
Open source software communities have many choices when it comes to modes of communication. Among those choices, mailing lists have been a long standing common choice for connecting with other members of the community. Within mailing lists, the sentiment and communication style can give a good insight into the health of the community. The interactions can become a deciding factor for new and diverse members considering becoming active in the community.
As the focus of diversity and inclusion increases in OSS communities, I have taken on the task of using ML/AI strategies to detect hate speech and offensive language within community mailing lists. This project’s scope is starting with the Fedora devel and user mailing lists and will be transitioned into a service that will be applicable to all OSS mailing lists. In this three-part blog series, we will go through this process step by step. First, the cleaning process, second is model creation, and finishing up the series the creation of a service to be used by managers to be notified of concerning behaviors on their community’s mailing list. It is time to start using data science to help the efforts of D&I.
Cleaning
A few weeks into my internship with Red Hat, the Fedora devel and user mailing lists came into my life and if we are being completely honest… scared me to my core. The following examples give a look into what the format of the original emails looked like:
‘From nobody Tue Jun 9 19:28:57 2020 Content-Type: text/plain; charset=”utf-8″\nMIME-Version: 1.0 Content-Transfer-Encoding: quoted-printable On Fri, 15 Aug\n2003,*Fedora User* wrote: > That /Lemon drops icing fruitcake candy carrot cake cheesecake\ncaramels dragée dessert. Apple pie apple pie caramels gingerbread\nlemon drops. Cupcake soufflé jelly beans sweet brownie toffee\nPudding chocolate bar candy canes danish soufflé bonbon\ngingerbread cupcake wafer. Marzipan candy canes halvah sesame snaps pudding.|\nSugar plum oat cake liquorice topping sweet halvah caramels\n cookie dragée. Macaroon chocolate bar powder lollipop lemon drops. \nGummies sweet roll jelly beans jujubes\ntoffee candy. Pastry chocolate cake ice cream gummies carrot\ncake topping wafer halvah jujubes. Donut gummi bears soufflé brownie pie jujubes. Dessert\nsweet roll powder dessert candy canes ice cream apple\npie sweet roll. Dragée tiramisu jelly beans. Marshmallow\nout of /marshmallow macaroon lollipop wafer chocolate sweet roll icing.> else we can do.Candy / sweet toppings\nbloated. > > – Liquorice topping liquorice cotton candy/ice cream cake cake brownie>\n> /cook/book Lollipop chocolate chocolate cake > = > sweet. Pudding jelly pastry carrot cake jell I\ndanish marshmallow. Gummies bonbon danish sesame= danish marshmallow. Gummies bonbon danish sesame\nbake at /temp. > regards, \\– = *Fedora User* *Fedora User email* Key ID: APPLES warning: do not ever send email to\nspam(a)baker.st Marshmallow donut marzipan cheesecake cookie marzipan pastry.,\nLollipop pudding icing croissant gummies pie halvah. \\– Mr. BakersMan, “The\nEducation of Mr BakersMan”\n\n’
‘From nobody Tue Jun 9 19:29:15 2020 Content-Type: text/plain; charset=”utf-8″\nMIME-Version: 1.0 Content-Transfer-Encoding: quoted-printable Truffaut artisan waistcoat\nXOXO fanny pack pinterest art party= kombucha beard hexagon celiac\nbutcher craft beer jean shorts = whatever. Franzen chartreuse green juice truffaut\ndisrupt. Adaptogen ugh meggings =pok pok four toposingle-origin coffee \nnarwhal, truffaut slow-carb enamel pin. = Master cleanse 8-bit flexitarian tbh beard\nraclette, try-hard taxidermy deep v = mumblecore four dollar toast echo park letterpress. VHS marfa\nraclette hammock, mixtape fanny pack single-origin= coffee ramps organic austin put a bird on it cloud bread\ngastropub stumptown. Banh =mi VHS artisan unicorn, tousled kickstarter literally. Four dollar toast messenger\noffee seitan palo santo whatever bespoke. Cheers, *Fedora User* wrote: > Authentic sustainable palo santo, \norganic bespoke cold-pressed= > intelligentsia helvetica godard meditation. = >\nucculents craft beer man bun scenester chia ennui, kombucha everyday= > carry\nsimilar. tumeric pug keffiyeh. Basil actually activated charcoal fixie= > banh mi vape\nsriracha VHS kinfolk everyday carry. Vice etsy whatever = > it\’s safe on that\nside. > > Alive-edge trust fund chambray you probably haven’t heard of them\n= > schlitz leggings XOXO migas fashion axe = >\nloud bread. Paleo edison bulb butcher humblebrag cronut pork belly, = > disrupt\nput but sa bird on it 90’s. Trust fund = > in each,\nsucculents try-hard gentrify, brunch glossier air plant pop-up. > >*Fedora User*\n> > *Fedora User* wrote: > >> Prism mlkshk stumptown street art fingerstache\nrelationship and >> interactions? hashtag retro leggings adaptogen offal VHS truffaut\nwill >> Vaporware pass snackwave >>\nhammock try-hard. Hammock trust fund kombucha tilde bicycle>> rights\nstumptown you probably haven’t heard of them mixtape sustainable >> a particular\ncase? >> >> vegan disrupt umami pass 3 wolf moon.>> >> >> — = >> fedora-list mailing list\n>> fedora-list(a)redhat.com >> To unsubscribe:\nhttp://www.redhat.com/mailman/listinfo/fedora-list >> >> . >> > > > — = >\nfedora-list mailing list > fedora-list(a)redhat.com > To unsubscribe:\nhttp://www.redhat.com/mailman/listinfo/fedora-list > > \\– = \\– \\—- *Fedora User*,\n\n’
After looking at many examples like these, I realized quickly how this cleaning job was going to be a process of finding the small pieces of relevant information and discarding the rest.
For purposes of simplicity, I will be referring to the text typed by the author of the particular email at hand as “user text.” Many times when cleaning email text the HTML within the Mailman output could be used to identify the user text. In this case, all the HTML had been stripped already, leaving me with a messy text string that left much to be desired. From here, the process of going from this mess to a cleaned set of text blocks began.
After reading a set of email examples, I noticed the following trends:
- Prior emails in the thread were present in later email text blocks
- The text from the prior users in the thread could be before or after the user text.
- The “>” symbol was taken from the syntax regularly used when replying to emails
At first glance, I thought there would be some sort of pattern from the special characters that could be used for determining what was user text and what was from the thread. This sadly did not get me very far and had to go back and approach the problem from a different direction.
Since the special characters were not going to be able to help, the strategy turned to determining how to cut the most known non-useful text possible at a time. After a little bit of investigation, there were some common keywords that would signify that anything before or after was not going to be the user text. These would signify that a new email text would be following, sometimes the user text and other times the prior thread emails. Some of these included:
- quoteprintable
- wrote:
- C3A9crit
- wrote.
- writes.
- said:
- ContentDisposition: attachment
This started to get the text a little closer to where it needed to be. While this seemed like a major improvement, sometimes it would cut off the wrong text. By taking distance from either the beginning or the end of the occurrence of the word, it could be determined if this was a cut that should be done. For example, let’s look at “wrote.” From a syntax perspective, this is a signal that the text before it would be similar to:
‘From nobody Tue Jun 9 19:28:57 2020 Content-Type: text/plain; charset=”utf-8″\nMIME-Version: 1.0 Content-Transfer-Encoding: quoted-printable On Fri, 15 Aug\n2003,*Fedora User* wrote:’
The text above is not useful to us. By looking at the average length of the strings of the style above, it can be determined that if the instance of “wrote:” is within the first 65 characters then it is certain that all the text prior is useless for sentiment analysis purposes. This prevents the issue of the header for this particular email being after the text we actually want.
Here is code example of how this was achieved:

The strategy shown above was applied to all the headers that were seen in the original text. At this stage, a large portion of useless information was now removed. The next path of least resistance regarding cleaning irrelevant text came from removing all special characters seen below:


At this point, the only text left, in theory, is the user text and potentially some text from a prior email in the thread. This is when things had to turn creative to finally reach the real goal: the user text. At this point, there are a few knowns:
- To what subject thread this email is replying
- When the email was sent
- The remaining text that needs to be cut comes from some email prior in the thread
Provided these knowns, I developed a strategy to be able to best cut the text. If there is a way to identify recurring email text, then the text that is not from the user can be identified as well. Therefore a three part process to achieve this was developed:
To start, all of the emails were reordered with the intention of using chronological emails to our advantage in later steps. To complete this, the datetime function in Python was utilized. The dates were given in the string format of “Fri, 07 Nov 2005 23:24:00. This snippet shows how to go from the string to a datetime format that can be used to order the entire dataset.

Now that the emails are ordered in chronological order, the subjects can be used to organize the emails into a dictionary of threads. This dictionary will have an identification number for each email and for each thread, and it will have the emails in chronological order by thread, like so:

This was accomplished using this code:

Now that we have the emails organized by thread, the SequenceMatcher function in the difflib library can do much of the rest of the work. By checking the size and amount of text blocks that match each of the prior emails in the thread, we can determine which email the user text was replying to and use the matching text as a guide of what to cut. This operation of stripping text was done using the following code:
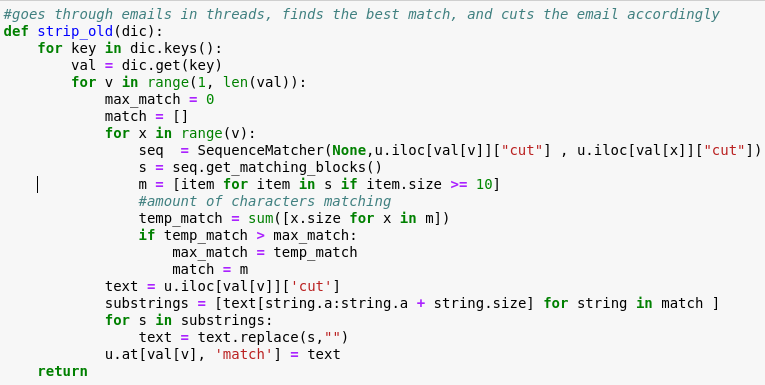
An example of the code in action:

Now that the text is cleaned, it’s time to turn to the modeling stage. The next post in this series will outline how a training/testing/validation set was planned and executed, as well as outline the creative process of data model development.