Experimenting with machine learning algorithms or integrating such techniques into an existing environment often presents challenges, like selecting and deploying the right infrastructure, in addition to having the necessary data science background and skills, etc. In this post, we present a service that allows users to train machine learning models, run analyses using trained models, as well as manage data required for such models or analyses. Now machine learning models or the prediction results can be easily integrated in to existing continuous integration (CI) or IT infrastructure using REST API.
Overview
The main components of such a service are Apache OpenWhisk, Red Hat OpenShift, and Ceph Storage. These components are available under AI Library at https://gitlab.com/opendatahub/ai-library. OpenWhisk is a serverless computing platform that provides the interface through which users can submit HTTP requests to train or execute machine learning models. HTTP requests submitted to OpenWhisk are actually targeted to stateless functions, called actions, that run on the platform. Ceph Storage is used for storage of training and prediction data, models and results. Users can submit data in to Ceph backend through OpenWhisk actions provided in our implementation (s3.py) or any custom tools such as RADOS object storage utility that can interact with Ceph storage. The action ‘s3.py’ not only supports Ceph, but also any S3-compatible storage backend.
We also provide OpenWhisk actions (service.py) to allow users to train machine learning models and perform analyses using the trained models and action (poll.py) to poll the status of the above machine learning tasks. Training machine learning models or running analyses using trained models are computation intensive and are carried out asynchronously as OpenShift jobs. Such jobs are triggered in a namespace or project different from that of OpenWhisk. This allows for better management of resource limits required by the OpenShift jobs. Polling the status is a lightweight task and is executed within the action itself. In addition to the above components, AI Library contains machine learning models and solutions for common software engineering use cases to allow for rapid prototyping of ideas, and ansible scripts to allow for easy deployment of the above mentioned services.
Figure 1 shows an overview of the end-to-end workflow of how a user would interact with the service and run machine learning models.

Figure 1. Overview
Prior to working with the models, users need to upload the necessary data set into the Ceph backend. Once data is uploaded, users trigger the actions specific to training models, or running trained models, or polling the status of the above tasks. Models executed via this service interact with Ceph storage to retrieve the required data as well as store trained models and results. Users can interact with the storage to retrieve the results.
Next, we demonstrate usage of the service with the help of a machine learning project called ‘Flake analysis’.
Flake Analysis as a Service
Flake analysis aims to identify flakes, or false positives, among test failures in a testing system that verifies pull requests. We show how the service is used to train the model and predict flakes on test failures using the trained model.
Training the Model
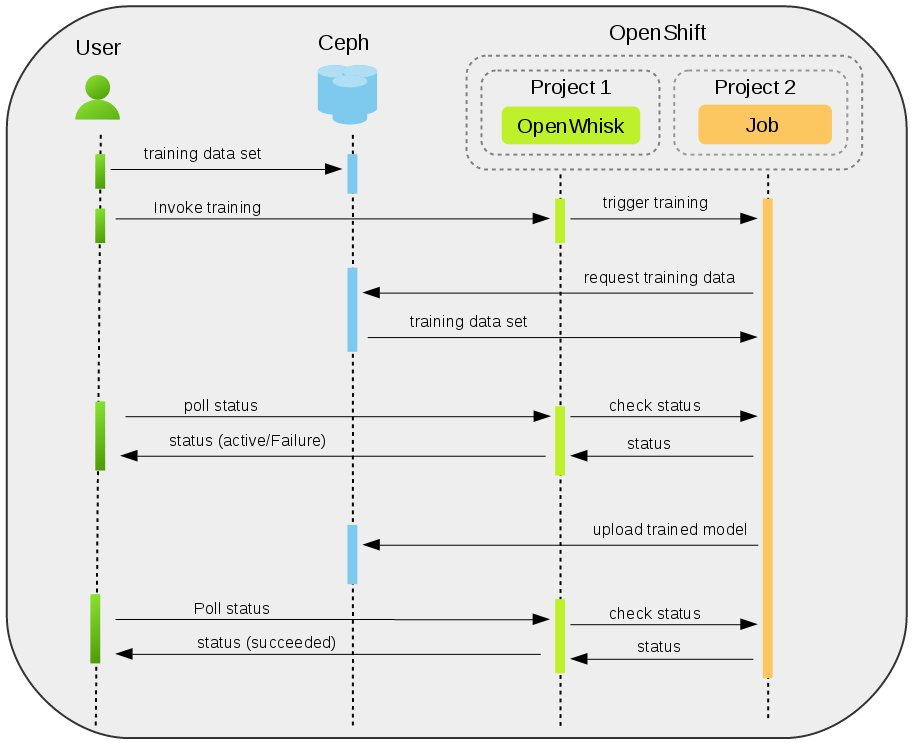
Figure 3. Training the model
Figure 3 shows the sequence of steps in training a model. The events will be described using relevant resources from the Flake Analysis project (REST APIs to carry out specific tasks are described in detail later in the “REST API – Data Storage” ). In the above repository, ‘train_model.py’ represents the code used to train a model and ‘predict_flakes.py’ represents the code to predict flakes given test failures. Users upload the training data set in to the Ceph backend using ‘mlservice’ and ‘ceph_storage.py’. Once the data upload is complete, users invoke training using the action ‘mlservice’ and ‘train_model.py.
Next, ‘train_model.py’ fetches the training data set from the Ceph backend and performs training of the model. While training is under progress, users invoke the action ‘poll’ to monitor the status of the training. Depending on the status of training, the result could either be ‘active’ – implying that the training is in progress, ‘failure’ – implying that the training failed, or ‘succeeded’ – implying that the training is complete and is successful.
Once the training is complete, the trained model is uploaded in to the Ceph backend at the location provided by the user. At this time, polling the status of the task yields the result ‘succeeded’.
Prediction Using the Trained Model
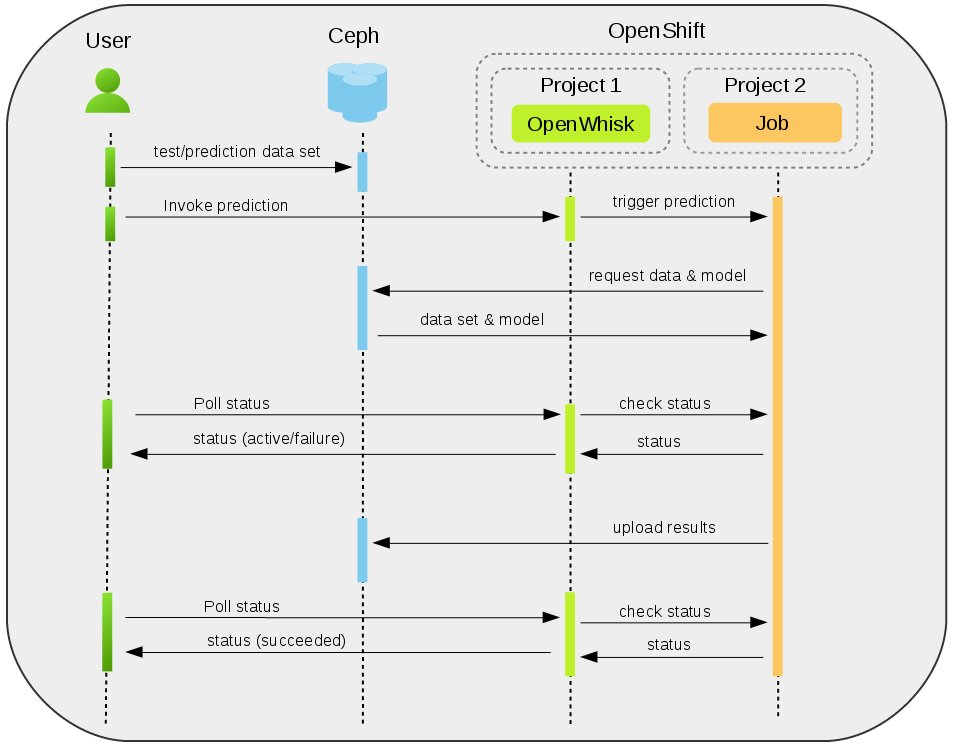
Figure 4. Prediction using the trained model
Figure 4 shows the events involved in executing the trained model for prediction. The steps are similar to the events involved in training a model. Note that users can either train their model using this service and then use the trained model for prediction, or can upload a trained model in to the Ceph backend and execute it directly.
In either case, users need to upload data sets they’ll run prediction tests against. Action ‘mlservice’ and code ‘predict_flakes.py’ is then used to perform prediction on the test failures data. Polling the status here would be done the same way we showed during training of a model.
Next, we describe in detail the REST APIs used to perform the events described in this and the previous section.
REST API – Data Storage
Figures 5 and 6 show the REST APIs (through the ‘curl’ command) for uploading data into Ceph backend during training and prediction phases. In these commands, ‘name’ indicates the name assigned to the corresponding OpenShift job that gets triggered (this is useful later to poll the status of the jobs), ‘app_file’ is the python code that needs to be executed to upload the data (‘ceph_storage.py’) and ‘app_args’ is the list of arguments passed on to ‘ceph_storage.py’. In the field ‘app_args’, parameters such as source file location (source), destination location in the Ceph storage, i.e, a subfolder within the Ceph bucket (destination), and Ceph storage access details (endpoint, access and secret keys, and bucket names) are provided.
Other fields such as ‘buildconfig_cpu’, ‘job_cpu’ etc. are build and job specific configurations required for the OpenShift job. ‘_cpu’ and ‘_memory’ refer to the numbers of cores and memory that need to be allocated for a job. In Figure 5 (training), the ‘app_args’ field refers to the training data set and in Figure 6 (prediction), the ‘app_args’ field refers to the test failures data set.
curl -u <auth> \
"https://<openwhisk-endpoint>/api/v1/namespaces/_/actions/ailibrary/mlservice?blocking=true&result=true" \
-X POST -H "Content-Type: application/json" -d \
'{
"token" : "<TOKEN>",
"name" : "data-storage",
"app_file" : "ceph_storage.py",
"docker_image" : "<docker image location>/pyspark-base-image:spark22python36",
"buildconfig_cpu" : "2000m" ,
"buildconfig_memory" : "2000Mi" ,
"buildconfig_git_url" : "https://gitlab.com/opendatahub/ai-library.git" ,
"app_args" : "-source=http://<address>/training_data.jsonl.gz -destination = data/flake/training_data.zip -s3endpointUrl=http://<address>:8080/ -s3objectStoreLocation=<Bucket-name> -s3accessKey= <ACCESS-KEY> -s3secretKey= <SECRET-KEY> -cockpitrepo=https://github.com/cockpit-project/cockpit.git" ,
"job_cpu" : "2000m" ,
"job_memory" : "2000Mi"
}'
Figure 5. REST API – Data Storage – Training a Model
curl -u <auth> \
"https://<openwhisk-endpoint>/api/v1/namespaces/_/actions/ailibrary/mlservice?blocking=true&result=true" \
-X POST -H "Content-Type: application/json" -d \
'{
"token" : "<TOKEN>",
"name" : "data-storage",
"app_file" : "ceph_storage.py",
"docker_image" : "<docker image location>/pyspark-base-image:spark22python36",
"buildconfig_cpu" : "2000m" ,
"buildconfig_memory" : "2000Mi" ,
"buildconfig_git_url" : "https://gitlab.com/opendatahub/ai-library.git" ,
"app_args" : "-source=http://<address>/test_data.zip -destination = data/flake/test_data.zip -s3endpointUrl=http://<address>:8080/ -s3objectStoreLocation=<Bucket-name> -s3accessKey= <ACCESS-KEY> -s3secretKey= <SECRET-KEY> -cockpitrepo=https://github.com/cockpit-project/cockpit.git" ,
"job_cpu" : "2000m" ,
"job_memory" : "2000Mi"
}'
Figure 6. REST API – Data Storage – Prediction
REST API – Training and Prediction
The REST APIs for training and prediction (Figures 7 and 8) follow a structure similar to data upload since the same action ‘mlservice’ is used here. In case of training (Figure 7), ‘app_file’ would point to ‘train_model.py’ and in case of prediction (Figure 8), ‘app_file’ would point to ‘predict_flakes’.py. Similarly, the data set (source in ‘app_args’) would refer to the training data set or the test failures data set from the Ceph backend. For training and prediction, the appropriate cpu and memory configuration can be selected through ‘job_cpu’ and ‘job_memory’ fields. In this example, the job is configured with 8 cores and 16GB memory.
curl -u <auth> \
"https://<openwhisk-location>/api/v1/namespaces/_/actions/ailibrary/mlservice?blocking=true&result=true" \
-X POST -H "Content-Type: application/json" -d \
'{
"token" : <TOKEN>,
"name" : "flake-analysis",
"app_file" : "train_model.py",
"docker_image" : "<docker-image-location>/pyspark-base-image:spark22python36",
"buildconfig_cpu" : "2000m" ,
"buildconfig_memory" : "2000Mi" ,
"buildconfig_git_url" : "https://gitlab.com/opendatahub/ai-library.git" ,
"app_args" : "-source=data/flake/05292018/test-learn2.jsonl.gz -s3endpointUrl=<address>:8080/ -s3objectStoreLocation=<Bucket-name> -s3accessKey=<ACCESS-KEY> -s3secretKey= <SECRET-KEY> -cockpitrepo=https://github.com/cockpit-project/cockpit.git" ,
"job_cpu" : "8000m" ,
"job_memory" : "16000Mi"
}'
Figure 7. REST API – Training
curl -u <auth> \
"https://<openwhisk-location>/api/v1/namespaces/_/actions/ailibrary/mlservice?blocking=true&result=true" \
-X POST -H "Content-Type: application/json" -d \
'{
"token" : <TOKEN>,
"name" : "flake-analysis",
"app_file" : "predict_flakes.py",
"docker_image" : "<docker-image-location>/pyspark-base-image:spark22python36",
"buildconfig_cpu" : "2000m" ,
"buildconfig_memory" : "2000Mi" ,
"buildconfig_git_url" : "https://gitlab.com/opendatahub/ai-library.git" ,
"app_args" : "-source=data/flake/05292018/test-learn2.jsonl.gz -s3endpointUrl=<address>:8080/ -s3objectStoreLocation=<Bucket-name> -s3accessKey=<ACCESS-KEY> -s3secretKey= <SECRET-KEY> -cockpitrepo=https://github.com/cockpit-project/cockpit.git" ,
"job_cpu" : "8000m" ,
"job_memory" : "16000Mi"
}'
Figure 8. REST API – Prediction
REST API – Poll Status
curl -u <auth>
"https://<openwhisk-location>/api/v1/namespaces/_/actions/ailibrary/poll?blocking=true&result=true" \
-X POST -H "Content-Type: application/json" -d \
'{
"token" : <TOKEN>,
"jobname" : "flake-analysis"
}'
Figure 9. REST API – Poll Status
Figure 9 shows the REST API structure for polling the status of a job (either training, prediction, or the data storage). The structure is simple as only the appropriate job names are required to request the status. The different status responses (active, failure, and succeeded) are shown in Figure 10.
{
“status”:
{
“active” : 1,
“startTime” : “2018-08-03T02:41:12Z”
}
}
{
“status”: “Failure”
}
{
"status":
{
"completionTime":"2018-08-09T02:40:00Z",
"conditions":
[
{
"lastProbeTime":"2018-08-09T02:40:00Z",
"lastTransitionTime":"2018-08-09T02:40:00Z",
"status":"True",
"type":"Complete"
}
],
"startTime":"2018-08-09T02:38:55Z",
"succeeded":1
}
}
Figure 10. Poll Status Responses
AI-Library enables users to work with machine learning models without worrying about infrastructure issues, model complexity or any data science expertise. In this article, we have shown how one can utilize AI-Library and experiment with machine learning techniques through simple REST APIs. Additionally, AI-Library provides the automation to deploy the AI-Library on a existing OpenShift cluster. We encourage users to experiment with machine learning models provided in the AI-Library, and to contribute to the project and help grow the community.