
At the time when Ceph was originally designed, the storage landscape was quite different from what we see now. Initially, Ceph was deployed generally on conventional spinning disks capable of a few hundred IOPS of random IO. Since then, storage technology has progressed rapidly through solid-state drives (SSDs) capable of tens of thousands of IOPS to modern NVMe devices capable of hundreds of thousands of IOPS to more than a million. In order to enable Ceph to better exploit these new technologies, the ceph community has begun work on a new implementation of the core ceph-osd component: crimson. The goal of this new implementation is to create a replacement for ceph-osd that minimizes latency and CPU overhead by using high performance asynchronous IO and a new threading architecture designed to minimize context switches and inter-thread communication when handling an operation.
Crimson’s focus is on minimizing CPU overhead and latency—while storage throughput has scaled rapidly, single threaded CPU throughput hasn’t really kept up. With a CPU at around 3 GHz, you’ve got about 20M cycles/IO for a conventional HDD, 300K cycles/IO for an older SSD, but only about 6k cycles/IO for a modern NVMe device. Crimson enables us to rethink elements of Ceph’s core implementation to properly exploit these high performance devices.
Red Hat’s now+Next blog includes posts that discuss technologies that are under active development in upstream open source communities and at Red Hat. We believe in sharing early and often the things we’re working on, but we want to note that unless otherwise stated the technologies and how-tos shared here aren’t part of supported products, nor promised to be in the future.
Ceph architecture today
 At a high level, Ceph supports multiple access modes within a single cluster: object via RGW, block via RBD, and file via CephFS. Underlying all three, however, is a common storage cluster called RADOS.
At a high level, Ceph supports multiple access modes within a single cluster: object via RGW, block via RBD, and file via CephFS. Underlying all three, however, is a common storage cluster called RADOS.
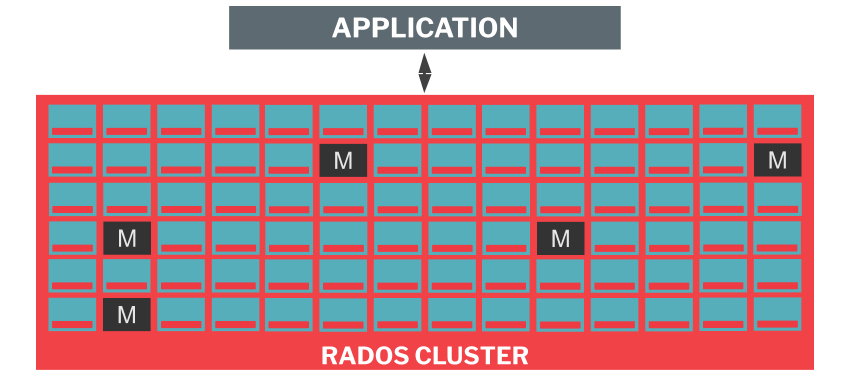
Within the RADOS cluster, there are two kinds of node: OSDs and Monitors. Monitors are denoted in the figure as M. There are typically 5 to 7 of them in a cluster, they are responsible for arbitrating things like cluster membership, but they are not directly involved in handling IO requests. The remaining entities are OSDs, typically one per disk. These ceph-osd processes are responsible for translating read and write requests from clients into the disk and network operations required to perform reads and to replicate and persist writes. Internally, each ceph-osd process is structured as a sequence of thread pools representing different stages in the op-handling pipeline:
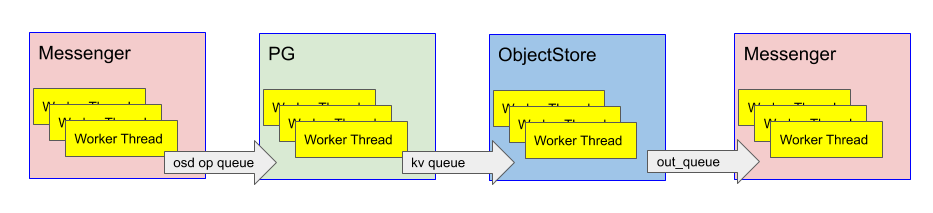 Broadly speaking, there are three main components of the ceph-osd IO pipeline
Broadly speaking, there are three main components of the ceph-osd IO pipeline
- Messenger: responsible for reading and writing data to the network
- PG: logic and state responsible for operation ordering, replication, recovery, etc
- ObjectStore: responsible for serving reads and implementing atomic, transactional writes on top of local durable storage
Consider a small unreplicated write. The client message is read from the wire by a messenger thread, which places the message in the op queue. An ‘osd op’ thread-pool thread then picks up the message and creates a transaction, which it queues for BlueStore (the current default ObjectStore implementation).
BlueStore’s ‘kv sync’ thread then picks up the transaction along with anything else in the queue, synchronously waits for ‘rocksdb’ to commit the transaction, and then places the completion callback in the finisher queue. The finisher thread picks up the completion callback and queues the reply for a messenger thread to send.
Each thread hand off requires inter-thread coordination over the contents of a queue. Moreover, with ‘pg state’ in particular, more than one thread may need to access the internal metadata of any particular PG leading to lock contention.
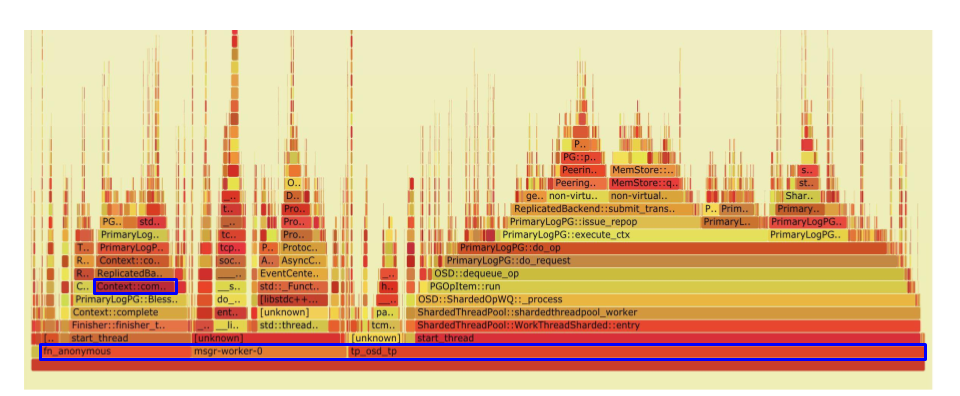
Here’s a flame graph of CPU usage within ceph-osd. The three blocks at the bottom are the entry points for threads from three of the groups above: the bluestore callback threadpool (fn_anonymous), the AsyncMessenger thread (msgr-worker-0), and the main OSD thread pool (tp_osd_tp).
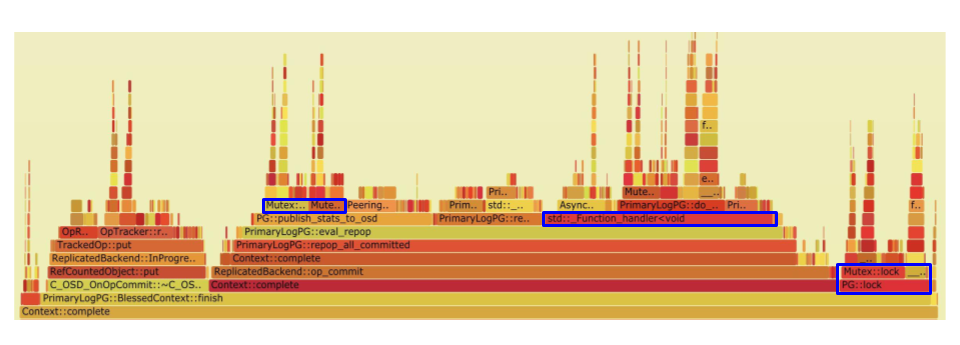
Drilling down a bit more into the Context::completion call we see that the bluestore callback spends quite a bit of time contending on locks.
Crimson
A core design goal of crimson given the overhead imposed by the concurrency design in classic ceph-osd is: as much as possible, permit a single IO operation to complete on a single core without context switches and without blocking if the underlying storage operations don’t require it. However, some operations will still need to be able to wait for asynchronous processes to complete, perhaps non-deterministically depending on the state of the system (due to recovery or something else) or the underlying device. We therefore still need some way of multiplexing concurrent requests onto a single core.
In order to make this easier, crimson makes use of a C++ framework originally developed for ScyllaDB called Seastar. Seastar generally pre-allocates one thread pinned to each core. The application is meant to partition work among those cores such that state can be partitioned between cores and locking can be avoided. With Ceph, this gives us a threading structure that looks like:
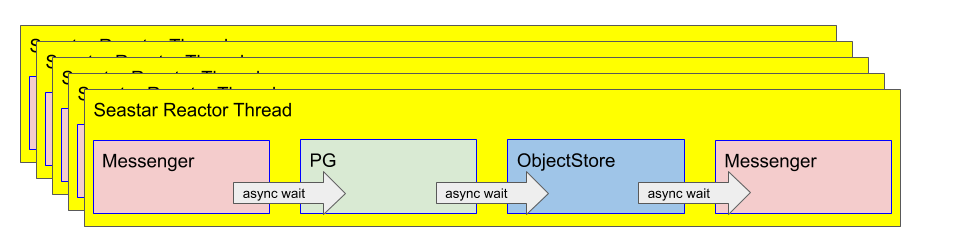
Rather than splitting the stages of performing an IO operation among different groups of threads, with seastar we partition IO operations among a group of threads based on the target object, but perform all of the pipeline stages within a single thread. If an operation needs to block, the core’s seastar reactor will switch to another concurrent operation upon which it can make progress.
Seastar offers a convenient programming model for expressing this kind of asynchronous logic based on a C++ implementation of futures. On the left, we have a (very simplified) version of the classic ceph-osd request handling loop. On the right, we have the same operations re expressed using seastar futures. The value returned by the repeat() call allows the seastar reactor to poll whether the process represented by this code is ready to run or is waiting. The reactor can switch among such tasks as they become ready to run or become blocked on IO.
On the left, we have a (very simplified) version of the classic ceph-osd request handling loop. On the right, we have the same operations re expressed using seastar futures. The value returned by the repeat() call allows the seastar reactor to poll whether the process represented by this code is ready to run or is waiting. The reactor can switch among such tasks as they become ready to run or become blocked on IO.
Status
We plan for crimson-osd to be a drop-in replacement for ceph-osd, eventually. However, because the programming model for crimson-osd is so radically different from classic ceph-osd, crimson-osd amounts to a rewrite of ceph-osd.
Our initial focus in 2019 was on building a proof of concept capable of performing basic IO operations to a memory backend through a seastar reimplementation of the Ceph messenger protocol. The result was that the crimson version was several times more CPU efficient per operation than classic-osd.
In 2020, our focus has been in two areas. First, round out the crimson-osd implementation to handle recovery, backfill, and scrub in order to enable failure testing. Second, create crimson compatible disk backends to enable actual workloads. As part of the latter effort, crimson can now run BlueStore. We’ve also begun work on a new ObjectStore implementation specific to crimson intended to work with next generation technologies like Zoned Namespace (ZNS) devices called SeaStore.
If you are interested in contributing, the current implementation can be found in the main Ceph Git repository.
You can also find a bit more information about crimson in this talk from Vault ‘20.