Red Hat’s AI Center of Excellence and PerceptiLabs wanted a way to demonstrate a TensorFlow model to the public during the 2019 Red Hat Summit. The plan was for this model to take images as input, and then respond with the likelihood of a Red Hat fedora being in that image. Here’s what we learned during Red Hat Summit.
This application, which we called Fedora Finder Bot, would be featured during Red Hat CTO Chris Wright’s keynote, where PerceptiLabs demoed their AI platform.
[youtube=https://www.youtube.com/watch?v=FUu4kMc0PL8&w=560&h=315]
Our initial solution for this objective would be a Twitter bot that receives tweets or direct messages and replies with the output from the TensorFlow model. Twitter being a public service, we felt it could make the model available to a large number of users, so that any user could just tweet to the bot with a picture and the bot would respond with the model’s output.
Building the Application
The application is divided into four separate OpenShift deployments:
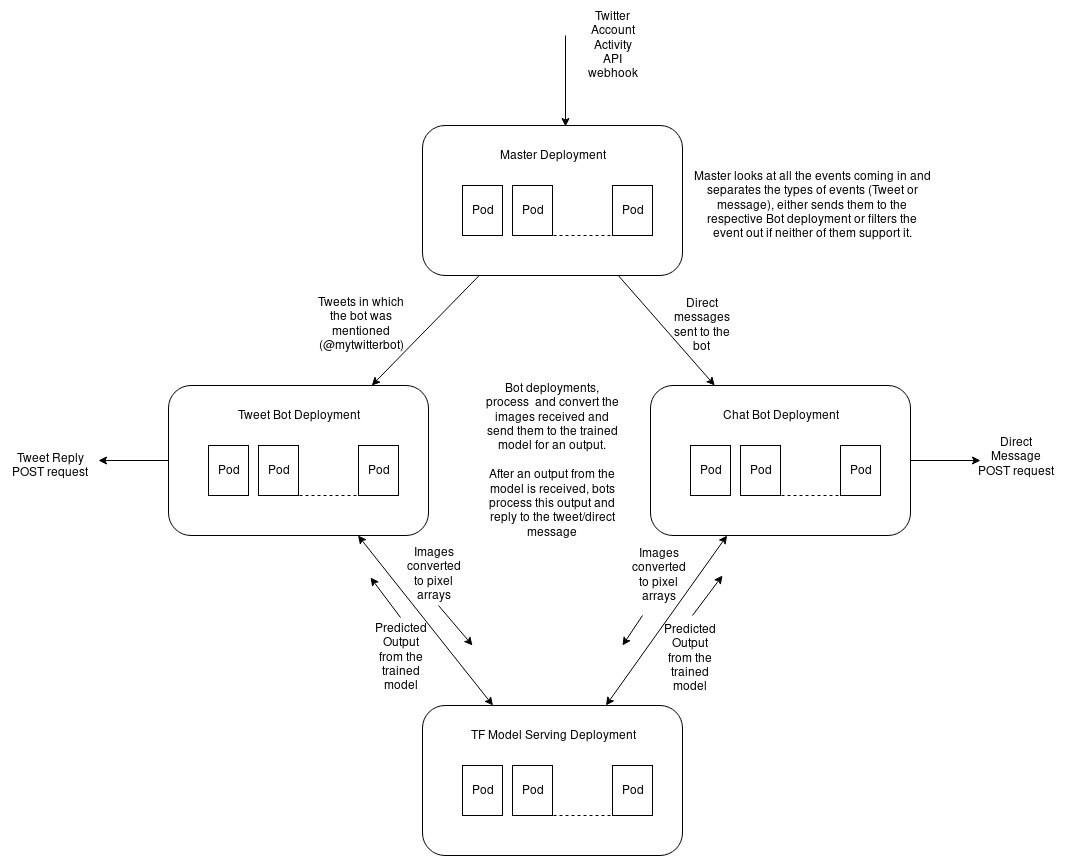
- The master deployment: The master hosts a webhook, to which Twitter sends events like tweets or messages. When the master receives a tweet/message event, it forwards a tweet/message object to the tweet/message workers.
- The tweet bot worker deployment: The tweet bot receives tweet objects from the master, downloads the image from the media URL present in the tweet object (obtained from Twitter’s servers), processes the image, and converts it to an RGB pixel array. It sends this array to the TensorFlow model serving deployment using its REST endpoint and then replies to the original tweet with the response received from the model.
- The chat bot worker deployment: This is very similar to the tweet bot deployment, but instead of tweet objects, the chat bot receives message objects from the master and replies to these direct messages with the response received from the model.
- The TensorFlow serving deployment: This is the deployment where the trained TensorFlow model is hosted. The chat/tweet bot workers send the RGB arrays (processed image data) to this deployment and this model responds with the model output using the REST endpoint of the TensorFlow model serving deployment.
In this application, the individual components are separate deployments so that each one can be individually scaled depending on the type of load being received. For example, if more users are using tweets to interact with the model instead of sending direct messages, the tweet bot deployment can be scaled up and given more resources and the chat bot deployment can be scaled down to save CPU/memory usage.
Example Usage
One issue we faced was needing a public-facing endpoint to communicate with Twitter. Pete Mckinnon helped me with that by deploying a Red Hat OpenShift Container Platform cluster on AWS. We deployed this bot on that cluster.
Some of the tools we used included:
- Tornado: Tornado is a Python web framework.
I used Tornado for communication between workers. This is what the chat bot and tweet bot workers used to receive requests from the master bots. This is because Tornado enables functions to be run asynchronously, so we could squeeze more performance out of the CPUs, which in turn saves money when hosting on a cloud provider like AWS. - Vegeta: During the keynote presentation, we were expecting a high number of tweets and messages, so it was important to load test the bot beforehand. With Vegeta, I sent requests in the form of fake tweets and messages to the bot and recorded the response time for these requests. The bot has a special load-testing mode when enabled, so it does not send any requests to the Twitter servers.
Future Improvements
If time permits, we would like to make improvements to the bot and add more features. One of the features that would be useful is support for reinforcement-learning models. How it would work is that after the bot has answered the original request (via tweet/message), the user should be able to provide feedback for the model, and this feedback should directly improve the model.
The current success of the model was demonstrated when our very own CEO Jim Whitehurst tried it out on Twitter.
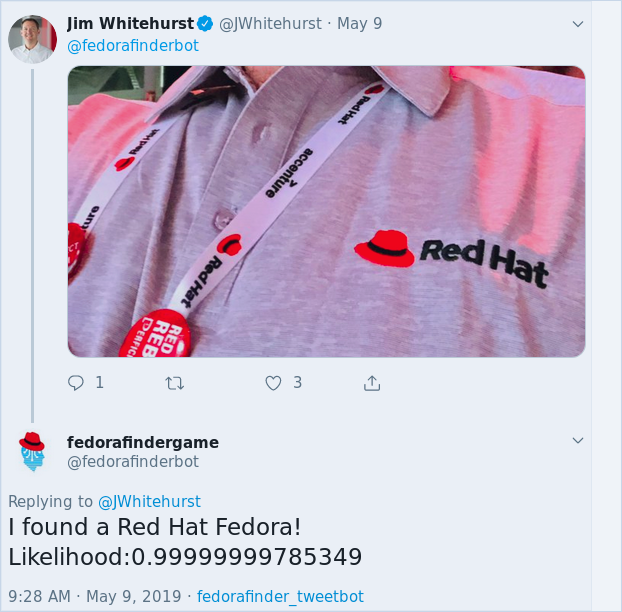
The demonstration bot deployment has been taken down since then, but you can try and deploy it yourself. We had fewer responses on Twitter than we hoped, but we learned quite a bit and hope that you’ll take the code for a spin and give us feedback.
Application Source:
- Bot component: GitHub – 4n4nd/twitter-tf-tweetbot
- Model serving component: GitHub – 4n4nd/oc-tf-model-serving
- Credits to Christoph Goern for an initial POC on a twitter bot: GitHub – goern/GPfingstrose
All Twitter account communication was done using the Twitter Account Activity API.