This is the third post in our series investigating how Rook-Ceph and RBD Mirroring can be best utilized to handle Disaster Recovery scenarios. The first post in the series, “Managing application and data portability at scale with Rook-Ceph,” laid some foundational groundwork for how Rook-Ceph and RBD mirroring can enable application portability. Then in our second post, “Managing Disaster Recovery with GitOps and Ceph RBD Mirroring,” we talked about some key features of Rook-Ceph RBD mirroring and presented a solution to help manage and automate failover using a GitOps model.
In this post we explore some additional tools and concepts to help with the synchronization of application consistency and state across multiple clusters, reducing the manual steps and providing an automated approach for recoverability and maintainability of the application on failover.
Most companies we work with today do not operate in a single cluster environment, nor do they have a single approach to maintaining application consistency across multiple clusters, but rather a range of tools, scripts, and other functions that are used in various capacities to achieve operational effectiveness. With all of these different choices, and the diverse and unique set of requirements that each application possesses it becomes difficult for a single tool to be adopted and used across all the different cluster and application environments.
In our previous posts we used Ceph RBD mirroring to maintain application state and portability showing that we could synchronize the application data across clusters (mirroring) and then move the application from cluster to cluster (GitOps). But for this to be successful, there were additional manual steps needed to keep the application state consistent. As with any manual process, there is potential for user error to be introduced. To address this problem, we wanted to investigate how we could reduce those manual steps and integrate automation into our solutions in a generic, pluggable way.
There’s more than one way to do it
There are multiple approaches to help automate tasks. Whether one uses streamlined pipeline tools like Jenkins and Tekton, or batch processing like Kubernetes Jobs, or some scripting technologies strung together, the goal remains the same, to alleviate manual steps and provide a consistent, well-defined, and repeatable workflow process.
There is no right or wrong answer when it comes to addressing this problem of application consistency. It really depends on your organization, application, and tools that you are comfortable with. For our disaster recovery use case, the steps we wanted to automate involved using three or four Ceph RBD commands that are needed to maintain proper application state and consistency when failing over an application to a new cluster.
Rook-Ceph provides a toolbox pod that can be invoked in Kubernetes and can run any Ceph command or a series of Ceph commands to completion. This feature of Rook-Ceph is the enabler needed to create the automation for the WordPress application state across clusters using a Kubernetes Job.
Jobs are flexible and pluggable and can be utilized straight from Kubernetes or Red Hat OpenShift or integrated into popular workflow tools like Jenkins, Tekton, and ArgoCD. For this example, we expanded on our previous architecture with ArgoCD as our GitOps Management tool and created a job that can be invoked when the failover occurs.
Once our application on Site A has failed and we initiate the process to bring it up on Site B, there are some key steps needed to keep the RBD Images in sync and consistent.
- Application stopped on Site A (GitOps/Mgmt Tool)
- Pipeline/Job Initiated (GitOps/Mgmt Tool triggering pipeline or Kubernetes job)
- The RBD images on Site B (Secondary) for consistency and if possible request Resync from Primary, which fetches latest data
- The RBD images on Site A (Primary) need to be demoted to Secondary
- The RBD images on Site B (Secondary) need to be promoted to Primary
- Application ported and started on Site B (GitOps)
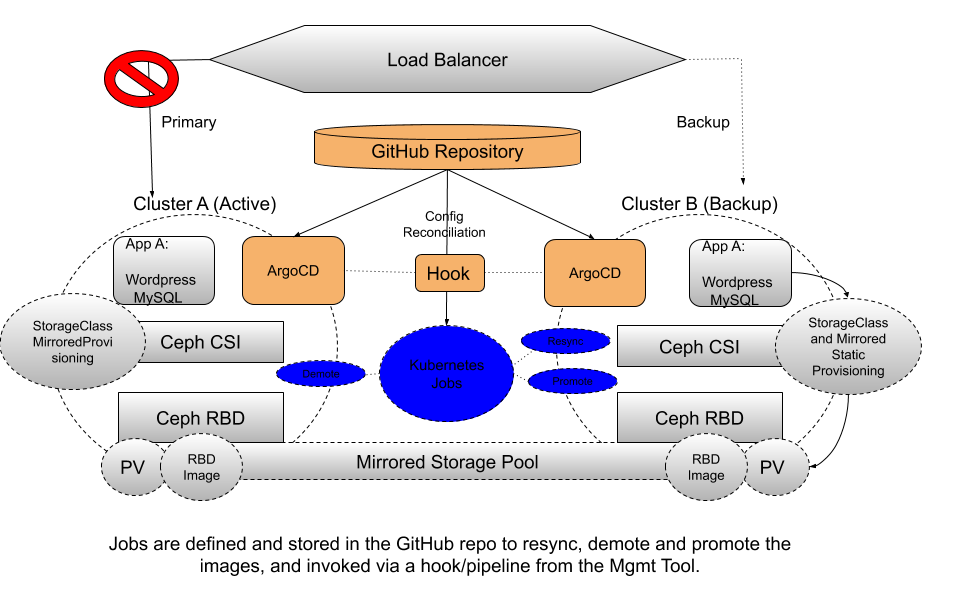
Regardless of what GitOps management tool is chosen (Tekton, ArgoCD, Jenkins), automation can be adopted or developed using a Kubernetes Job as the base. As we explored some of these techniques to help keep application and data state consistent, we have documented how to set this up on your own to try it out. Check out this repo for more examples and information, including examples using ArgoCD, Advanced Cluster Manager, Tekton, and Kubernetes Jobs. Happy Mirroring!