
In our previous blog, Managing application and data portability at scale with Rook-Ceph, we talked about some key features of Rook-Ceph mirroring and laid groundwork for future use case solutions and automation that could be enabled from this technology. This post describes recovering from a complete physical site failure using Ceph RBD mirroring for data consistency coupled with a GitOps model for managing our cluster and application configurations along with an external load balancer all working together to greatly minimize application downtime.
This is done by enabling a Disaster Recovery (DR) scenario where the primary site can failover to the secondary site with minimal impact on Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO).
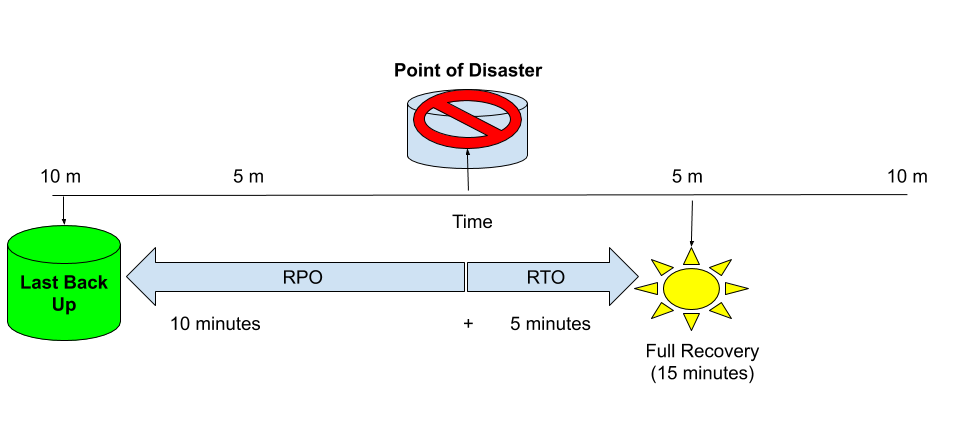
RPO is a metric for defining the amount of acceptable data loss before an application and business is impacted. RPO is typically defined from the point of the disaster to the last known backup or recovery point.
RTO, on the other hand, defines the amount of time that an application can be down before it significantly impacts the business. This typically is set based on the amount of time and steps needed from the point of failure, to the point of successful recovery by bringing the application back on-line.
Acceptable RPO and RTO depend on the application and level of critical business impact it may have on the users of the application. RPO and RTO working together form a window of time, for example, if our last backup is 10 minutes old from the loss event (RPO) and it takes 5 minutes from the loss event to fully recover the application and data (RTO), then our outage window is 15 minutes.
In the previous blog post we talked about Ceph RBD mirroring to handle application portability with continuous data replication between our primary and secondary sites, which looked like the following diagram.
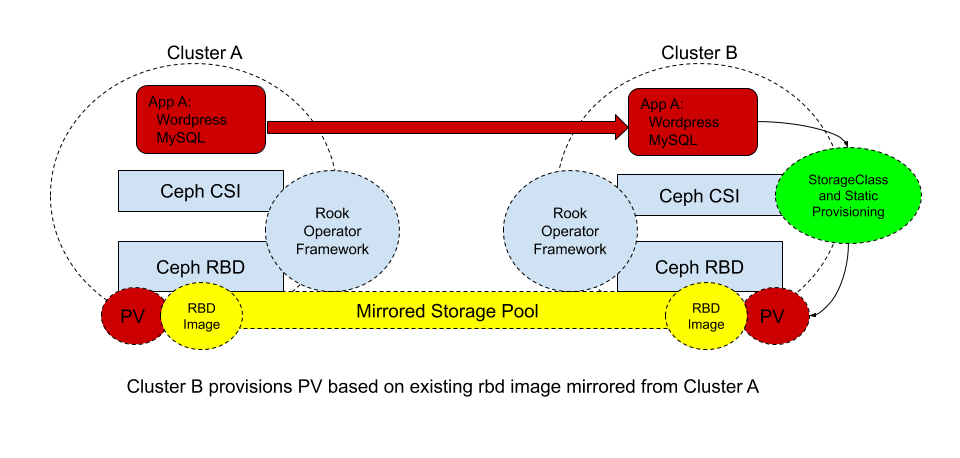
Building on that solution, we now expand on this architecture to add in ArgoCD as our cluster and application configuration manager utilizing a GitOps model as well as an external load balancer to direct traffic flow from Cluster A to Cluster B.
ArgoCD is a GitOps Continuous Integration (CI) tool that uses a Kubernetes application controller that performs reconciliation between actual state of the applications versus desired state of the applications. In this example we keep our WordPress and MySQL configurations in GitHub and as we commit a change in GitHub, it is detected, and triggers the ArgoCD controller to take action. This allows us to easily change configurations between clusters (i.e. bring Cluster A app down, and bring Cluster B app up).
We will also utilize an external load balancer. This load balancer can be either a load balancer available on-premise or it can be a load balancer offered as a Global Load Balancer from various vendors. This load balancer is required to route traffic between the two clusters depending on where the application is running.
The new architecture with the failover components looks like below:
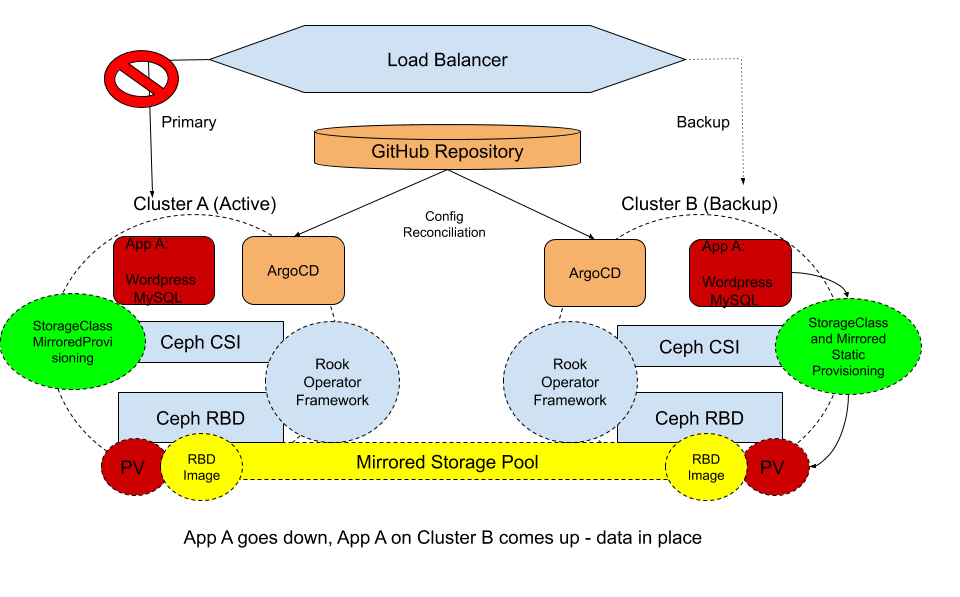
In this scenario, Cluster A has an active application running, the load balancer is monitoring the application and detects when it goes down.
The RBD images are mirrored between both clusters for data consistency. RBD mirroring supports two types of replication:
- Journal based continuous replication (default) – meaning data is continuously synchronized between the peers of the storage pool
- Snapshot based replication – meaning a snap of the image is taken (point in time) which can be scheduled down to 1 minute.
The Kubernetes StorageClass is using the RBD CSI provisioner that creates a PersistentVolume based on the mirrored image.
And lastly the ArgoCD controller is monitoring for configuration changes in the application.
When the application running on Cluster A goes down, it is detected and the application is brought up on Cluster B by manually triggering a configuration change in the Git repository. The RBD images will need to be promoted to primary on Cluster B and demoted on Cluster A, and the traffic for the application is redirected to Cluster B by the load balancer, resulting in minimal application down-time.
As stated, this solution is a proof-of-concept created to help show-case possible use case scenarios and features of DR using a Gitops + Rook-Ceph RBD mirroring model.
The steps to accomplish the failover are quite manual at this point but as this solution evolves and matures there are points of automation that could be implemented. Also, setup for this solution is minimal and the component architecture is quite clean in its simplicity (not overly complex) which makes it an attractive solution for Disaster Recovery and Application Portability. Want to try it out? Check out this link for instructions on how to implement this solution on your own.