
Organizations face a challenging task of identifying and developing data storage, backup, recovery, and migration solutions for the enterprise. There are a wide variety of tools and solutions in the ecosystem that work well with traditional legacy-type environments, but as enterprises move closer toward a cloud-native computing model, it becomes difficult to continue to use those same existing replication methods. Many of the tools that exist today are not inherently cloud-aware, making it hard to find a good solution that is cloud-native and can handle all your Kubernetes replication needs. John Strunk from Red Hat Storage set out to solve this specific problem by creating VolSync.
Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
What is VolSync?
VolSync is a storage-independent, multi-cluster, asynchronous data replication operator that is appealing for its unique, lightweight, and agnostic data movement capabilities for file or block storage types.
VolSync takes advantage of data replication technologies using rsync, Rclone, and Restic, controlled by a single CustomResource (CR) based interface. It uses CSI capabilities like volume snapshots and clones to capture a point-in-time copy of data, if supported by the driver.
To illustrate the value VolSync, we’ll explore key features and some common cloud-native use cases this technology can help solve. In future posts, we will delve into the core internal workings of VolSync with specific examples of how to configure and use this operator in the enterprise.
Red Hat’s now+Next blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
What does VolSync do?
VolSync acts as a wrapper and controller for various data movers, each with its own unique feature set. Another powerful attribute of VolSync is its ability to work with any data volume, including CSI-enabled volumes, non-CSI-enabled volumes, and even vendor-specific replication methods. This allows for easy data movement between, in, and out of disparate storage systems and volumes.
Let’s explore the current key data movers in VolSync:
| Data Mover | Features |
|---|---|
| rsync |
|
| Rclone |
|
| Restic |
|
Each of the above movers permit selection of a copy method. This is a configurable field within the VolSync CR that dictates how the data will be handled at the source and destination. There are three types of copy methods supported today:
| Copy Method | Features |
|---|---|
| Snapshot |
|
| Clone |
|
| None |
|
We’ve touched on a few key points in regards to VolSync’s flexible data movement capabilities, but one of the most important characteristics is that VolSync is storage agnostic.
Storage agnostic means that VolSync does not care about the underlying storage vendor, technology, or type being implemented. For example, a data source might be a Gluster volume and the destination could be a Ceph-based storage volume or vice versa. The data can be easily replicated between the two disparate storage systems. Furthermore, the source or destination could live outside of your Kubernetes cluster or inside, making your data accessible from anywhere you need it. Lastly, VolSync also supports all Kubernetes drivers, including internal, external, CSI-based, and non-CSI-based drivers.
What type of use cases can VolSync help solve?
Now that we have a better understanding of what VolSync is, let’s start looking at some of the use cases that VolSync can help solve.
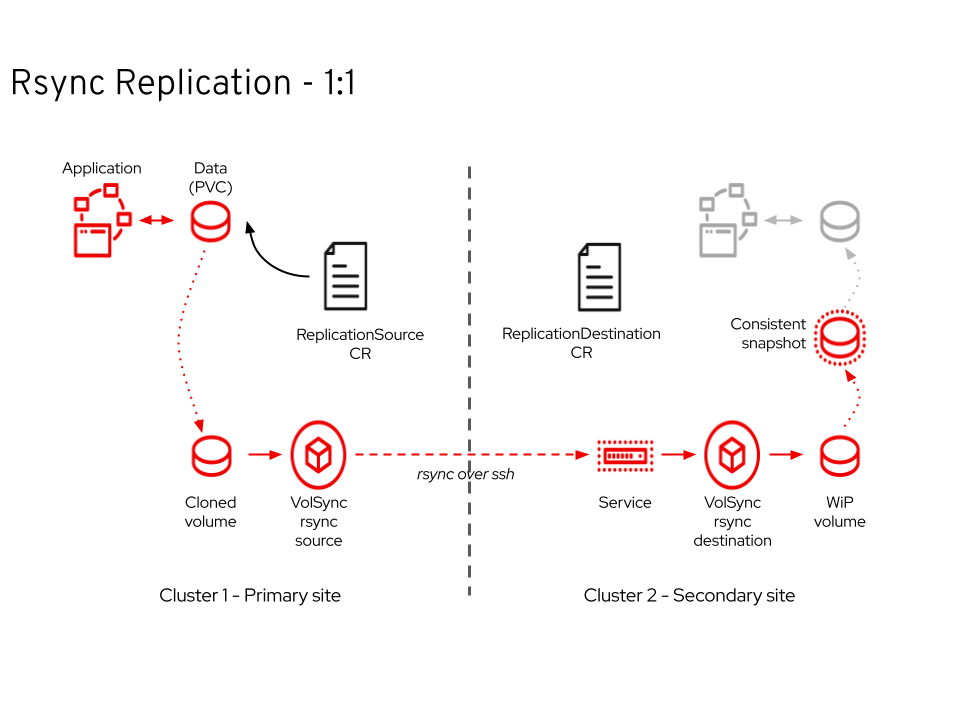
Disaster recovery (DR) and failover:
VolSync is able to do background replication, data delivery, and restoration for Persistent Systems, either with a one-to-one backup and failover, or by backing up data to an off-site repository where it can be held and restored as needed. As we’ve built on this use case and explored the possible integration points, we have seen where this functionality can be built into existing solutions and automated in a GitOps fashion or in other pipeline-type tooling.
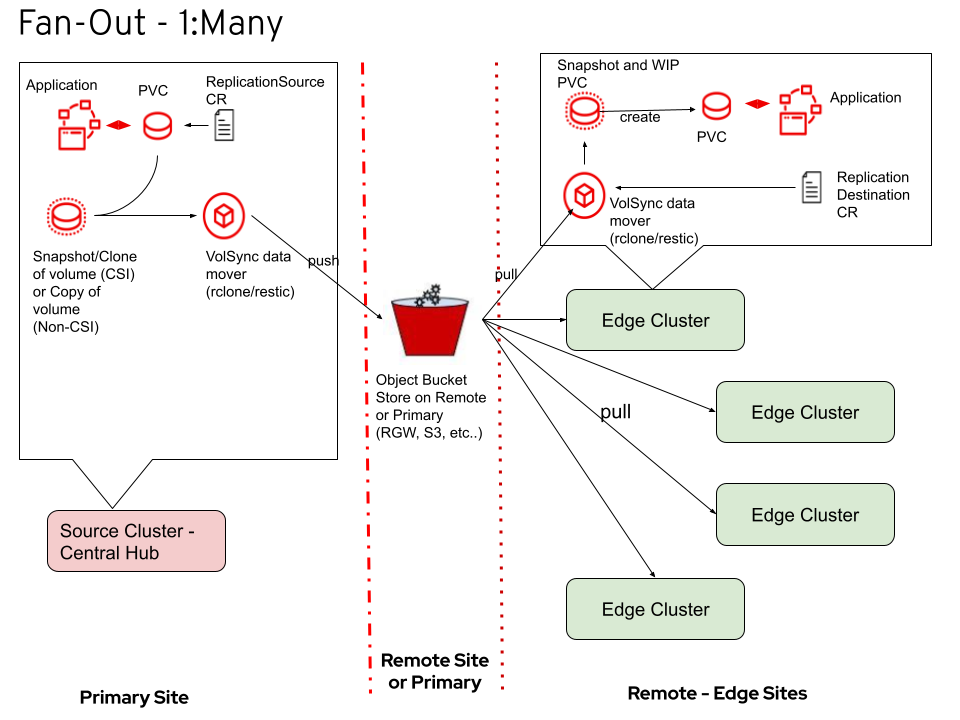
Data distribution:
We’ve discussed VolSync’s ability to perform one-to-one data distribution, but it also has the capacity to distribute data in a one-to-many fashion. This becomes interesting in an edge scenario, where data is pushed from the central storage repository to a cloud object store and then fanned out to multiple edge sites. This enables consistent data at the edge.
Application and data migration:
As touched on earlier, VolSync’s power is in its storage agnostic capabilities—it does not care where or what type of data volume we are talking about.
Imagine that you have a legacy application you want to move into a shiny new Kubernetes cluster. Because VolSync is storage agnostic, it can do cross-vendor migrations in and out of clusters, moving external data of any type into a volume in Kubernetes. It can even do public, private, and on-premise migrations, making it easy to get your data where you need it.
Off-site analytics:
If you need to scale out machine learning (ML) or analytics, VolSync can deliver the primary data to your ML/AI/Analytics platforms. With VolSync’s ability to schedule replications, the data needed for your workloads can be delivered on a consistent basis. This flexibility also gives the ability to grab multiple sources of data, and even have multiple delivery destinations for analytic processing.
Development and testing with production data:
Similar to the prior use case, VolSync can make it easy for production data to be distributed to development and testing systems across the organization. As developers build out systems, they often need to model real production data for testing; VolSync facilitates directing the test data where and when you need it.
Where do we go from here?
Now that we’ve learned a little bit more about VolSync and its use cases, what’s next for VolSync? The plan is for VolSync to continue enhancing its existing feature set and, because of its flexible architecture, also continuously look for new ways to improve data movement in a secure, efficient, lightweight, and easy-to-configure manner.
Additionally, we are investigating potential integration points into Red Hat product and solution portfolios, including ways that VolSync can complement and enhance Red Hat solutions and disaster recovery operations, cross-vendor storage migrations, and GitOps operations in products like Red Hat Advanced Cluster Manager (RHACM).
In the coming months, we plan to publish additional follow-on posts on this topic, going deeper into the underlying working mechanics with more information and examples of how to use it, and some specific examples based on our exploration of the Red Hat use cases mentioned above.
To find more information about VolSync, or if you want to start contributing to the project, please visit our VolSync repo and docs sites, or reach out to any of the authors on this post.