
Object storage systems can offer simple, scalable and cost-effective means of storing heterogeneous data sets. Traditionally, these systems have been designed for media, backup, and archive. However, the usage of object storage systems is increasingly expanding to broader workflows involving data and AI-related applications and distributed environments such as hybrid cloud or edge that challenge traditional designs.
Data and AI applications require frequent and fast access to data, which is usually immutable once created. In distributed environments, some data is produced locally, while other data is consumed from remote locations such as a public cloud or a data center. Workloads deployed in such environments are likely to experience low performance when transferring data over a remote network. Furthermore, if the same data has to be repeatedly accessed, there are recurring charges for data transfer or egress from most public clouds.
Red Hat’s Emerging Technologies blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
Collapsing storage locations
A common practice is to co-locate an object-store to serve the applications in every location, with replication to sync and protect the data between locations, or in a completely self-managed fashion where users are responsible to copy data in and out of the local storage. However, such local object-stores are quickly realized to be isolated storage silos as their management complexity starts creeping in.
Managing multiple storage locations introduces many problems for enterprises – they increase the complexity of storage management (capacity, encryption, compression, dedup, reliability, monitoring, etc…) and data management (permissions, copies, versioning, cataloging, analytics, etc…). Ultimately, in distributed environments, the locality of data is both a performance necessity and a pain to manage.
For these reasons, modern designs are meant to collapse storage locations into a “single source of truth” such as an object-store in a central location, which we will refer to as “the hub”. Users and their applications can then directly access the hub buckets over the network, however, this still doesn’t explain how to use the remote network and local storage efficiently and consistently. Without a general platform service to orchestrate the use of these resources, users are left responsible to copy data back and forth to their local storage for their applications to process.
Hence, the proposed model for kubernetes admins is to deploy a local platform service that provides an object-store gateway connected to the hub, that seamlessly handles the complexity of these optimizations, while automating the management of the local storage in every new location. This model follows a cache paradigm, in which the gateway fetches data on-demand from the hub into local storage for subsequent reads, and cleans up cold data as needed to make room for more relevant data.
A platform service also has the benefit of applying a cluster wide policy across all the local workloads, which can automatically share the local storage capacity between the running workloads on demand, instead of having each workload allocate its own static local storage. With this model in mind, let’s explore how this can be implemented.
Bucket caching in NooBaa
NooBaa is an open source project providing a flexible object gateway that implements various models for hybrid and multi cloud environments. To meet the challenges described above, NooBaa is introducing a bucket caching feature. To explain how this works we need some overview on NooBaa.
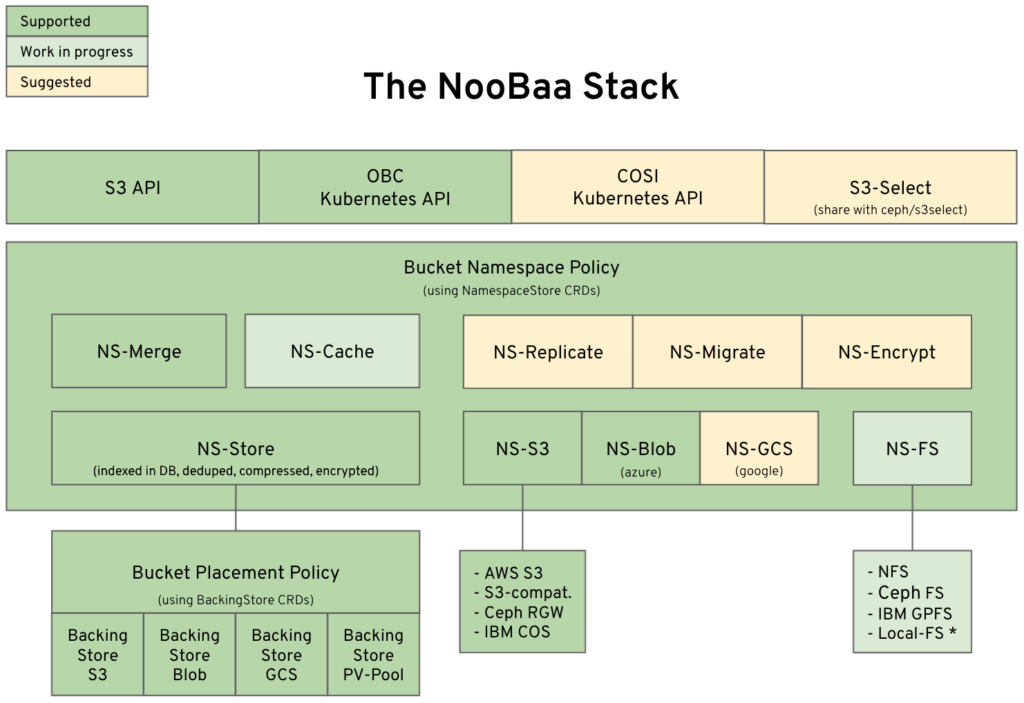
In general, NooBaa provides an S3 gateway service, which can be configured using the NooBaa operator’s Kubernetes CRD’s (CustomResourceDefinitions) to provide buckets with various hybrid policies that utilize object-stores, filesystems, and block storage. To define these policies, NooBaa uses an abstract concept called “Namespace Resource” (not to be confused with Kubernetes namespaces) which is a class of underlying resources which are used to compose a gateway bucket policy. The primary namespace resource types in NooBaa are:
- “NS-S3” which resolves its objects to some backend S3 compatible bucket.
- “NS-Blob” which translates S3 to Azure Blob.
- “NS-FS” presents a filesystem as S3 bucket.
- “NS-Store” is a namespace that supports chunking, dedup, compression, encryption, managing meta-data, and storing data chunks on any storage (cloud/fs/block).
- “NS-Merge” combines multiple namespaces into a single bucket by merging their name/key spaces. Namespace types are being added to the project to introduce new capabilities for hybrid environments.
New types of namespaces are being added to the project to support new data management functionality that keeps the complexity of the underlying resource from applications. See the NooBaa stack diagram for more directions for Namespace Bucket functionality.
“NS-Cache” is a new namespace that implements caching policy. It can use any other namespace as the Hub-namespace (its source of truth) and uses any type of local storage for caching using NS-Store (which provides the chunking, mapping and least recently used (LRU) eviction mode for the cache policy). By building the cache capability on top of the NooBaa namespace abstraction, we make it as flexible as possible so that any supported storage can be adopted for the hub and the local cache.
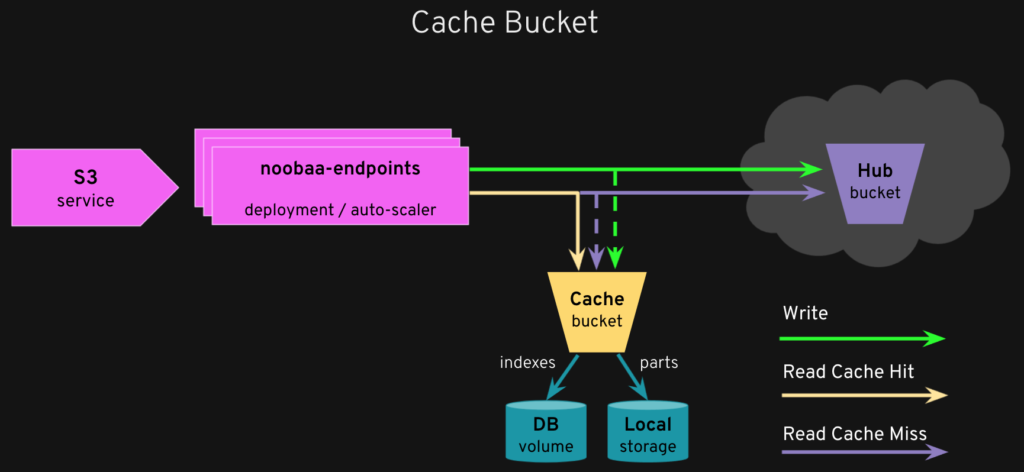
How bucket caching works
Applications interact with a cache bucket using the NooBaa S3 endpoints, which are stateless, lightweight and scalable pods. For the Kubernetes-curious, these pods are controlled by Kubernetes Deployment, Service, and Horizontal Pod Autoscaler objects, and also a Route object on OpenShift. As objects are written or read via the endpoint to a cache bucket, the NS-Cache policy is taking over and using the hub to write or read unavailable or already expired data in the local cache storage, and automatically updates the local cache with objects (or parts of objects).
The initial implementation is a “write-through” cache model, which is efficiently optimizing read workflows. In “write-through” mode, new objects created on the cache bucket are written directly to the hub, while also storing a local copy of the object. Read requests are first attempted to be fulfilled from a local storage, and if the object is not found there, it is fetched from the hub and stored locally for some time to live (TTL) . Note that only the relevant parts of objects (ranges) that are being used are kept locally, based on the available capacity and LRU.
The cache model ensures that workflows that require frequent access to the same object or parts of the object do not have to repeatedly get the object from the hub. Also, by only storing the relevant parts of the objects locally, the efficiency of the cache is optimized for maximizing hit ratio even with a relatively small capacity in the local storage.
Roadmap and summary
Going forward, there are a couple of exciting future enhancements to the bucket caching feature. Most notable is the option to implement a “write-back” cache model which will allow disconnected environments and speed up writes with local storage.
Another area is allowing fine cache-control hints to allow users/admins that have more knowledge to provide their hints for certain datasets to be prefetched or pinned to the cache (i.e not be subject to eviction).
In summary, bucket caching can help provide the efficiency needed for Data and AI applications while still utilizing the infinite capacity and reliability available from a cloud object-store, and collapsing of storage locations.
NooBaa bucket caching is included in the latest NooBaa v5.8 release. For more details, visit the NooBaa project and post issues in case you have any questions.