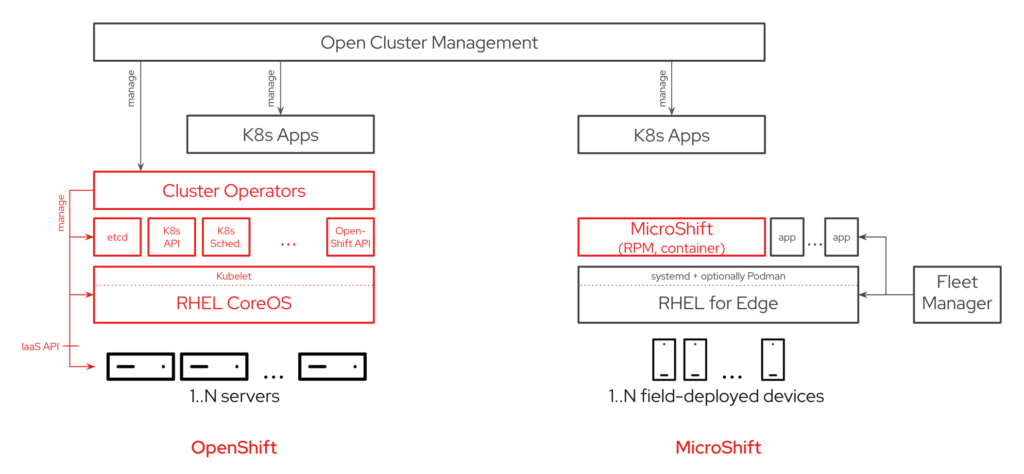
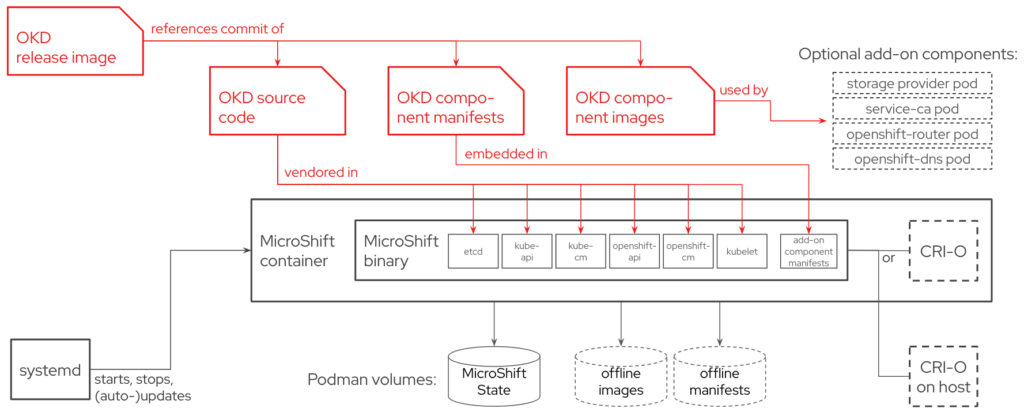
Functionally, MicroShift repackages OpenShift core components** into a single binary that weighs in at a relatively tiny 160MB executable (without any compression/optimization). As a monolith, it provides an “all-or-nothing” start/stop behavior that works well with systemd and enables fast (re)start times of a few seconds.
** etcd, kube-{apiserver,controller-manager,scheduler}, openshift-{apiserver,controller-manager}
This also vastly simplifies changes including updates and roll-backs and obviates the need for cluster operators to orchestrate across components. Dropping cluster operators significantly reduces MicroShift’s resource footprint, but comes at the cost of requiring more manual, lower level configuration from users if operating outside of MicroShift’s opinionated parameters.
On its own, the monolith core can handle a few very basic use cases. To expand upon these capabilities, MicroShift by default deploys a small subset of services*** using OpenShift’s container images.
*** currently only openshift-dns, openshift-ingress, service-ca, and local-storage-provisioner
MicroShift has been specifically designed for edge computing use cases, with a goal of fitting in the limited storage capacity of field-deployed devices that can be embedded into a variety of appliances such as cars, factory lines, airplanes or even satellites.
But as a great addition, and thanks to its small footprint, it can also be very handy for developers that want to run a minimal OpenShift flavor on their laptops. MicroShift is a very useful environment for developers to write, test, and deploy new cloud-native applications.
MicroShift has been demo’ed to run on macOS and Windows 10, on ARM64 and RISC-V CPU architectures. Curious to see it in action? Have a look at the end-to-end provisioning demo video.
While our team is still working on adding important features (e.g. multi-node) into MicroShift, we are excited to share an early version for curious developers to experiment with. Head over to this link to download MicroShift, and while you’re there, you can read up on how to share your feedback and even contribute code to the project! Does MicroShift solve a problem for your team? Join our Slack channel and let us know how it works for you!